Vision Transformer:畳み込み演算を用いない最新画像識別技術
ailia SDKで使用できる機械学習モデルである「Vision Transformer(以下、ViT)」のご紹介です。
ailia SDKはエッジ向け推論フレームワークであり、ailia MODELSに公開されている機械学習モデルを使用することで、簡単にAIの機能をアプリケーションに実装することができます。
ViTの概要
ViTは、大手Googleの研究部門であるGoogle Researchが発表した、畳込み演算を用いない最新画像識別技術です。
スタンフォード大学が公開する、著名な画像識別コンペティションのIMAGENETにて、最高位の精度を記録しています。
画像識別とは、画像に写り込んでいる対象を予測するタスクとなります。
IMAGENETでは、1,000もの識別種類がある画像50,000枚に対して、予測の正解率を競う形となっています。
つまり、正解率0.1%の問題を50,000個答える形なのですが、ViTの識別精度が90%超の正答というので驚きです。
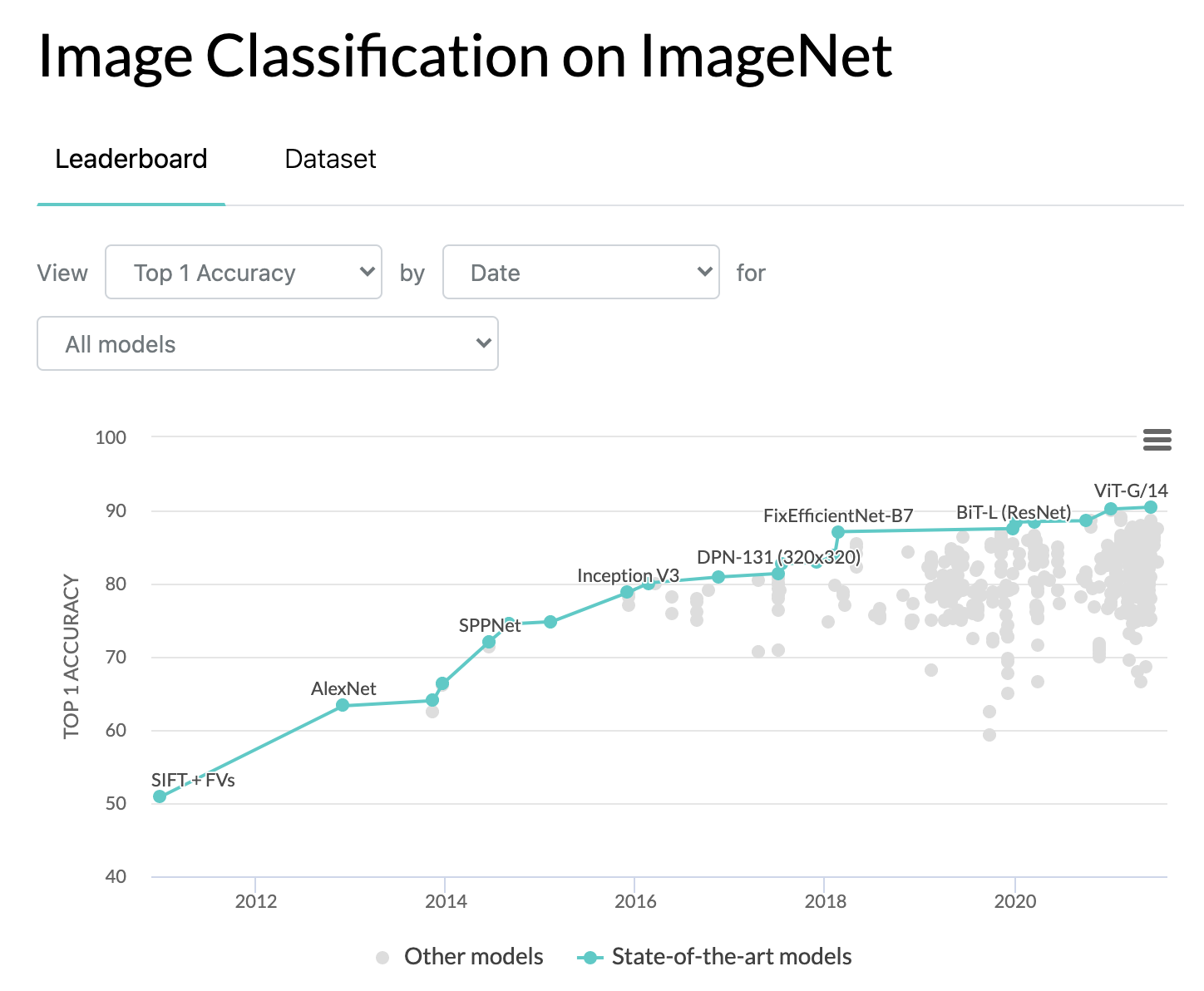
出典:https://paperswithcode.com/sota/image-classification-on-imagenet(2021年7月時点)
ViTの公開時期は、論文の第一版が2020年10月、プログラムはその少し前であるようです。
近年の画像識別で言えば、畳み込み演算を用いたConvolutional Neural Netwrkが、精度上位ランキングの常連でした。
しかし、Vision Transformerは、畳み込み演算を用いずに最高位の精度を記録しているということで、その新規性に注目が集まっています。
また、Transformerという技術は元々、画像処理分野でなく、自然言語処理分野にて、Google Researchが提案した手法となります。
つまり、自然言語処理にて用いられていた技術が、画像処理に転用された形となります。
ViTのアーキテクチャ
論文に紹介されているViTのネットワーク構成は以下となっています。
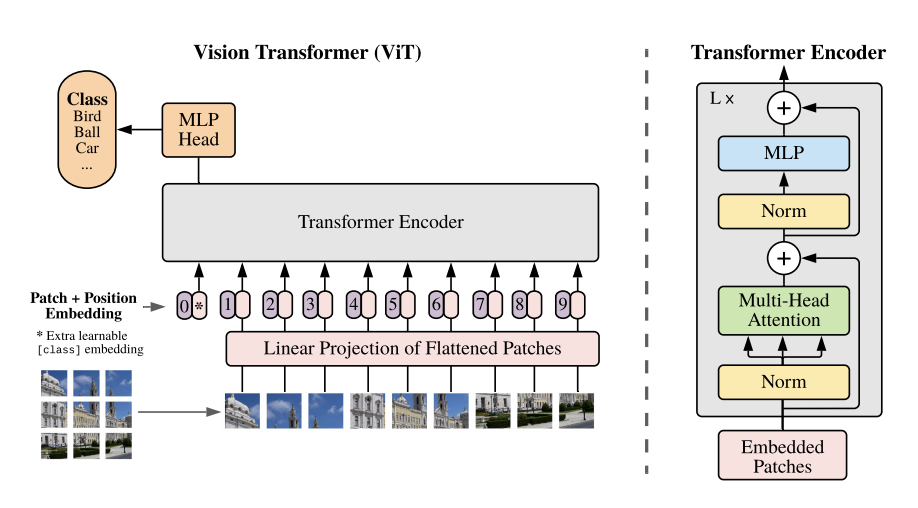
出典:https://arxiv.org/pdf/2010.11929.pdf
大まかに流れを追うと、以下となります。
(1)画像をグリッド上に、バラバラに分割する
(2)(1)を重ね合わせた上で、輝度が格納されている縦横ピクセルの2次元配列を、1次元配列へとベクトル変換する
(3)(2)に対して、class token、position embeddingと呼ばれる調整可能な組み込み特徴を付与する
(4)(3)に対して、Transformer Encorderによる計算処理を、複数回実施する
(5)(4)で生成された特徴を用いて、1,000クラスの対象に対するsoftmax score(≒確率値)を計算する
以上です。
尚、ここで面白い事実があり、論文には上記説明がされているものの、Google Researchが発行するGithubリポジトリでは、(1)について、実は異なる処理が行われています。
その該当箇所の処理コードは、以下となります。
(※2024/2/11、元リポジトリ変更に伴い、リンクアドレスを修正)
実際に行われていることは、以下です。
(1’)16x16などの大きめの畳込みフィルタで、ストライド幅16などの大きめの間引きをしながら、高圧縮畳み込み演算を行い、それをバラバラ画像の重ね合わせの代わりとする
プログラムのコード上にも、以下のコメント記載があります。
# We can merge s2d+emb into a single conv; it's the same.
x = nn.Conv(
features=self.hidden_size,
kernel_size=self.patches.size,
strides=self.patches.size,
padding='VALID',
name='embedding')(
x)
その為、具体的に行われていることを図示すると、以下のようになります。
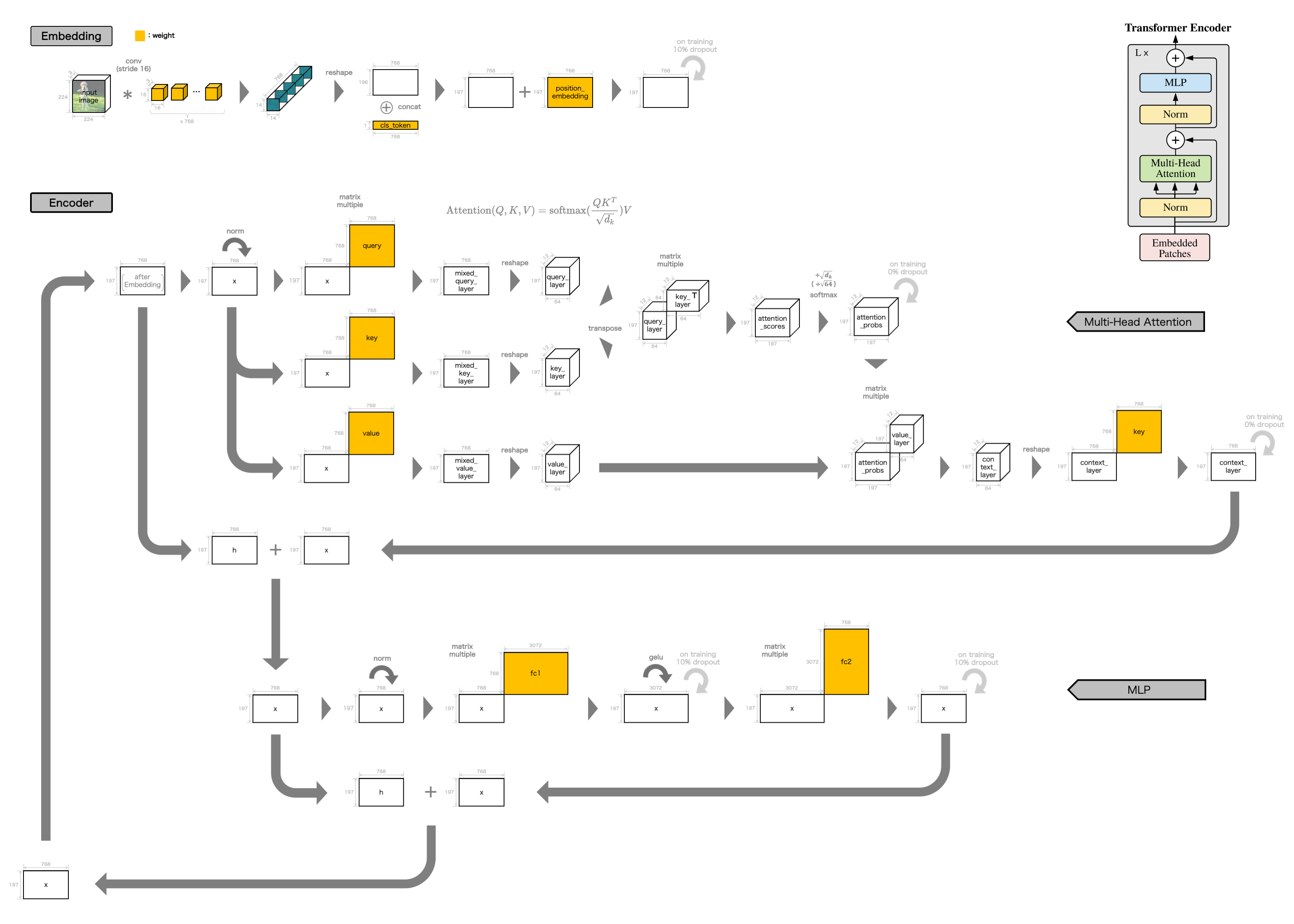
画像の出典:https://pixabay.com/photos/labrador-retriever-dog-pet-labrador-6244939/
Embedding処理の冒頭が、高圧縮畳み込み演算になっている形です。
入力画像と、高圧縮畳み込み特徴の配列変数のサイズは、以下となります。
入力データのshape : [1, 3, 224, 224] # Batch, Channel, Height, Width
畳み込み特徴のshape:[1, 768, 14, 14] # Batch, Channel, Height, Width
可視化すると、以下のようになります。
左上が元画像で、それ以外が高圧縮畳込み特徴768枚の内の19枚となります。

上記処理フローにおけるEmbeddingは、1度だけ実施されるものです。
一方、Encoderは複数回実施されます。
Encoderの出力が、再度入力へと合流している図の表現は、そういう意味になります。
Encoderで行われていることは、上段がSelf Attentionと呼ばれる処理、下段が一般的な多層パーセプトロン処理(以下、Multi Layer Perceptronの頭文字を取ってMLP)となります。
そして、この2つを繰り返し行う構成が、ViTにおけるTransformer Encoderとなります。
尚、Attentionにおいて実現されている計算の意味合いについては、以下の記事が分かりやすいので、参照下さい。
複数回のEncoder処理を繰り返した後は、処理を経て生成された特徴を用いて、一般的なsoftmax出力のMLPを行い、ネットワーク出力が完了します。
ViTが実装されている各種リポジトリの紹介
若干本筋からは外れますが、Github上に公開して頂いているViTのリポジトリは幾つか存在し、それぞれに特徴がある為、紹介させて頂こうと思います。
先ず、以下のgif動画が直感的に分かり易い、lucidrainsさんのvit-pytorchリポジトリです。
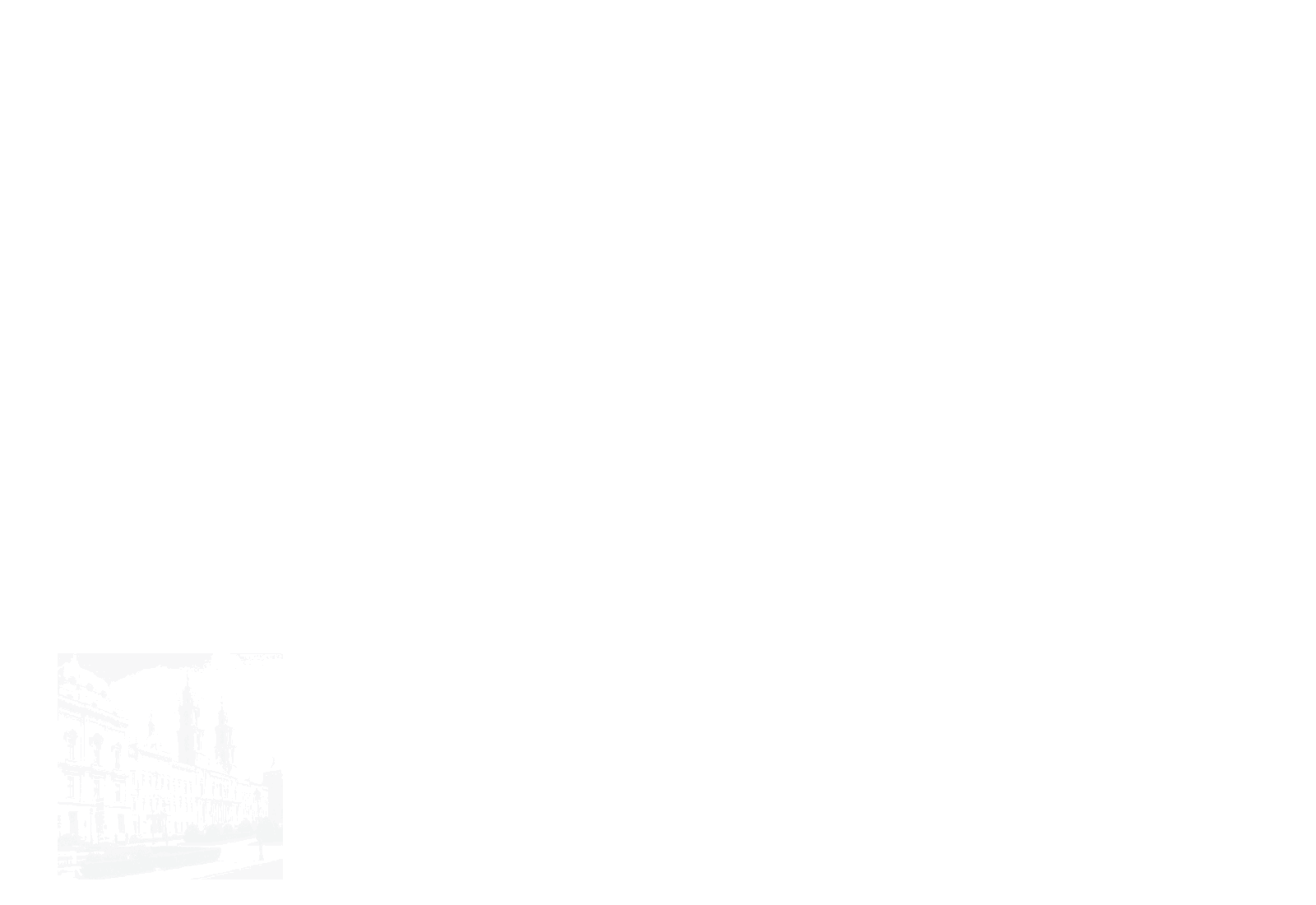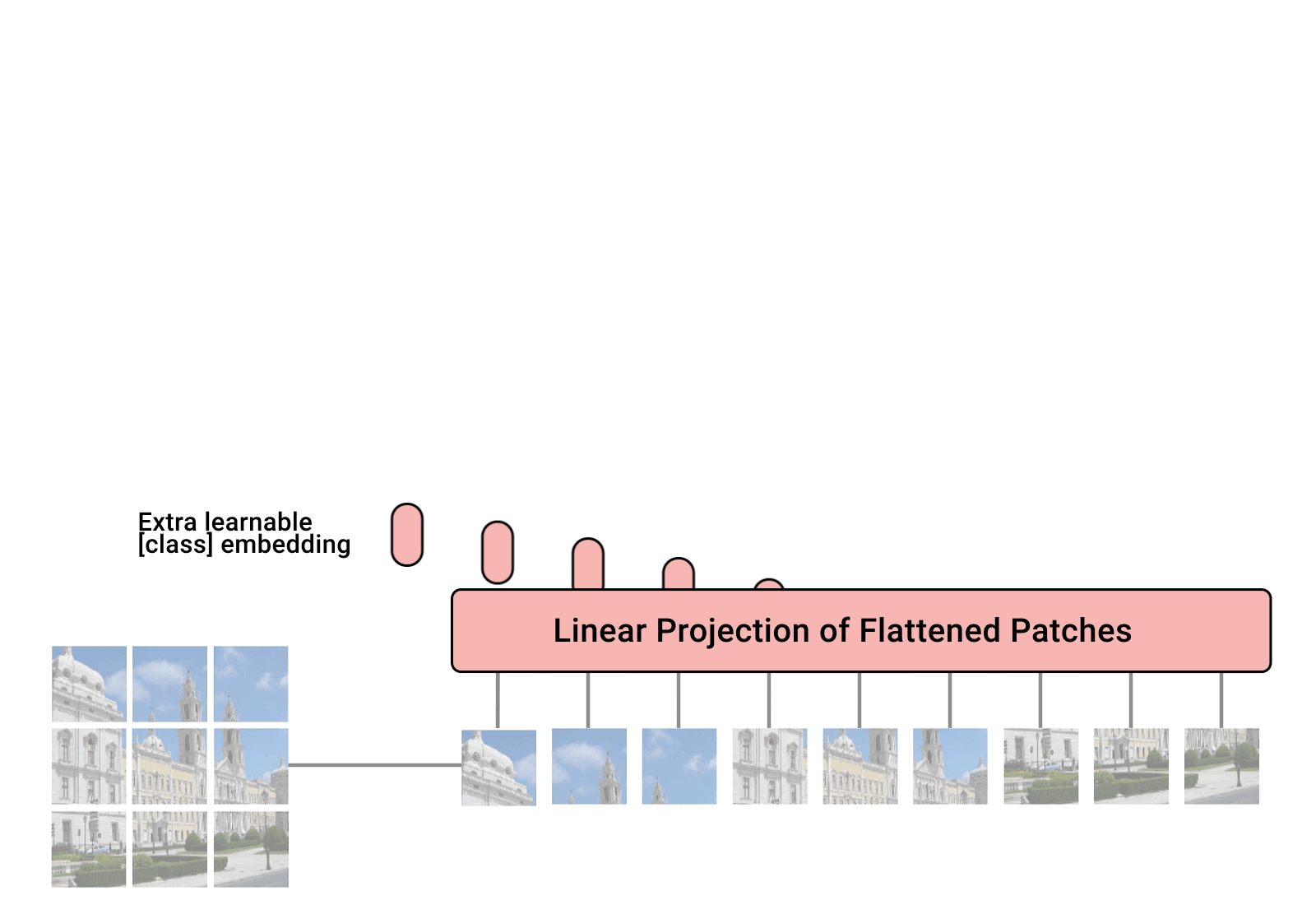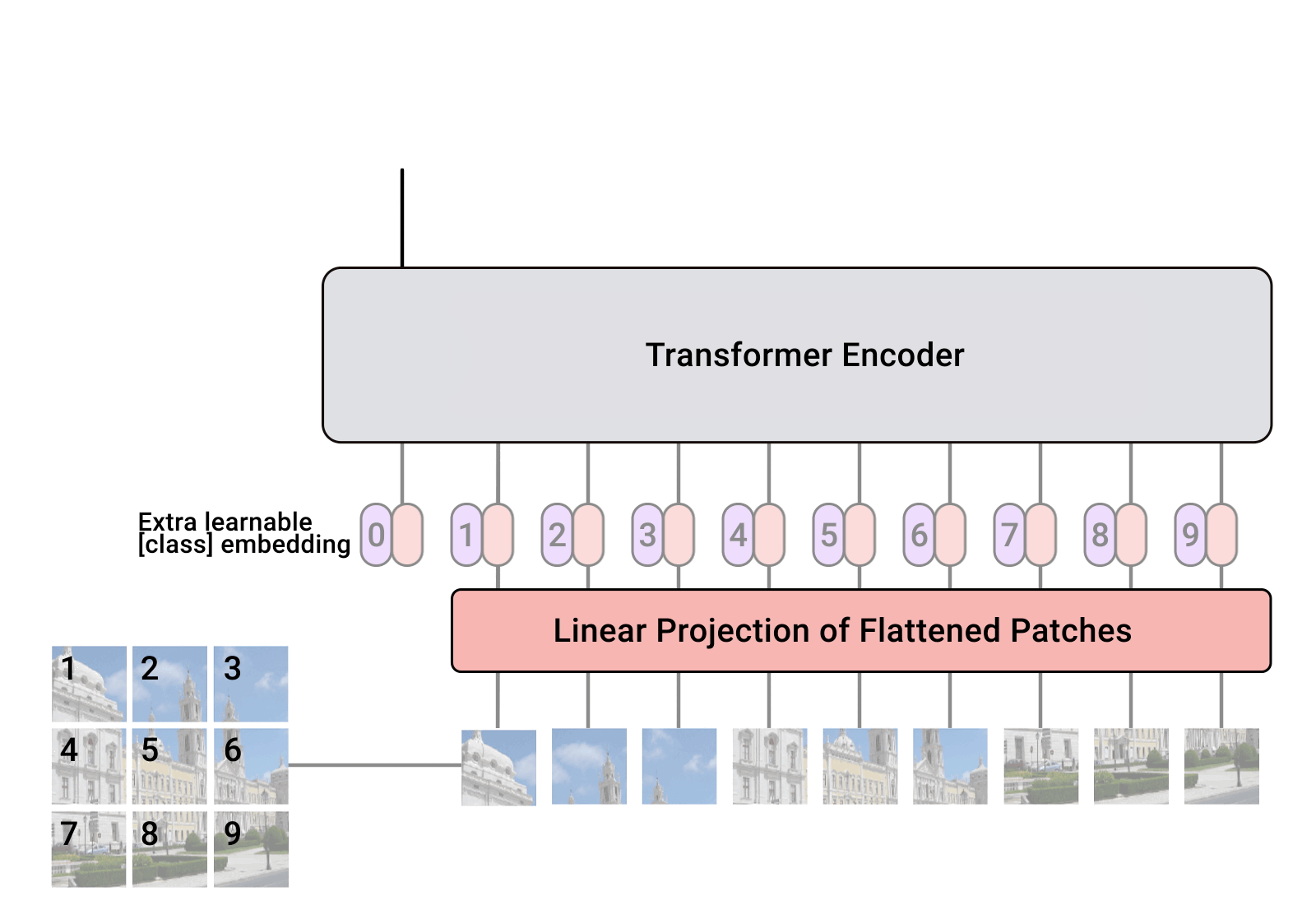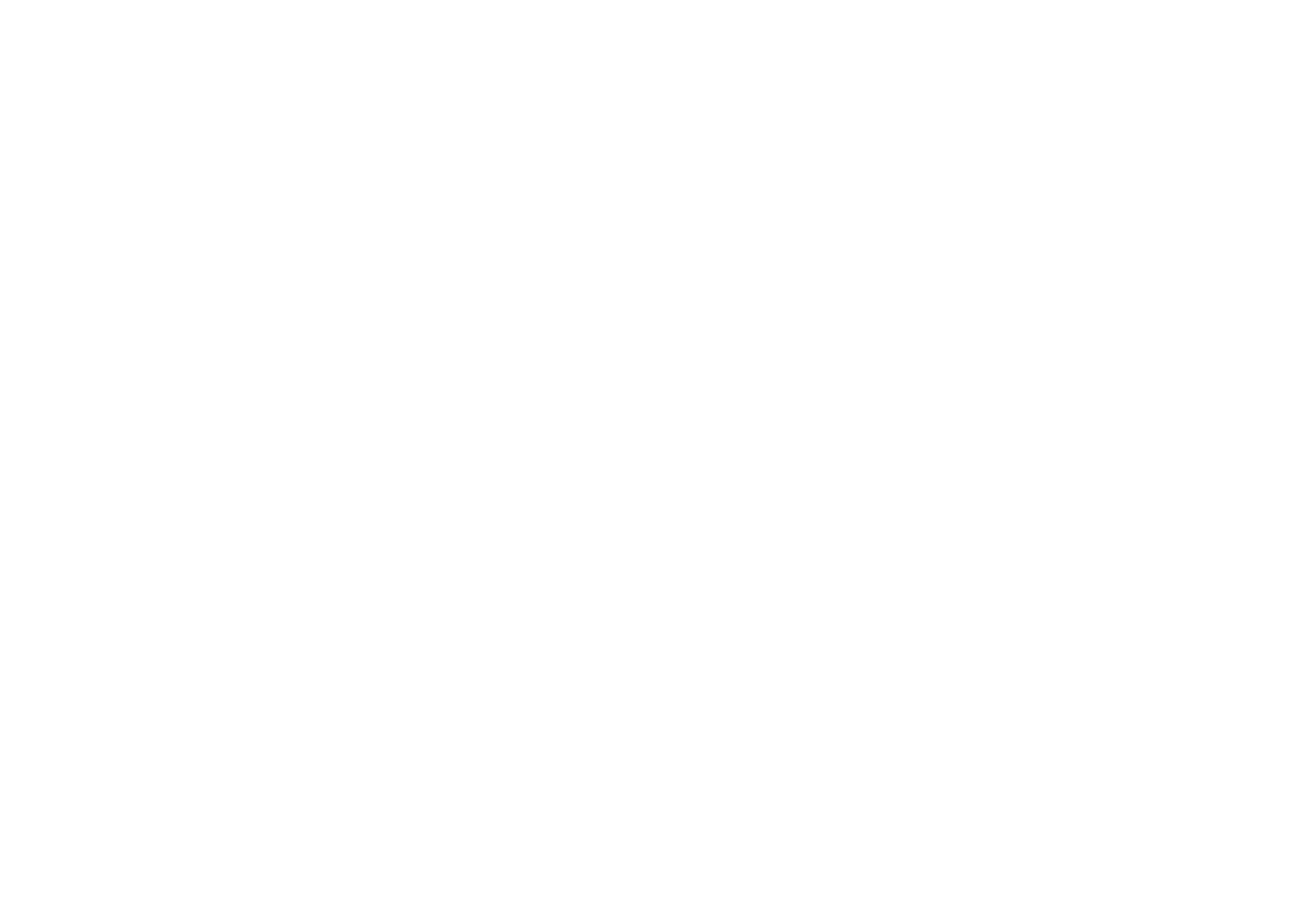
Google Researchによるofficialリポジトリが、JAXでの実装であるのに対して、こちらのリポジトリはpytorchでの実装となっています。
pytorchが好きな方は多いかと思いますので、非常に有り難い次第です。
その為か、リポジトリに対するイイネ評価である「☆Star」の数は、officialよりも多くなっています。
こちらのリポジトリは、論文の通りにEmbeddingを行っています。
つまり、以下の処理は言葉の通りとなっており、本当に一度も畳み込み演算を用いていない形となっています。
(1)画像をグリッド上に、バラバラに分割する
その為、論文実装を純粋に再現したい場合に、重宝するリポジトリとなるかと思われます。
しかし、明示的に事前学習モデルが用意されていない為、学習データを自分で用意した上で、1から学習を実施する必要があります。
或いは、officialリポジトリにて用意されているJAXでの学習済みモデルを、pytorchへとconvertする必要があります。
次に、「☆Star」の数はそこまで多くないですが、非常に緻密に実装がされているlukemelasさんのPyTorch-Pretrained-ViTです。
こちらのリポジトリもpytorch実装となっているのですが、主たるコンセプトは、Google Researchのofficialリポジトリが用意している事前学習済みモデルを、pytorchへと変換することになっています。
JAX上での各種事前学習済みモデルの重み値を、pytorchにて実装された汎用的なViTモデルに、convertをしつつ挿入していく形となっています。
最後に、attention mapの実装までがされている、jeonsworldさんのViT-pytorchリポジトリです。
基本的にofficialリポジトリと同様のアルゴリズムが、pytorchにて実装されている上で、特定の学習済みモデルのconvertをしつつ、処理を行う形となっています。
かつ、それらを可視化しつつ一連実施してくれるnotebookも用意がされていますので、とても親切です。
以下は、そのnotebookの出力結果となります。

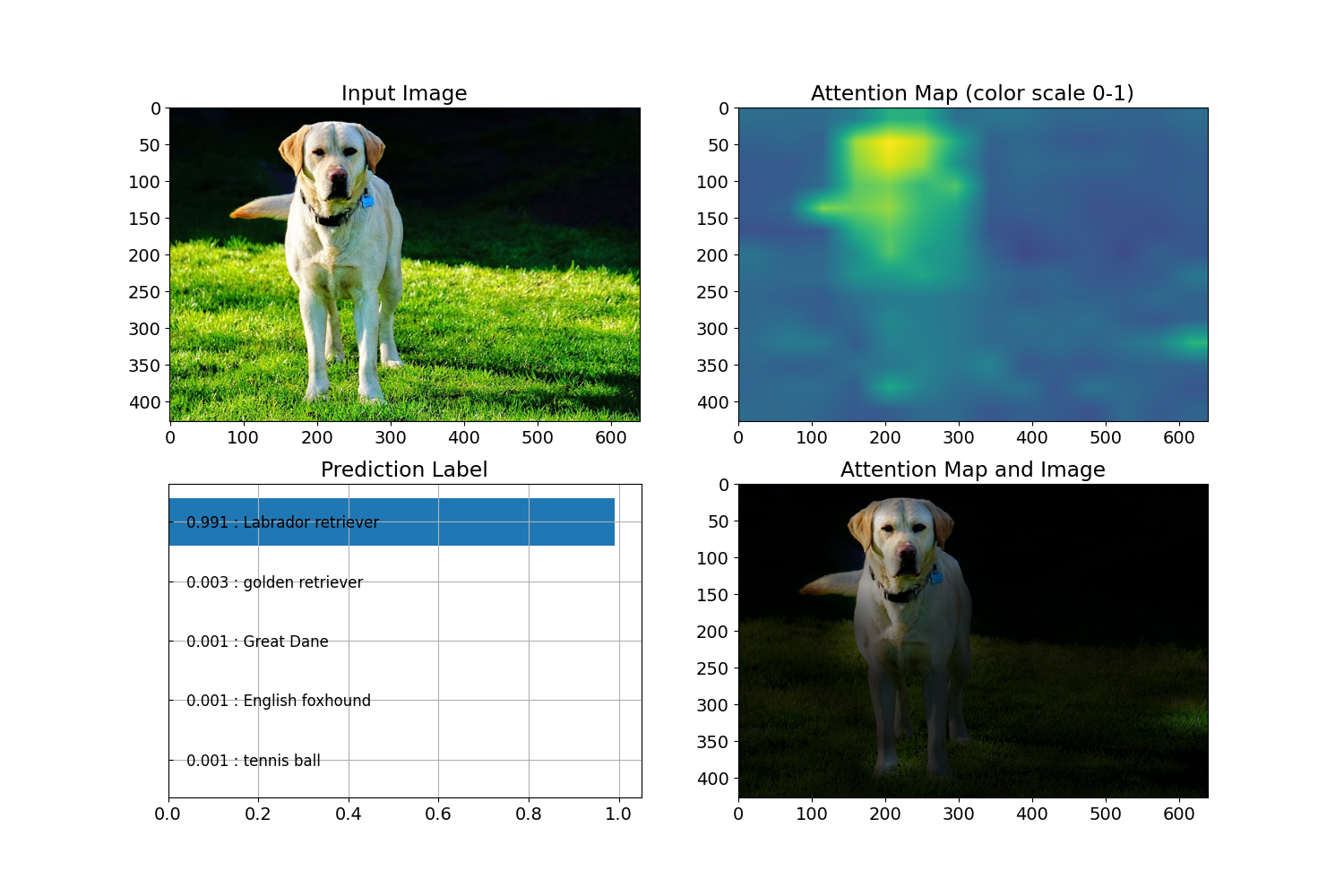
識別を行ってくれた上で、判断の根拠とならない箇所を、暗くするようなattention mapの可視化もしてくれています。
このattention mapの実装は、Google Researchのofficialリポジトリにも搭載されておらず、jeonsworldさんが以下リポジトリから踏襲したもののようです。
attention flowの論文と、論文中に記載される概念図は、以下となります。
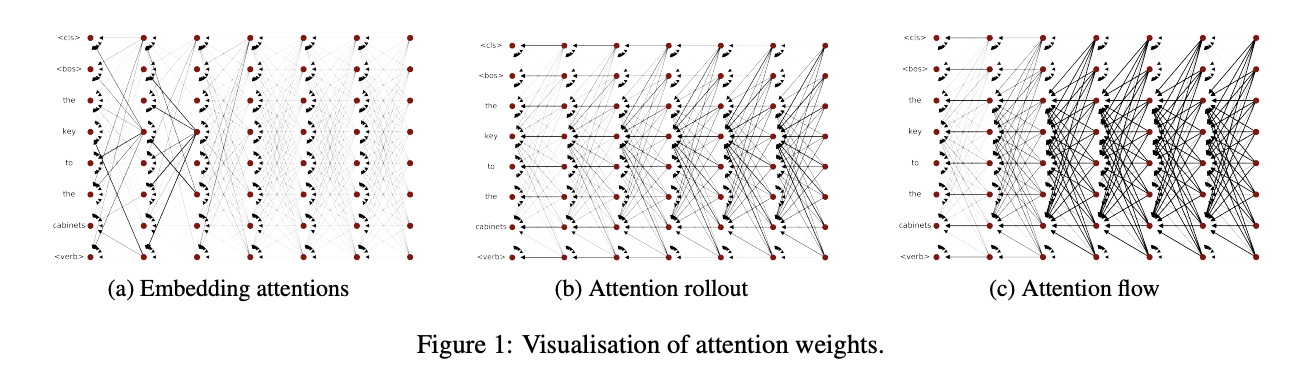
出典:https://arxiv.org/pdf/2005.00928.pdf
ailia-modelsに搭載されているViTについては、jeonsworldさんの実装を踏襲させて頂いています。
尚、ailia-modelsについては、動画入力の対応もしていますので、attention mapがフレーム毎にどう推移していくかを、連続的に確認することもできます。
ailia SDKからの利用
ailia SDKで用意しているvitのプログラムは、以下となります。
画像に対して処理を実行するには、下記のコマンドを使用します。
$ python vit.py -i input.png
実行例が以下です。
(画像への実行)
(動画への実行)
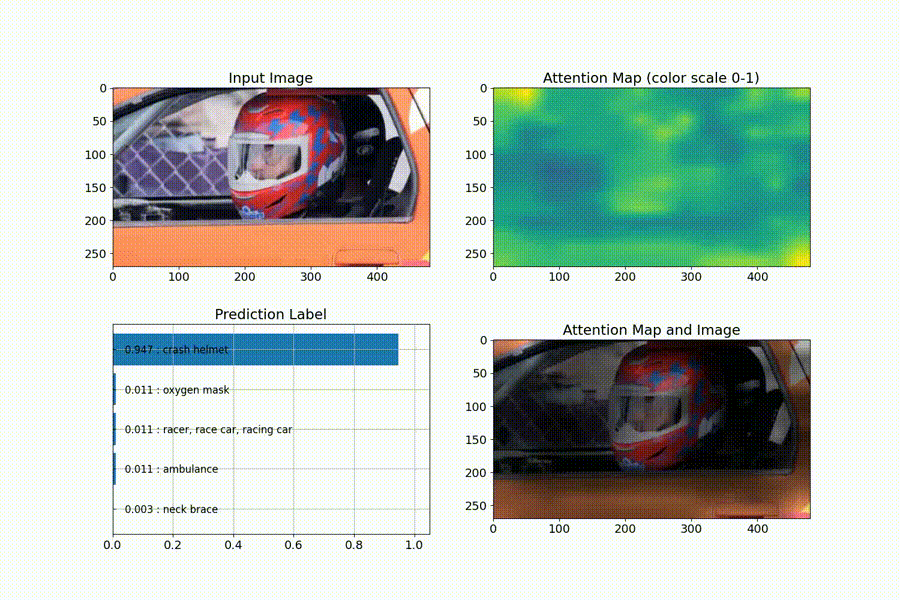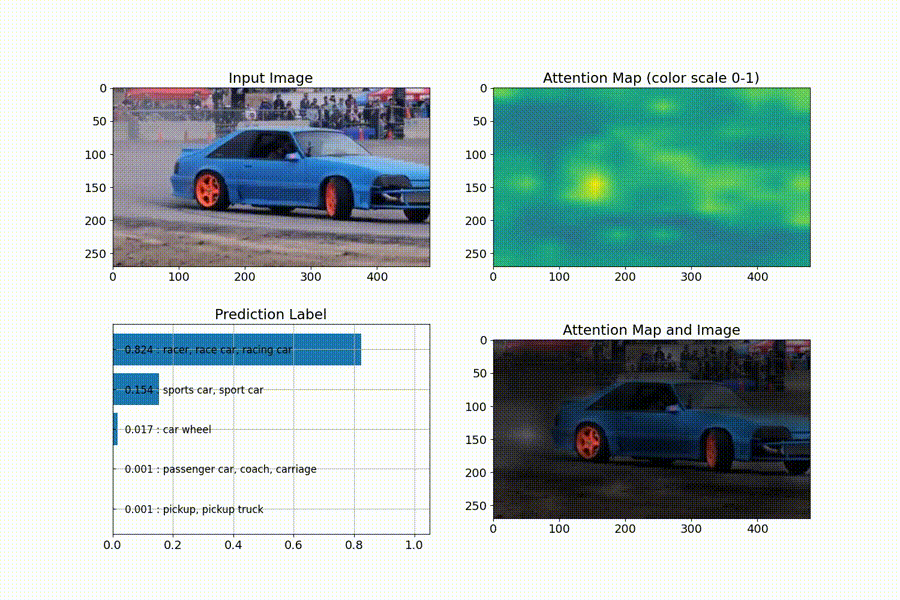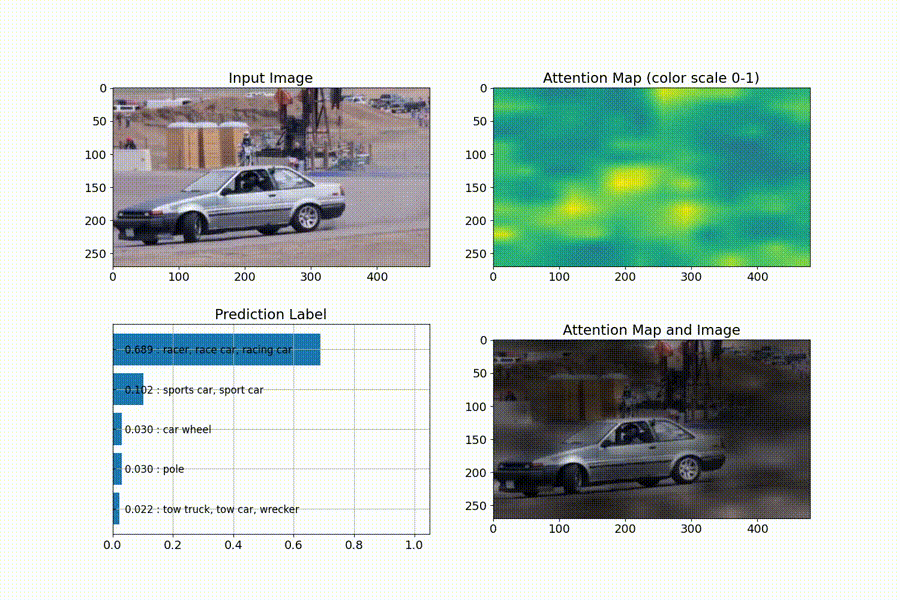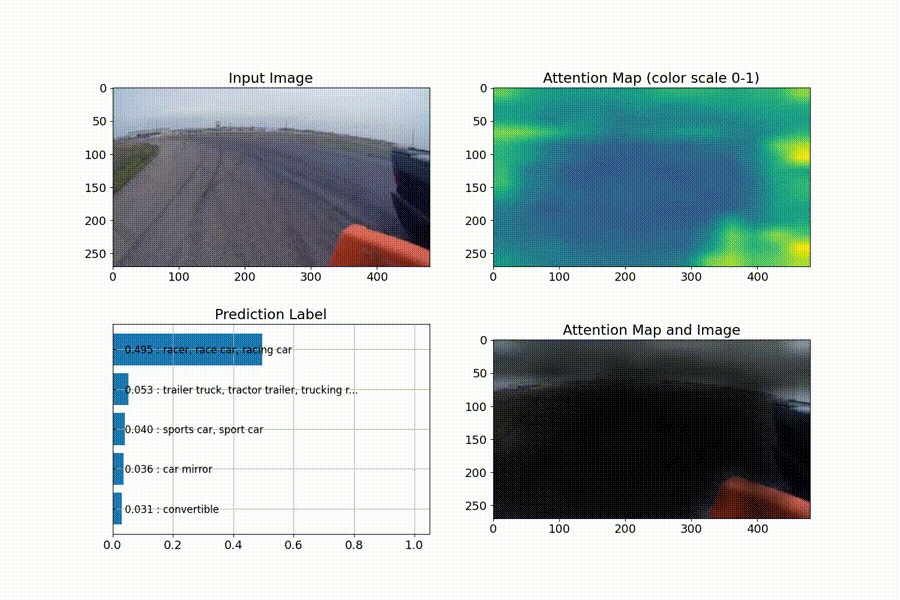
動画の出典:https://pixabay.com/videos/car-racing-motor-sports-action-74/
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。
アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください