TOP-N Accuracy : 物体識別モデルの評価指標
物体識別モデルをImageNetのTOP-N Accuracyによって評価する手法を解説します。
物体識別モデルについて
物体識別(Image Classification)は、入力された画像が何であるかを当てるタスクです。例えば、時計の画像を入力した場合、機械学習モデルはAnalog Clock 90%、Wall Clock 9.6%、Stop Watch 0.01%などと出力します。分類対象のカテゴリをクラスと呼びます。
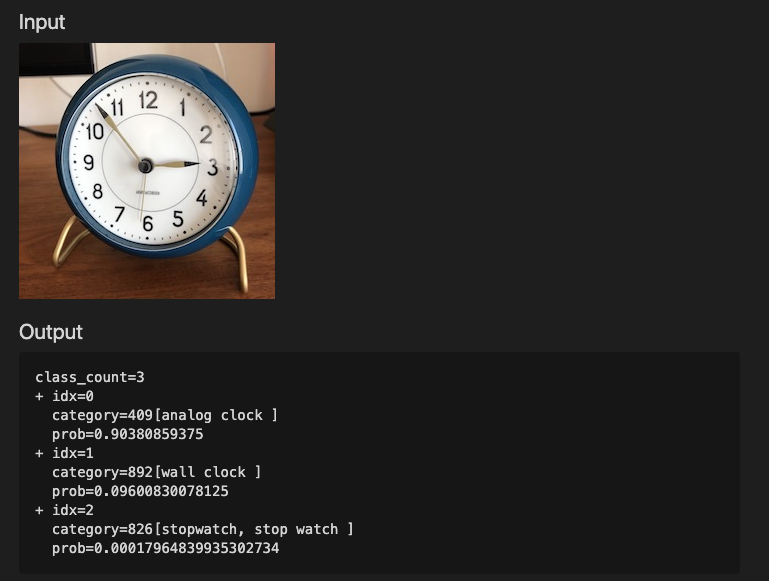
Image Classification Task
TOP-1 AccuracyとTOP-5 Accuracyについて
物体識別モデルの評価にはTOP-1 AccuracyとTOP-5 Accuracyを使用します。TOP-1 Accuracyは、物体識別モデルの出力のうち、最も確率の高いクラスと、正解データのクラスが一致している場合に正解とします。TOP-5 Accuracyは、物体識別モデルの確率の高い上位5つのクラスに、正解データのクラスが含まれている場合に正解とします。
クラス数が1000などと大きくなった場合、Analog ClockとWall Clockなど、紛らわしいクラスラベルも存在するため、完全に正解することが難しくなります。そこで、完全に正解しなくても、AIの出力の上位5位以内にクラスが存在したら正解として精度を計測するのが、TOP-5 Accuracyです。
ImageNetについて
物体識別モデルの評価においては、ImageNetのバリデーション画像が広く用いられています。ImageNetは入力された画像を1000カテゴリに分類する物体識別タスクです。
データセットはImageNetのDownloadページからリンクされているKaggleのDataページからダウンロード可能です。166GBのデータセットで、1,281,167枚の学習用画像、50,000枚のバリデーション画像、100,000枚のテスト画像が含まれます。
出典:https://www.kaggle.com/competitions/imagenet-object-localization-challenge/data
ImageNet Object Localization ChallengeIdentify the objects in imageswww.kaggle.com
ImageNetのデータのうち、アノテーションされている画像は学習用画像とバリデーション画像です。
画像ファイルは下記のようなパスに格納されています。
ILSVRC/Data/CLS-LOC/val/ILSVRC2012_val_00022146.JPEG
バリデーション画像のみを展開するには下記のコマンドを使用します。
tar -xvzf imagenet_object_localization_patched2019.tar.gz "*val*"
アノテーションファイルであるLOC_val_solution.csvの例です。ラベル名と、バウンディングボックスが含まれます。
ILSVRC2012_val_00048981,n03995372 85 1 499 272
ILSVRC2012_val_00037956,n03481172 131 0 499 254
ラベル名は、LOC_synset_mapping.txtを使用して、ラベルID(1–1000)に変換する必要があります。
n01440764 tench, Tinca tinca
n01443537 goldfish, Carassius auratus
ImageNetの画像の前処理について
ImageNetの画像は、短辺を256pxにアスペクトを維持してリサイズした後、224x224にクロップして使用します。
Kerasのモデルでは、BGRのレンジ0–255の画像を読み込んだ後、 mean=[103.939, 116.779, 123.68]を減算します。std=1です。
Torchのモデルでは、RGBのレンジ0–1.0の画像を読み込んだ後、mean=[0.485, 0.456, 0.406]を減算し、std=[0.229,0.224,0.225]で除算します。
ImageNetのTTAについて
ImageNetの精度の計測では、TTA (Test Time Augmentation)が使用されています。
1-cropでは、256x256にリサイズした後、中心の224x224をクロップします。KerasやTorchの公式のベンチマークでは1-cropが使用されています。
10-cropでは、256x256にリサイズした後、(左上、右上、左下、右下、中央)の5種類のクロップに、(左右反転)を適用した10種類のクロップを行い、それぞれで推論を行い、出力を平均化します。10-cropはAlexNetで使用されており、ResNet50でも使用されています。10-cropはTOP-1 Accuracyを1.2%程度改善します。
ImageNetのベンチマークについて
KerasとPytorchの各モデルのTOP-N Accuracy (1-crop)は下記のサイトに記載されています。
ApplicationsKerasの応用は事前学習した重みを利用可能な深層学習のモデルです. これらのモデルは予測,特徴量抽出そしてfine-tuningのために利用できます.…keras.io
Kerasでは、ImageNetの検証データセットを参照して、TOP-1 Accuracy、TOP-5 Accuracyで記載しています。
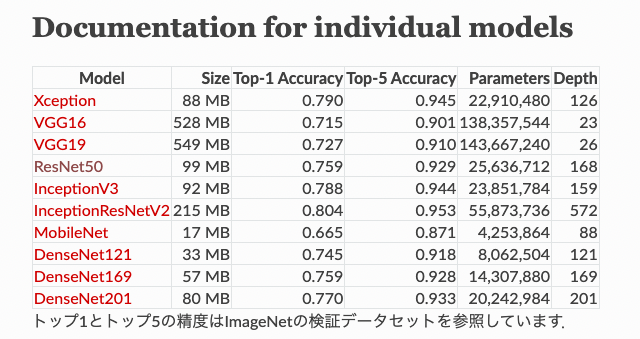
出典:https://keras.io/ja/applications/
Pytorchでは、ImageNet 1-crop error rateとして、TOP-1 AccuracyをAcc@1、TOP-5 AccuracyをAcc@5で記載しています。
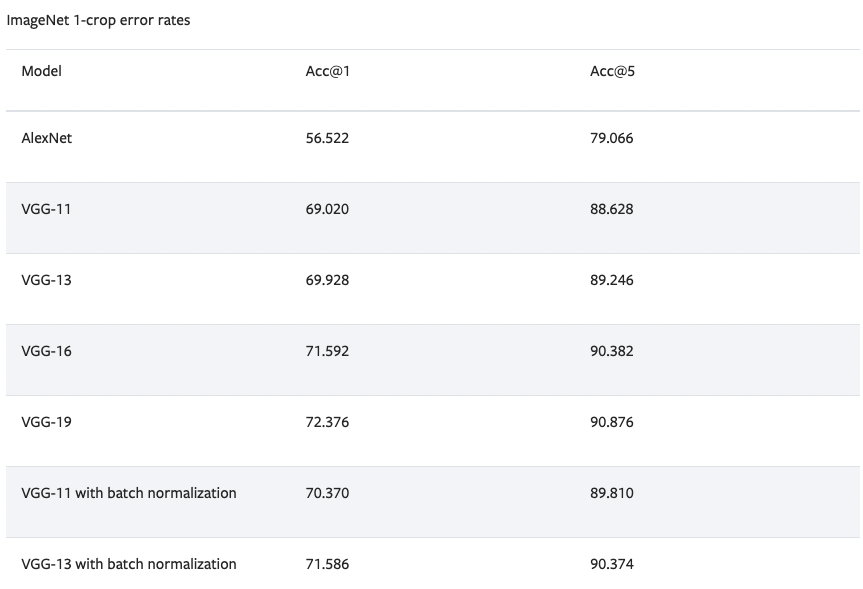
出典:https://pytorch.org/vision/stable/models.html
ResNet50の場合、各フレームワークの公式のベンチマークスコアは下記の値となります。TOP-5 Accuracyの方が問題が簡単になるため、スコアが高くなります。
Pytorch (1-crop)
TOP-1 Accuracy : 0.7592
TOP-5 Accuracy : 0.9281
Keras (1-crop)
TOP-1 Accuracy : 0.759
TOP-5 Accuracy : 0.929
Paper (10-crop)
TOP-1 Accuracy : 0.7715
TOP-5 Accuracy : 0.9329
ResNet50の論文のスコアは下記から引用しました。
1-cropの効果
PytorchとChainerで学習したモデルを使用した場合の、1-cropの有無による性能評価を図に示します。
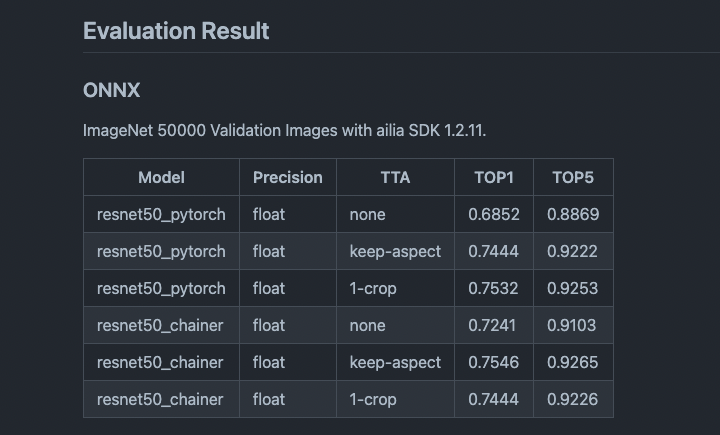
1-cropの有無に関する精度比較結果
TTAの各項目の詳細は下記となります。
・none : 入力画像を224x224にリサイズ
・keep-aspect : 入力画像の短辺を224にリサイズして224x224にクロップ
・1-crop : 入力画像の短辺を256にリサイズして224x224にクロップ
アスペクトを保持したリサイズを行うことで、Pytorchの場合、TOP1で5.9%、TOP5で3.6%、精度が向上します。Chainerの場合、TOP1で3.0%、TOP5で1.62%、精度が向上します。
256にリサイズしてセンタークロップを導入した方が良いかはモデルによって異なり、Pytorchの場合は導入した方がTOP1で0.88%、TOP5で0.31%、精度が向上します。Chainerの場合は、TOP1で1.02%、TOP5で0.39%、精度が低下します。
TOP-1 AccuracyとTOP-5 Accuracyの計測スクリプトの例
ailia-modelsの各モデルのTOP-1 AccuracyとTOP-5 Accuracyを計測するスクリプトの例です。ImageNetのデータセットは事前にダウンロードして、dataフォルダに配置する必要があります。
下記のコマンドで指定したモデルで推論を行い結果をテキストに出力します。
python3 prediction.py -m MODEL
下記のコマンドで指定したモデルの精度を出力します。
python3 accuracy.py -m MODEL
出力例は下記となります。
Accuracy
DATA CNT : 50000
TOP1 : 0.753240
TOP5 : 0.925360
TensorFlowLiteの量子化の性能への影響
TOP-1 AccuracyとTOP-5 Accuracyを計測することで、TensorFlowLiteのFloatモデルをInt8に量子化した場合の性能への影響を計測することができます。
TensorFlowLiteの量子化では、キャリブレーション画像を入力し、Floatで推論することで、各レイヤーのテンソルのMin/Maxを計算し、Int8に量子化します。
実際に、ResNet50をTensorFlow2.7で量子化した場合の性能は下記となります。
Floatモデル (1-crop)
TOP-1 Accuracy : 0.7508
TOP-5 Accuracy : 0.9217
Int8モデル (1-crop) (キャリブレーション画像4枚)
TOP-1 Accuracy : 0.7029
TOP-5 Accuracy : 0.9188
Int8モデル (1-crop) (キャリブレーション画像50000枚)
TOP-1 Accuracy : 0.7467
TOP-5 Accuracy : 0.9125
キャリブレーション画像を4枚から50000枚に増加させることで、TOP-1 Accuracyが4.38%程度、改善します。
しかし、意外と4枚のキャリブレーション画像でも高い精度が出ています。これは、テンソルのInt8への量子化では、Tensor-wise quantizationが使用されており、1つのテンソルのチャンネルの全体でMin/Maxを取るためであると考えています。そのため、どのような画像を入れても、同じようなMin/Max値を取る傾向にあると考えられます。また、ウエイトの量子化にはAxis-wise quantizationが使用されますが、重みにはキャリブレーションの影響はないため、キャリブレーション画像の枚数が影響しないものと考えています。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。