T5を使用してWhisperの音声認識誤り訂正を行う
Whisperの出力するテキストにT5を適用することで、音声認識誤り訂正を行う方法を紹介します。
音声認識誤りとは
音声認識において、未知語に対する認識結果が誤ることがあります。これを音声認識誤りと呼びます。特に、医療用語など専門的な用語が誤りやすい傾向にあります。
これまでの実験
弊社では、これまで、WhisperのFine Tuningによる訂正と、Whisperの認識結果に対する誤り訂正辞書のアプローチで音声認識結果の訂正を行いました。しかし、Fine Tuningにはモデルが壊れやすく通常の認識結果の精度が低下するという課題があり、誤り訂正辞書には誤り方の揺らぎに弱いという課題がありました。
T5による誤り訂正
T5はテキストを入力してテキストを出力する言語モデルです。今回は、誤りを含むテキストを入力して、誤りを修正したテキストを出力する、End2Endの誤り訂正モデルを作成することを目指します。
T5の概要(出典:https://arxiv.org/pdf/1910.10683.pdf)
T5による誤り訂正は、下記の論文に事例があります。
T5による誤り訂正のアーキテクチャ
今回のシステムのアーキテクチャです。医療用語の専門用語辞書から、ChatGPTを使って専門用語を含む会話のテキストを生成します。次に、GoogleText2Speechで音声合成を行い、それをWhisper Mediumに入力して音声認識を行います。元のテキストを正解データ、音声認識結果のテキストを誤りデータとして、T5の学習を行います。
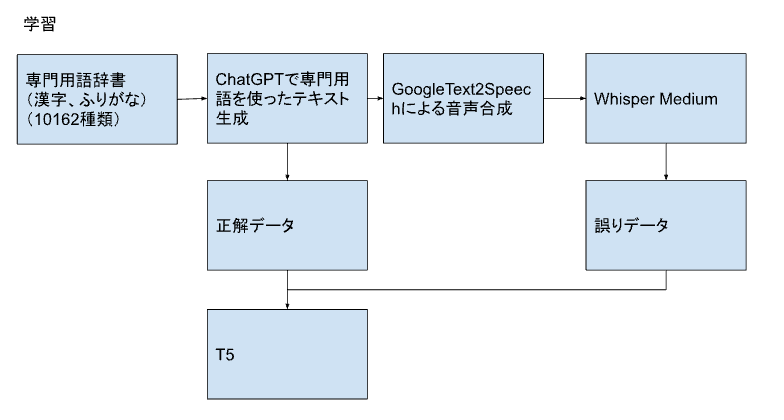
学習のフロー
推論時は、マイクからWhisper Mediumで音声認識を行い、そのテキストをT5に入力することで、誤り訂正したテキストを取得します。

推論のフロー
実装条件
T5にはretrieva-jp/t5-base-shortを使用します。
用語ごとに、ChatGPTで3パターンの文章を作成します。学習用の音声データは29563個、テスト用の音声データは9604個です。
T5の学習時間はRTX2060 (VRAM 6GB) で80時間程度です。
args = Seq2SeqTrainingArguments(
f'{model_name}',
evaluation_strategy='steps',
eval_steps=0.1,
learning_rate=2e-5,
per_device_train_batch_size=16,
per_device_eval_batch_size=16,
gradient_accumulation_steps=1,
weight_decay=0.01,
save_total_limit=10,
num_train_epochs=50,
log_level='warning',
save_strategy='steps',
save_steps=0.1,
predict_with_generate=False,
fp16=False,
dataloader_num_workers=4,
push_to_hub=False,
auto_find_batch_size=False,
seed=42,
)
学習前の精度
学習用データをWhisperに適用した際、学習用データとWhisperの出力が全文一致した割合は下記となります。この値が学習前の精度となります。Whisperは句読点が揺らぐことがあるため、句読点を除くと精度が改善します。

学習前の精度
学習結果
全文一致での学習データと検証データでの精度比較です。実際にエラー内容を分析すると、「2次」と「二次」や、「頑張る」と「がんばる」など、表記揺れが発生していたため、これらの変化を許容する形で精度を計測すると、学習データで78%程度、検証データで54%程度の文章を正しく訂正することが可能です。
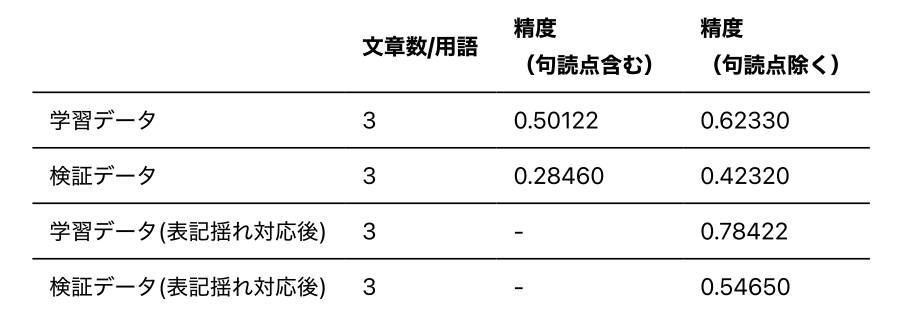
学習結果の精度
学習用データセットの22%のエラー内容は下記となります。「悸疸鬆瘻盂蕁嗽瘢蹠褥胼胝涎嗄齲弯渣跛霰簇酩酊暈」については、T5のTokenizerに含まれない文字であるため、推論後にUNKに変化しています。目と眼など、意味が近い言葉が置き換わることも全文一致での精度低下を発生させているようです。
error_list
[[とき], [時]] 278
[[], [悸]] 222
[[], [疸]] 208
[[], [身]] 161
[[と], [取]] 149
[[], [っ]] 138
[[た], [溜]] 117
[[わ], [分]] 88
[[1], [一]] 88
[[脚], [足]] 76
[[頚], [頸]] 75
[[目], [眼]] 69
[[のど], [喉]] 68
[[ひど], [酷]] 65
[[まれ], [稀]] 61
[[か], [ヶ]] 59
[[かゆ], [痒]] 54
[[もの], [物]] 52
[[〜], [~]] 45
[[よ], [良]] 44
[[す], [過]] 43
[[], [・]] 39
[[なか], [腹]] 37
[[しび], [痺]] 37
[[頚, 頚], [頸, 頸]] 36
テスト用データの46%のエラー内容は下記となります。こちらも、学習時と同じ傾向にあります。
error_list
[[], [身]] 71
[[とき], [時]] 68
[[], [悸]] 53
[[と], [取]] 51
[[], [疸]] 47
[[た], [溜]] 47
[[], [っ]] 38
[[頚], [頸]] 36
[[目], [眼]] 30
[[], [・]] 28
[[わ], [分]] 25
[[1], [一]] 24
[[], [し]] 24
[[よ], [良]] 23
[[かゆ], [痒]] 21
[[頚, 頚], [頸, 頸]] 20
[[脚], [足]] 19
[[もの], [物]] 17
[[のど], [喉]] 16
[[で], [出]] 16
[[す], [過]] 15
[[い], [言]] 14
[[なん], [何]] 13
[[つら], [辛]] 13
[[ひど], [酷]] 13
実際の音声での評価
音声合成ではなく、実際の音声を入力して正しく認識できるかの評価を行いました。合成音声で学習した場合も、実際の音声に適用可能であることを確認しました。
Whisperによる認識結果
検査結果が出ましたが、残念ながらB型肝炎肝抗片と診断されました。
肝抗片ってどういう病気なんですか?治療方法はありますか?
肝抗片は肝臓の繊維化が進行し、正常な肝機能が低下する状態です。
治療方法としてはウイルス抑制薬や肝臓移植が考えられます。移植って大変な手術ですよね。
他に何かできることはありますか?はい、肝抗片の進行を遅らせるために、アルコールや脂肪の摂取を控え、
バランスの取れた食事や適度な運動を心がけることが重要です。定期的な検査も忘れなく。
なるほど、生活習慣の改善が大切なんですね。頑張って取り組みます。ありがとうございました。
T5による訂正結果
検査結果が出ましたが、残念ながらB型肝炎肝硬変と診断されました。
肝硬変ってどういう病気なんですか?治療方法はありますか?
肝硬変は肝臓の線維化が進行し、正常な肝機能が低下する状態です。
治療方法としてはウイルス抑制薬や肝臓移植が考えられます。移植って大変な手術ですよね。
他に何かできることはありますか?はい、肝硬変の進行を遅らせるために、アルコールや脂肪の摂取を控え、
バランスの取れた食事や適度な運動を心掛けることが重要です。定期的な検査も忘れなく。
なるほど、生活習慣の改善が大切なんですね。頑張って取り組みます。ありがとうございました。
揺らぎへの耐性
常に同じ間違え方をする場合、誤り辞書でも訂正可能です。下記の例は、常に「痙攣」を「経連」と間違えるケースであり、誤り辞書で訂正可能です。
Whisperによる認識結果
こんにちは、先生。最近手足の経連があります。
こんにちは。手足の経連がある場合、心臓の問題が考えられます。
経連の発作がいつ頻繁に起こるかを教えていただけますか?
経連はほとんど毎日です。
T5による訂正結果
こんにちは、先生。最近手足の痙攣があります。
こんにちは。手足の痙攣がある場合、心臓の問題が考えられます。
痙攣の発作がいつ頻繁に起こるかを教えていただけますか?
痙攣はほとんど毎日です。
しかし、誤り方にバリエーションが存在する場合、誤り訂正辞書での訂正が困難になります。下記の例では、意図的に誤りにバリエーションを付与しています。T5を使用することで、誤り方に揺らぎがあっても、ある程度の訂正を行うことが可能であることがわかります。
Whisperによる認識結果を意図的に書き換え
こんにちは、先生。最近手足の経連があります。
こんにちは。手足の敬璉がある場合、心臓の問題が考えられます。
系レンの発作がいつ頻繁に起こるかを教えていただけますか?
景連はほとんど毎日です。
T5による訂正結果
こんにちは、先生。最近手足のけいれんがあります。
こんにちは。手足のけいれんがある場合、心臓の問題が考えられます。
けいれんの発作がいつ頻繁に起こるかを教えていただけますか?
けいれんはほとんど毎日です。
句読点の補完
Whisperは推論結果の句読点が失われる場合があります。今回、句読点を含む文章を教師データとして学習を行っているため、句読点の消失も誤りと認識され、T5による誤り訂正を行うと句読点が補われます。
Whisperによる音声認識結果
血圧も高いしコレステロールも高いですね
お薬を飲んだ方がいいですよ
今は何の症状もないし調子いいんですよ
血圧が高いままコレステロールが高いままにしておくと心肝予測や脳卒中になる可能性が高くなりますので
薬あまり好きではありません
どうしてですか
副作用があるでしょう
それはありますが副作用できるだけ出さないよう出ても軽くて済むようにするのが医者の役割です
いや副作用が少しでもある限りお薬は嫌です
そうですかお薬でコントロールした方がいいのですがね
じゃあ塩分を控えて卵すじっこたらこなどを控えてお野菜をたくさんとってください
私は辛いものが好きなんです塩辛くないと食べた気がしないんです
卵も大好きで毎日食べないと力が出ないんです困りましたね
薬も使わず食事も好きなものを食べてもいいようにして血圧とコレストロールを治してください
T5による訂正結果
血圧も高いしコレステロールも高いですね。
お薬を飲んだ方がいいですよ。
今は何の症状もないし、調子いいんですよ。
血圧が高いまま、コレステロールが高いままにしておくと心筋梗塞や脳卒中になる可能性が高くなりますので。
薬あまり好きではありません。
どうしてですか?
副作用があるでしょう?
それはありますが、副作用できるだけ出さないよう、出ても軽くて済むようにするのが医者の役割です。
いや、副作用が少しでもある限り、お薬は嫌です。
そうですか、お薬でコントロールした方がいいのですがね。
じゃあ、塩分を控えて、卵焼きやたらこなどを控えて、お野菜をたくさん摂ってください。
私は辛いものが好きなんです。塩辛くないと食べた気がしないんです。
卵も大好きで、毎日食べないと力が出ないんです。
困りましたね。薬も使わず、食事も好きなものを食べてもいいようにして、血圧とコレストロールを治してください。
学習済みモデル
下記に今回作成した学習済みモデルをONNXに変換したものを公開しています。Whisper Mediumの認識結果のテキストを入力することで、誤り訂正した出力を得ることができます。
$ python3 t5_whisper_medical.py -i input.txt
ailia-models/natural_language_processing/t5_whisper_medical at master · ailia-ai/ailia-modelsThe collection of pre-trained, state-of-the-art AI models for ailia SDK …github.com
まとめ
T5を使用することでEnd2Endで音声認識誤り訂正を行えることを確認しました。訂正できない文字については、T5のトークナイザに含まれていない文字であることがあり、今後、add_tokensでトークンを追加することで、精度を改善できないか検討予定です。
謝辞
本研究は株式会社フェリックス様にご協力いただきました。
株式会社フェリックス | ferix inc.フェリックスは研究開発を受託で行うほか、スマホアプリなど自社サービスの展開をしているソフトウェア開発会社です。www.ferix.jp
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。