StableDiffusionWebUIとKohya’s GUIで生成したLoRAを使って特定のキャラクターの画像を生成する
PC上で簡単にイラストを生成できるStableDiffusionWebUIと、特定のキャラクターに特化したLoRAをKohya’sGUIで生成して、特定のキャラクターの画像を生成します。
StableDiffusionWebUIについて
StableDiffusionWebUIはPC上で簡単にイラストを生成できるフレームワークです。StableDiffusionWebUIのインストール方法は下記の記事を参照してください。
今回の検証環境のバージョンは下記です。
Windows 10
Python 3.10.9
StableDiffusionWebUI = 22bcc7be428c94e9408f589966c2040187245d81
LoRAについて
LoRAはStableDiffusionの一部の重みだけを再学習することで、LoRAの学習に使用した画像に沿った画像を出力するように制御することができる仕組みです。LoRAはStableDiffusionのモデルのうち、Attentionレイヤーのウエイトだけを再学習します。
Also, not all of the parameters need tuning: they found that often, Q,K,V,O (i.e., attention layer) of the transformer model is enough to tune. (This is also the reason why the end result is so small). This repo will follow the same idea.
LoRAを使用することで、自分の絵柄のキャラクターや、特定の構図の画像を生成することが可能です。
LoRAとControlNetは併用可能です。LoRAはStableDiffusionの一部のWeightを静的に変更するものであり、ControlNetはStableDiffusionの一部のFeatureVectorに動的に値を加算するものです。変更する箇所が異なるため、競合せず、併用可能です。
なお、LoRAはStableDiffusion固有の技術というわけではなく、大規模な基盤モデルを、忘却なく効率的に再学習する手法として広く使用されています。
例えば、下記はWhisperやLlamaにLoRAを適用する例です。
LoRAの適用
LoRAを適用するためのプラグインはStableDiffusionWebUIに標準でインストールされています。
学習済みのLoRAファイルはCivitaiからダウンロード可能です。
今回は、Gacha splach LORAをダウンロードします。このLoRAは、ガチャのスプラッシュスクリーン風の構図の画像を生成するためのものです。
ダウンロードしたLoRAは、stable-diffusion-webui/models/Loraに配置します。

ダウンロードしたLoraの配置
LoRAを適用するには、Generateの下にある、赤いアイコンを押します。
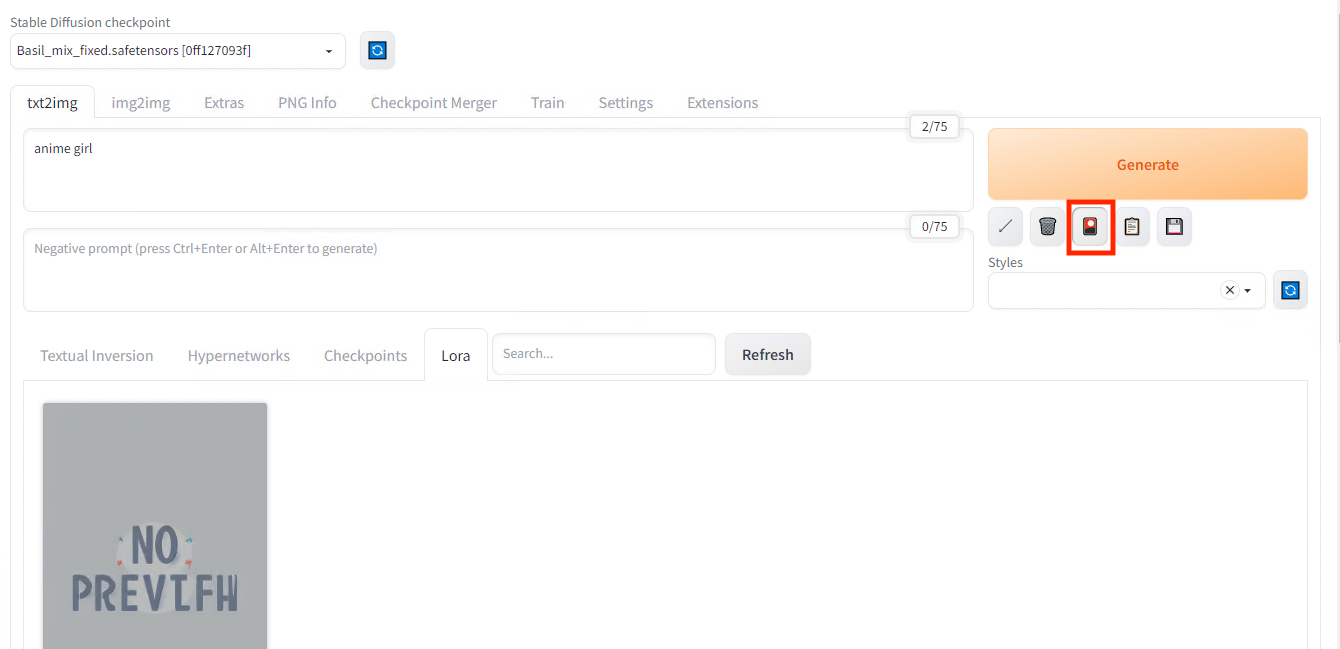
Loraの設定
適用したいLoRAを選択すると、プロンプトにLoRAが追加されます。
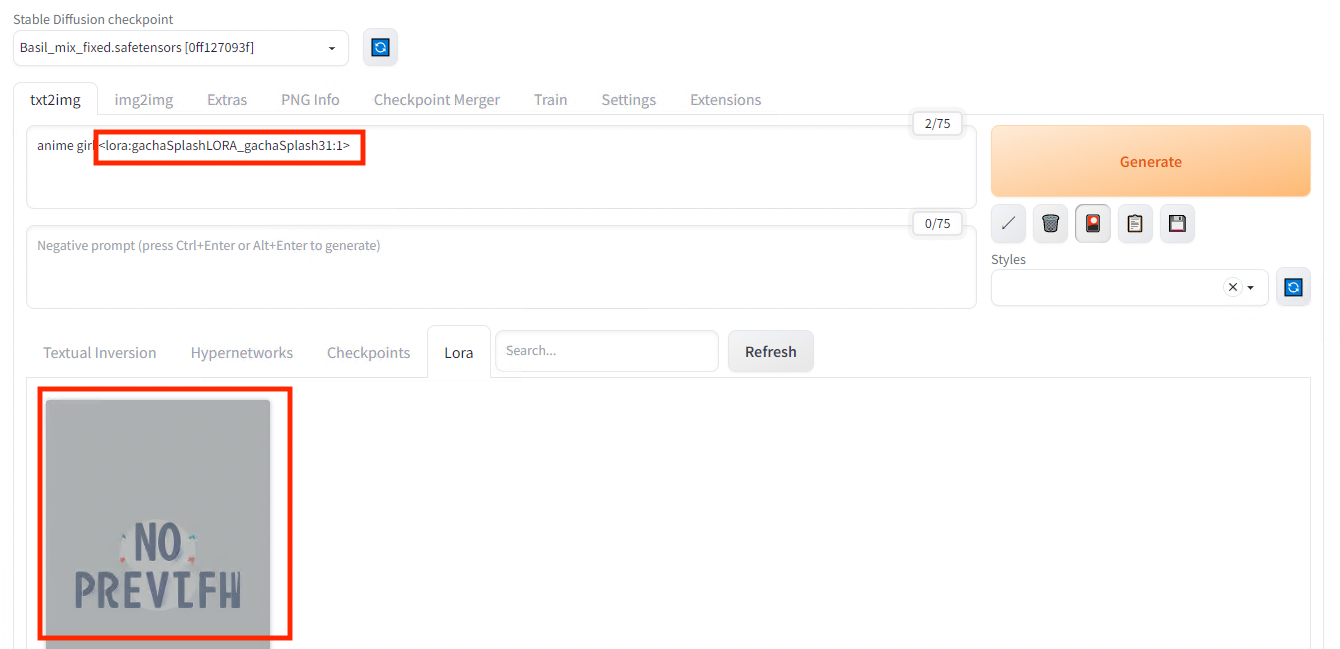
LoraのPromptへの適用
この状態で画像を生成すると、LoRAを適用した画像が出力されます。出力される画像がガチャのスプラッシュスクリーン風になっていることを確認することができます。
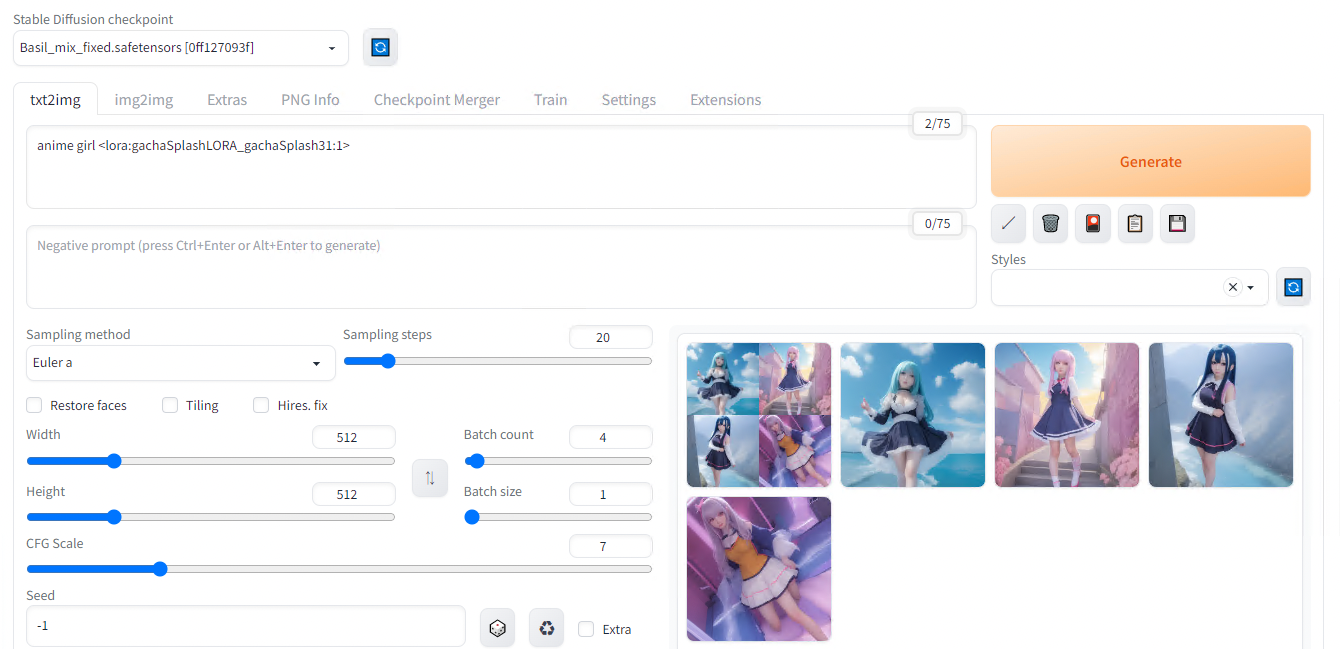
LoRAによる生成

anime girl + LoRAによる生成結果
SdWebUITrainToolsとKohya’s GUIについて
特定のキャラクターの画像を入力して、LoRAを作成する方法として、SdWebUITrainToolsを使う方法と、Kohys’s GUIを使う方法があります。
今回の検証では、Unity Chanの画像を生成するLoRAを作成することを目標とします。今回の検証では、SdWebUITrainToolsよりもKohya’s GUIを使った方が期待する結果が得られました。
今回、使用したSdWebUITrainToolsのバージョンは下記です。
sd-webui-train-tools = d2d984d8 (Fri Mar 31 15:14:28 2023)
Kohya’s GUIのバージョンは下記です。
kohya's gui = v21.5.2 cc52c73 (2023/4/13 3:19)
以降、SdWebUITrainToolsの使用方法と、Kohya’s GUIの使用方法を解説します。
SdWebUITrainToolsの使用方法
StableDiffusionWebUIでLoRAの学習を行うには、 https://github.com/liasece/sd-webui-train-tools をExtensionsのInstall from URLからインストールします。
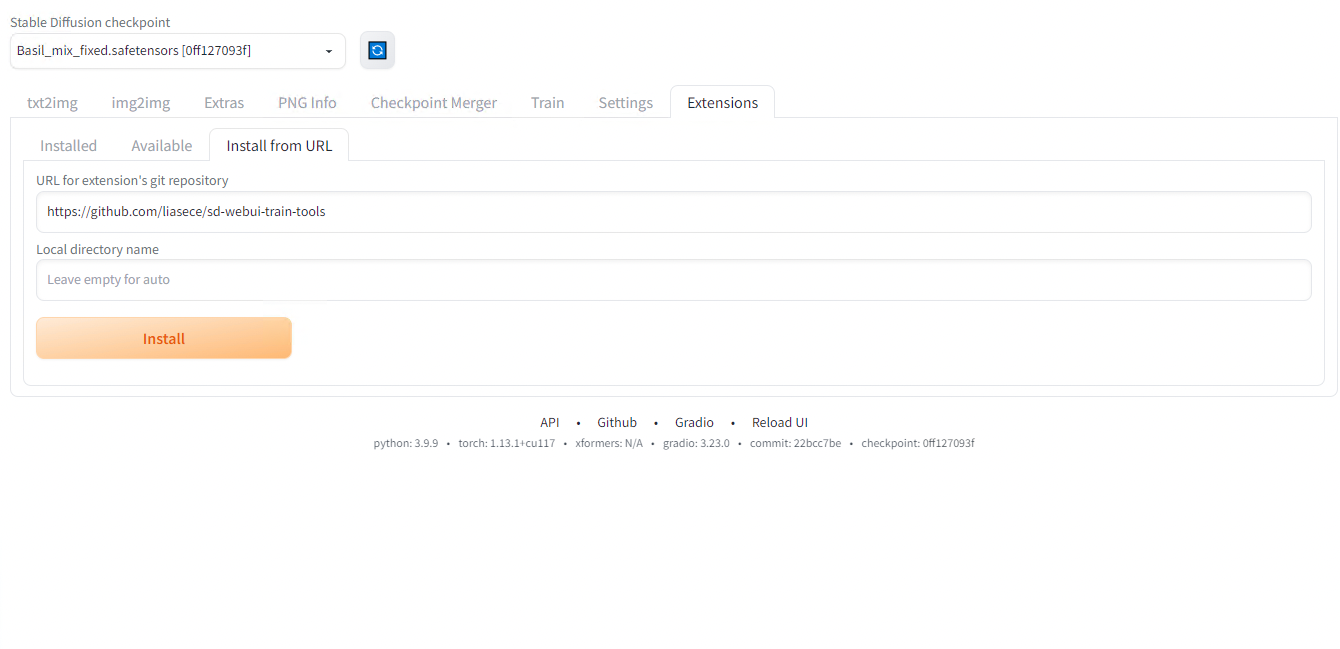
sd-webui-train-toolsのインストール
SdWebUITrainToolsをインストールすると、Train Toolsタブが増えています。Train Toolsたぶで、Create Projectを押し、新規プロジェクトを作成します。今回はunity_chanというプロジェクトを作成します。その後、Create versionでv1を作成します。
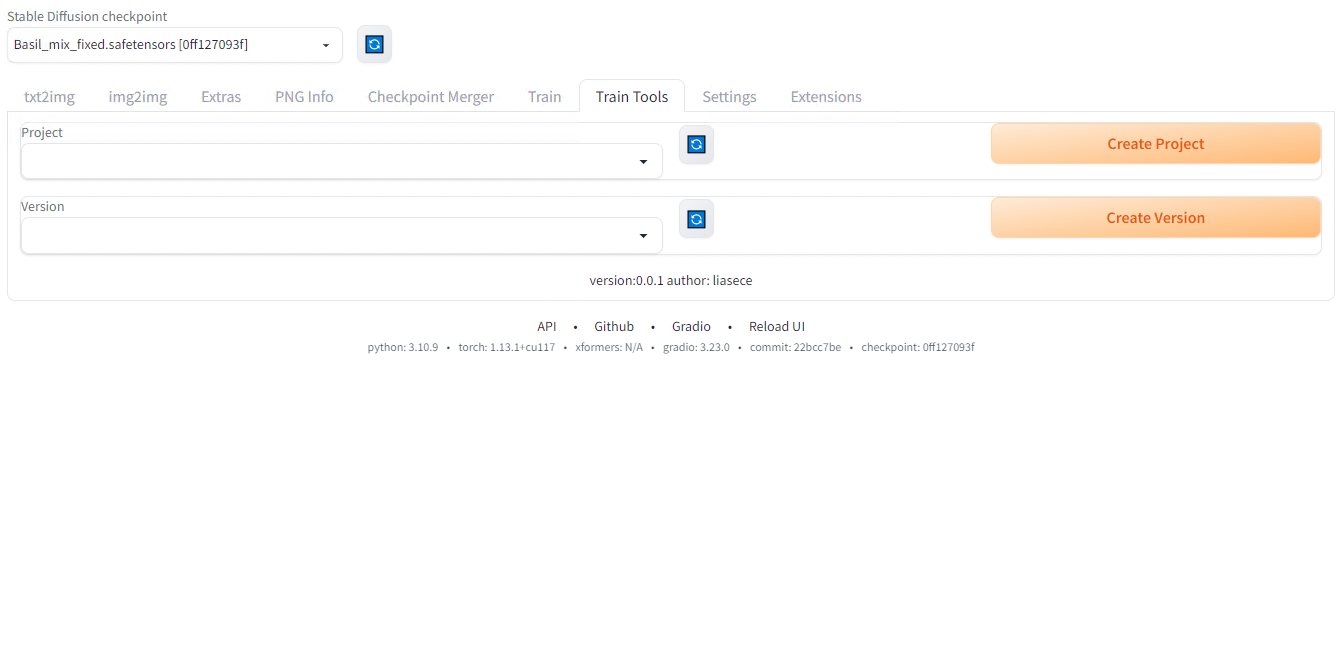
Train Toolsタブ
学習に使用するデータセットとして、ユニティちゃんHD画像パックVol.1をダウンロードします。(© Unity Technologies Japan/UCL)

学習に使用するデータセット
Upload Datasetに画像をドロップします。LoRAの学習には、20枚以上の画像が必要であると言われています。
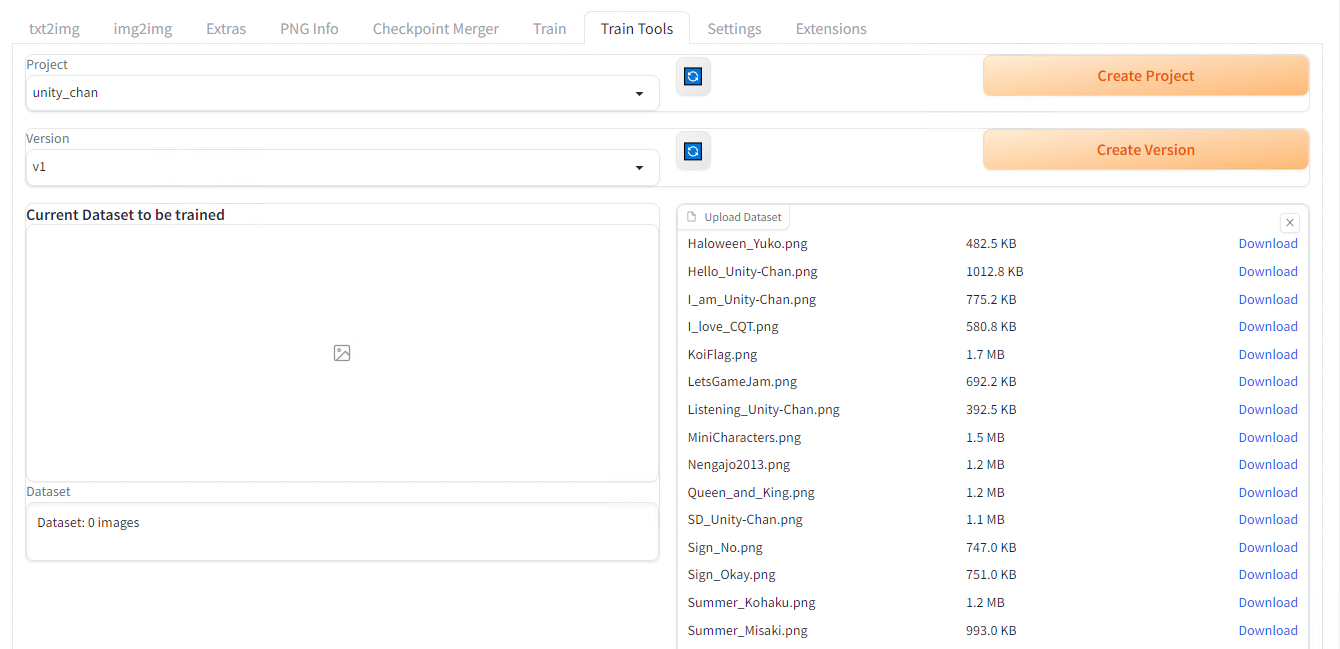
画像のドロップ
下にスクロールしてUpdate Datasetを押します。
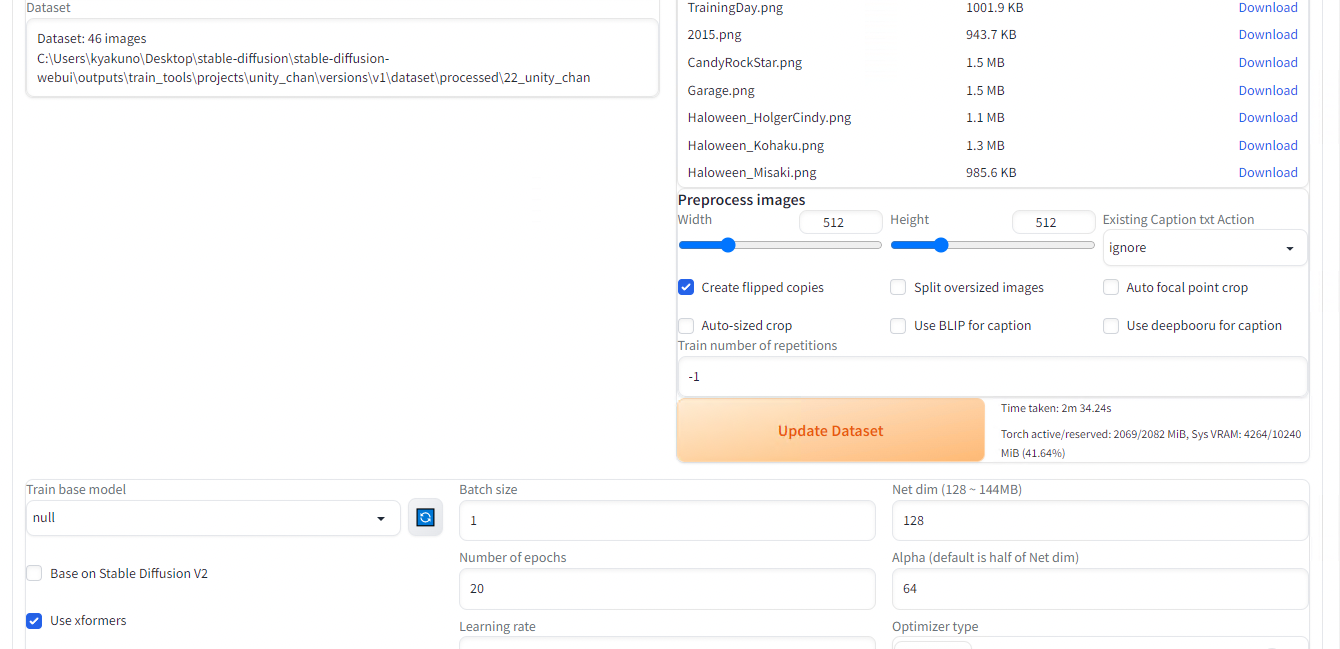
Update Dataset
下にスクロールしてTrain base modelを選択して、Begin trainを押します。
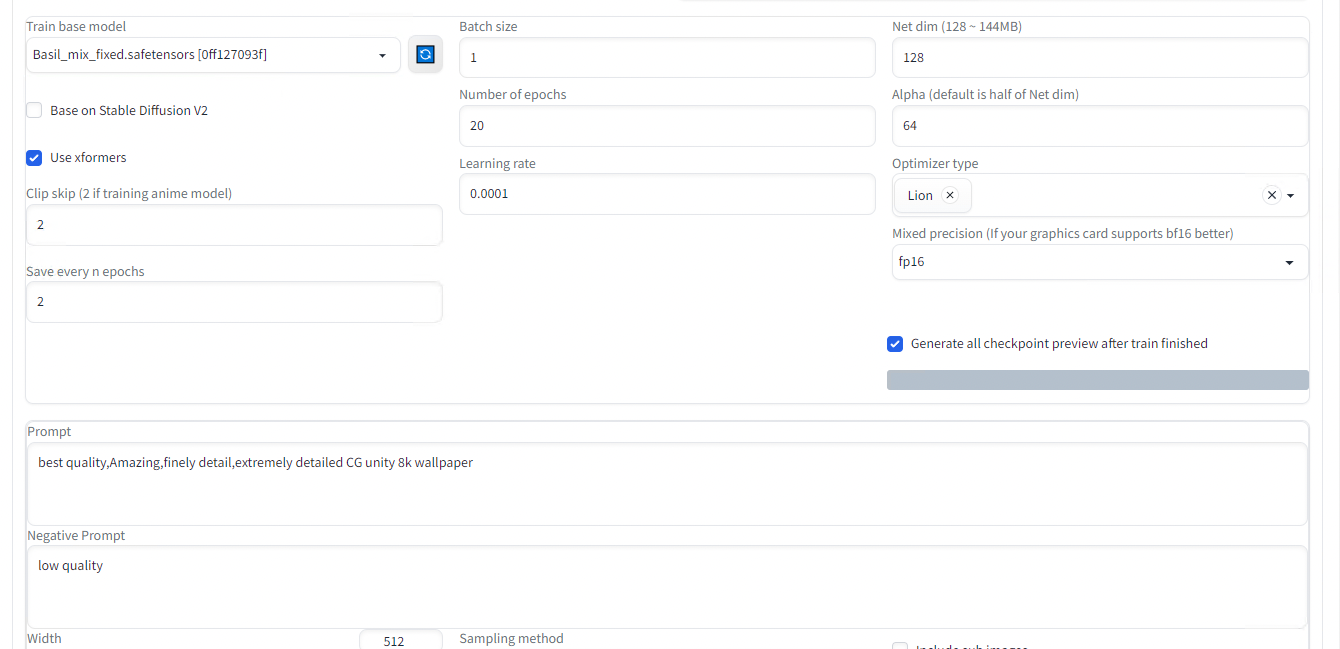
学習の実行中
学習にはRTX3080で2時間程度かかります。
学習が完了すると、下記にLoRAファイルが出力されます。
stable-diffusion-webui\outputs\train_tools\projects
出力先フォルダ
出力されたLoraファイル
学習が終わったファイルをstable-diffusion-webui/models/Loraにコピーします。
modelフォルダにコピーしたLora
txt2imgでGenerateの下の赤いボタンからLoRAを適用します。
Loraの適用
Generateで生成します。LoRAの強度が弱いのかいまいちUnityChanっぽくないです。
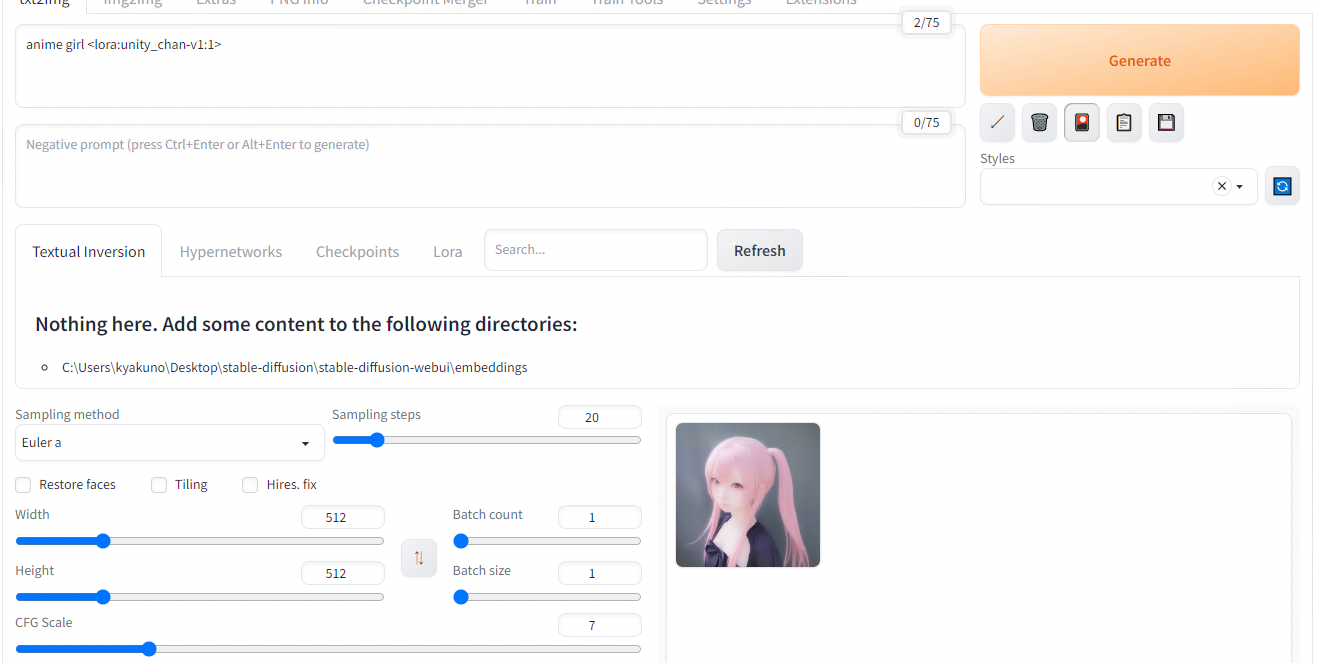
重み1
Promptでunity_chanに1000の重みを適用します。
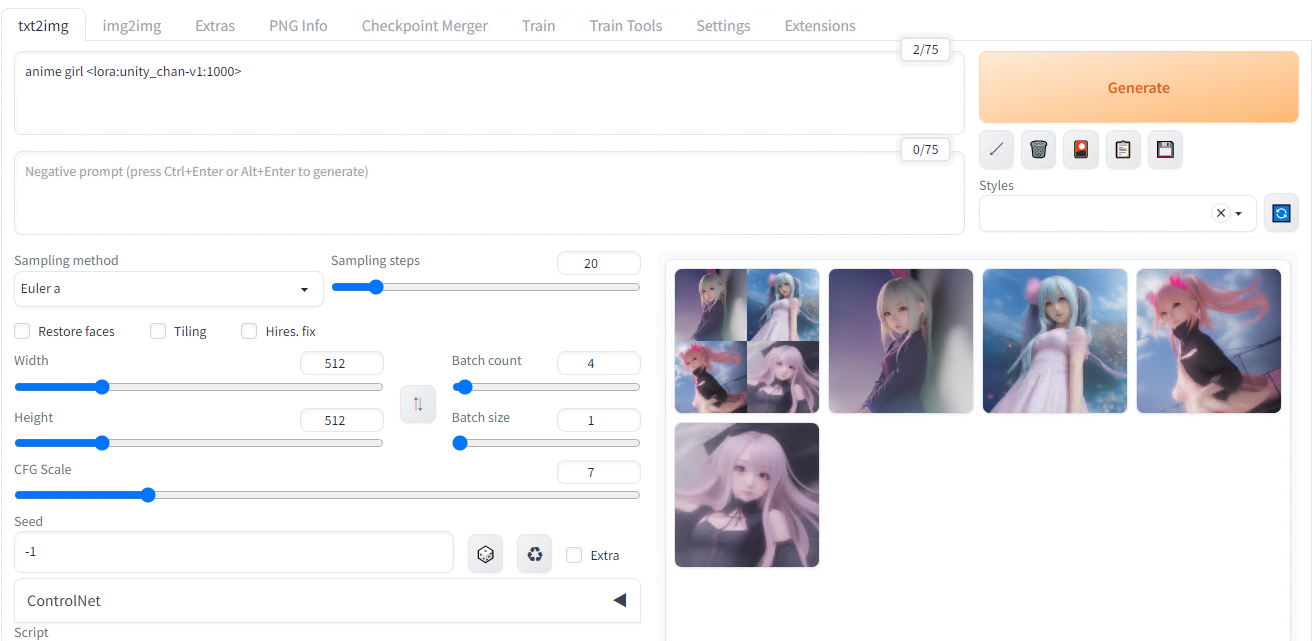
重み1000
データセットからUnityChanのツインテールとリボンの概念は獲得できているように見えます。

UnityChanの概念は獲得できている気がする
次に、データセットの最適化を行います。データセットにUnityChanじゃないものが混ざっているので削除します。また、データセットを増やしてみます。
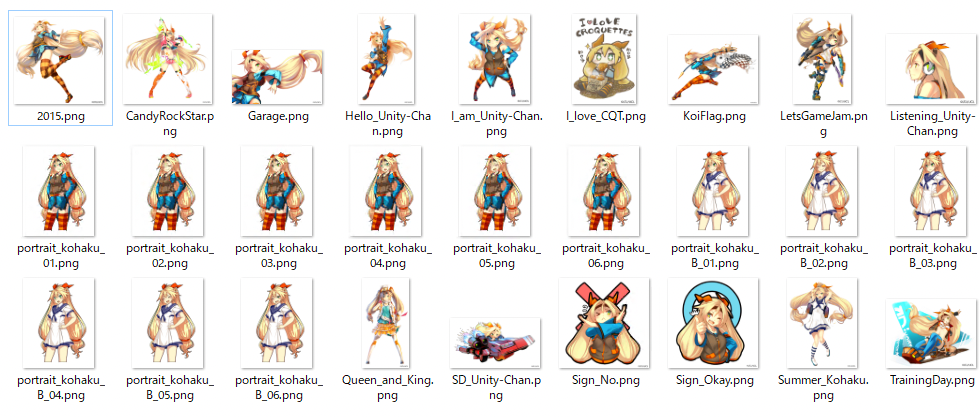
v2のデータセット
v2では、下記のようになりました。服装が近くなった気がします。

v2の出力
やはり実写になってしまうのは、ベースモデル(Basil_mix)が実写向けに最適化されているのではということで、アニメ調のデータを生成するため、モデルをAnything-v4に置き換えてみます。
Anything-v4に置き換えると下記のようになりました。現代風のアニメキャラになりました。ただ、まだUnity Chanには遠いです。

v5の出力
下記を見ると、キャラクターの再現にはPromptにできるだけキャラクターの特徴を記載した上で、学習した方がいいという記載がありました。
そこで、学習に使用するPromptをUnity Chanを示すものに変更します。女性、イエローの髪、ツインテール、オレンジのリボン、ブルーのヘッドバンド、グリーンの目、ロングヘアーなどを指定します。生成にも学習に使用したものと同じPromptを入力します。
変更前 : anime girl,best quality,Amazing,finely detail,extremely detailed CG unity 8k wallpaper
変更後:1 girl, yellow hair, twin tail, orange ribbon, blue head band, green eye, long hair
v6は下記のようになりました。Unity Chanに近づいてきた気はします。ただ、Unity Chanにはなりませんでした。

v6の出力
SdWebUITrainToolsだとこれ以上、追い込めなかったため、Kohya’s GUIを試します。
Kohya’s GUIの使用方法
学習に使用するデータセットとして、ユニティちゃんの画像をダウンロードします。(© Unity Technologies Japan/UCL)
使用するデータセットは下記です。

学習に使用するデータセット
Kohya’s GUIをインストールします
git clone https://github.com/bmaltais/kohya_ss
setup.bat
gui-user.bat
WEB UIを開いて、DreamboothLoRAを選択します。Source modelにベースモデルを指定します。今回はアニメ画像なので、AnythingV4を指定します。
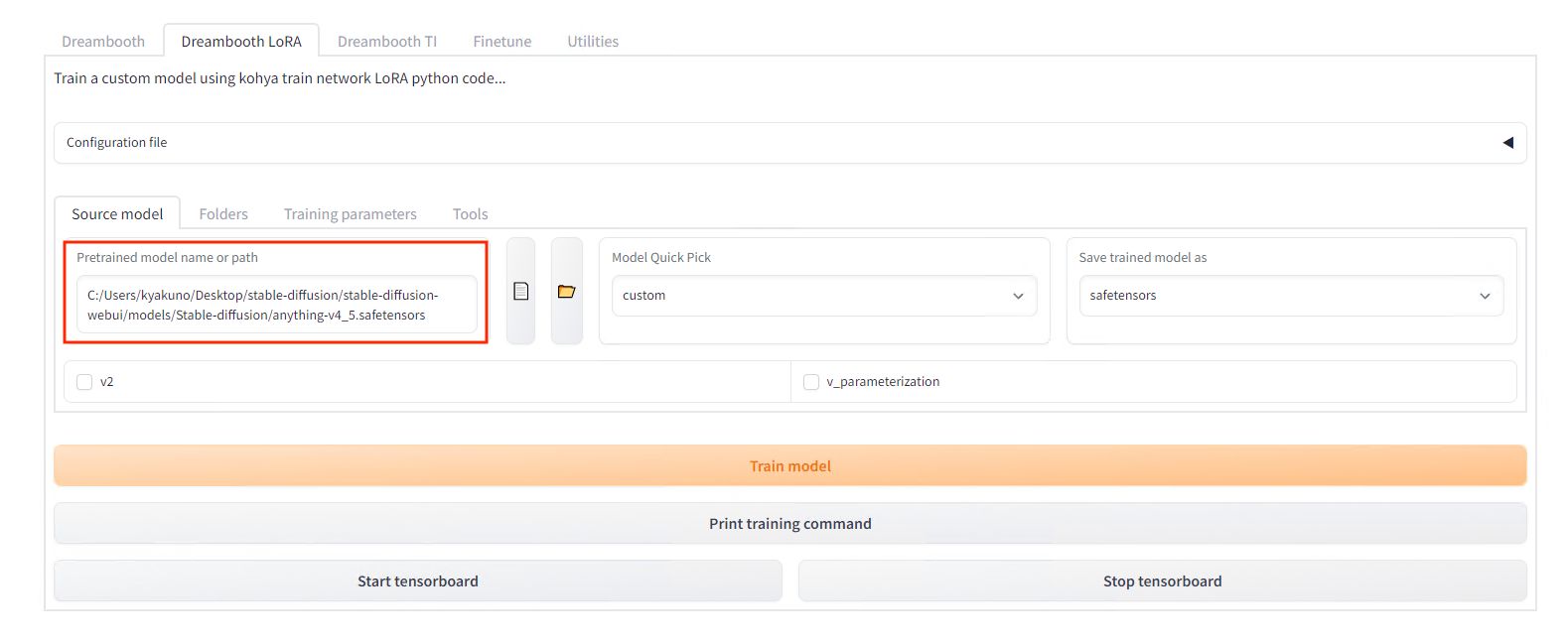
モデル指定
Foldersに学習させる画像のフォルダを指定します。画像のフォルダではなく、一階層上のフォルダを指定します。画像のフォルダ名が、ステップ数と、キャラクターの召喚用のPromptになります。今回は、20_unitychanというフォルダの中に画像を入れます。Outputに出力先のフォルダを指定します。
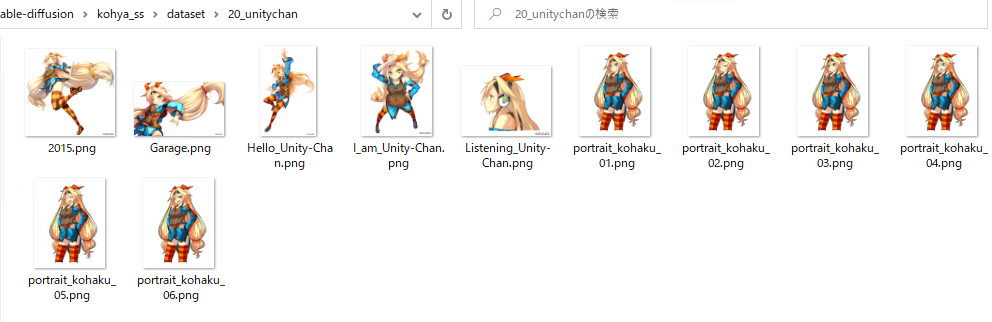
学習画像のフォルダ構成
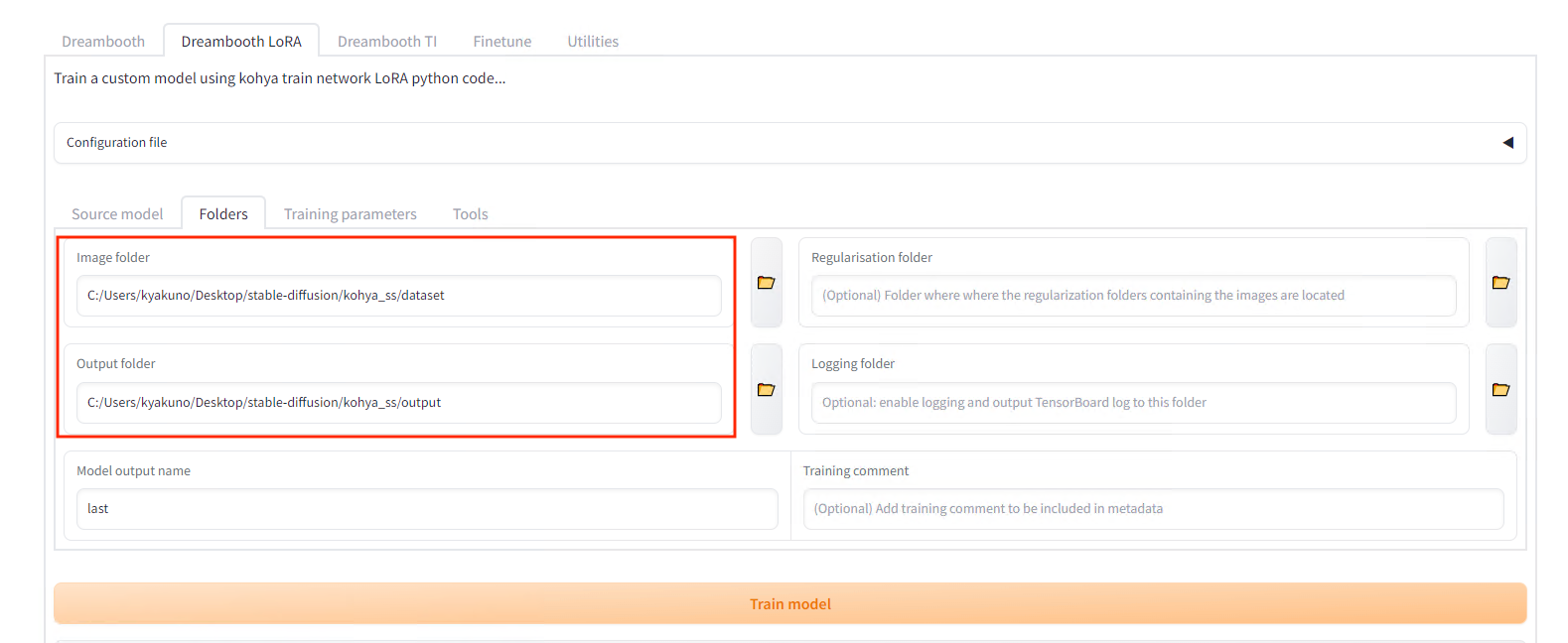
入出力フォルダ指定
設定でEpochsを5にします。
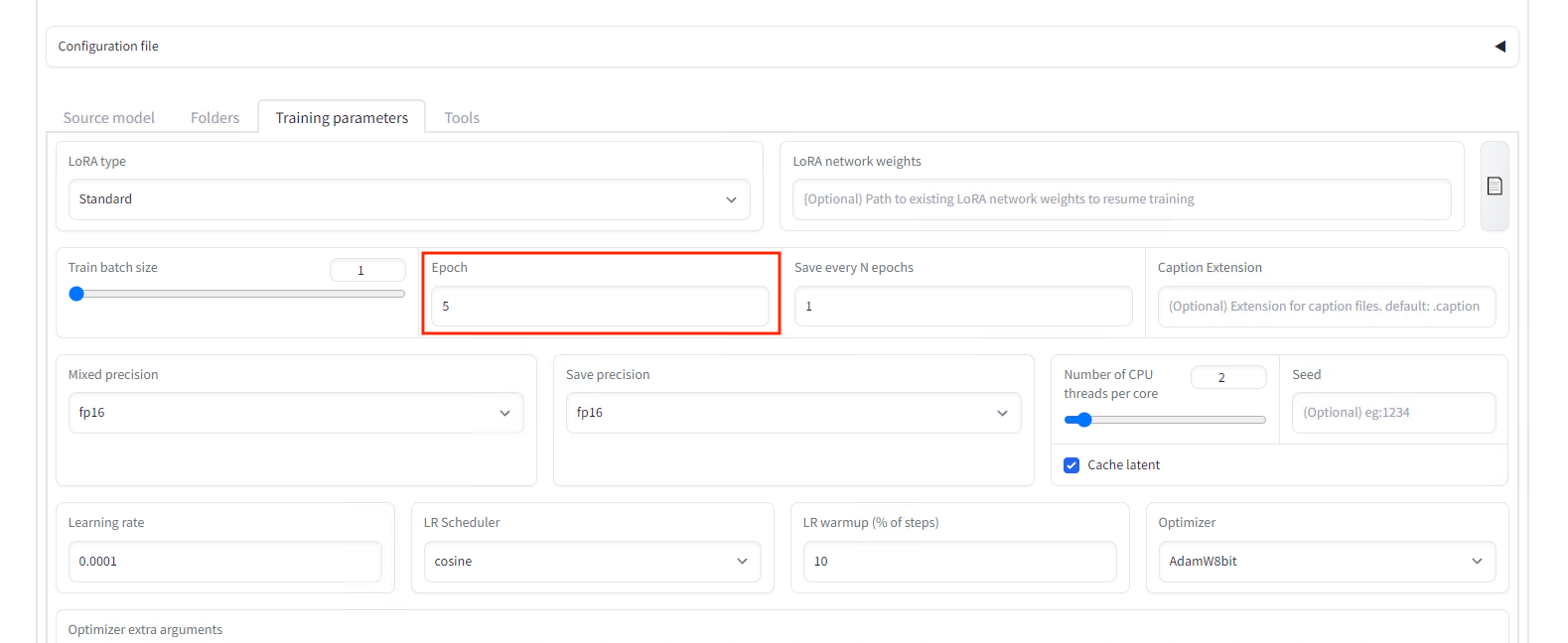
Epochsの設定
Train modelを押します。学習は10分ほどで完了します。
生成されたlast.safetensorsをStable Diffusion WebUIのmodels/LoRAにコピーして、LoRAの適用の手順で画像を生成します。
Promptにはフォルダ名のunitychanを指定します。
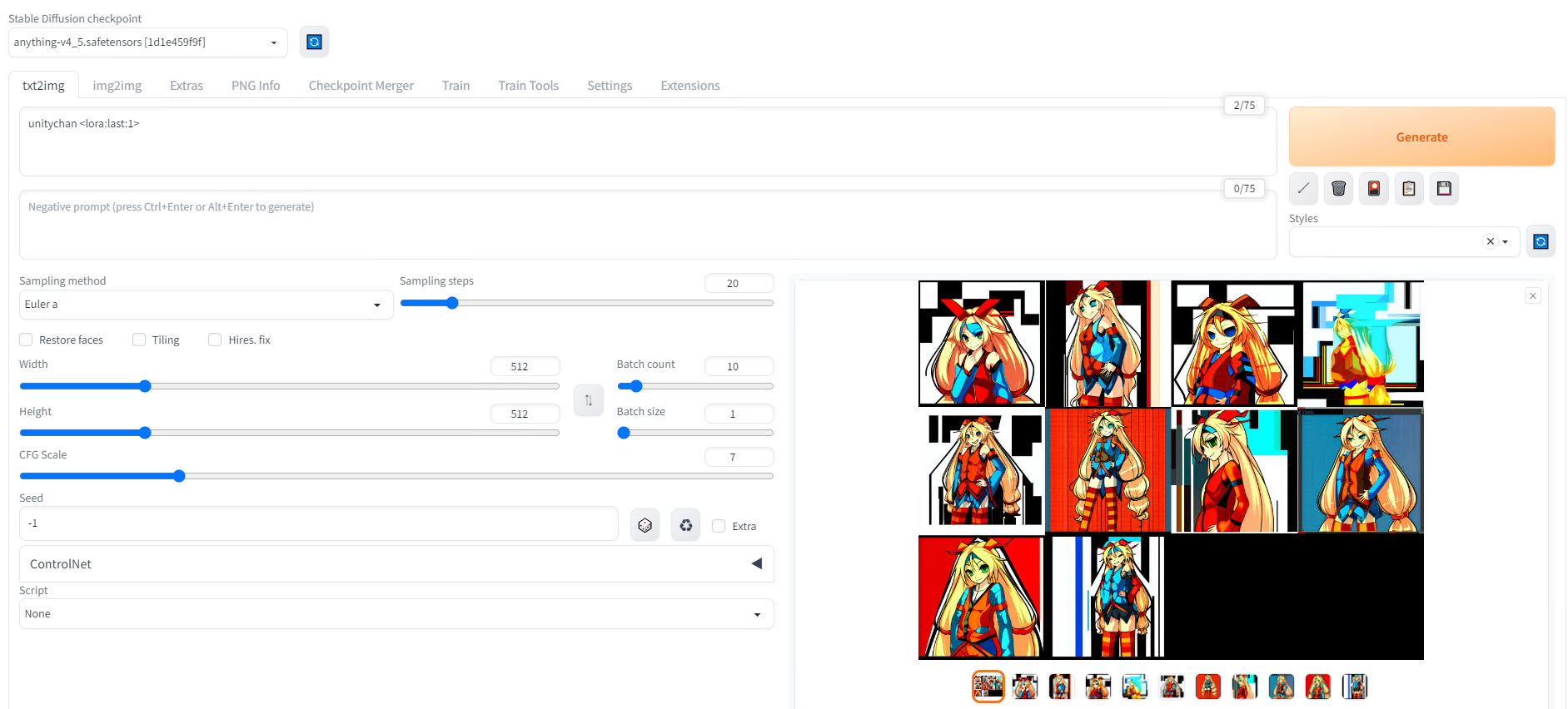
Promptの設定

生成されたUnity Chan
Unity Chanが生成できました。

ControlNetでポーズ指定
ControlNetでポーズ指定も可能です。

Promptで背景指定
Ptomptをunity_chan, on the beachにすると、海にいるUnity Chanを生成可能です。
(© Unity Technologies Japan/UCL)
まとめ
StableDiffusionとKohya’s GUIを使用することで、特定のイラストからLoRAを作成し、期待するキャラクターを生成できることを確認しました。また、ControlNetを適用して、好きなポーズのキャラクターを生成できることを確認しました。
トラブルシューティング
SdWebUITrainToolsの実行時にエラーが出る
Python3.10ではなく、Python3.9を使用している場合は下記のエラーが出ます。
def readImages(inputPath: str, level: int = 0, include_pre_level: bool = False, endswith :str | list[str] = [“.png”,”.jpg”,”.jpeg”,”.bmp”,”.webp”]) -> list[Image.Image]:
TypeError: unsupported operand type(s) for |: ‘type’ and ‘types.GenericAlias’
これは、|がPython3.10から追加された演算子なためです。その場合、Python3.10.9で環境を作り直す必要があります。環境を作り直す際は、Python3.10.9をインストールした後、stable-diffusion-webuiのフォルダにあるvenvフォルダを削除した上で、webui.batを実行します。
SdWebUITrainToolsの学習時にxformersがインストールされていないというエラーが発生する
学習時に下記のエラーが発生した場合は、webui-user.batのCOMMANDLINE_ARGSに — xformersを追加してください。train-toolsのxformersを無効にした場合、VRAMを多く消費し、cudaOutOfMemoryになるため、xformersは有効にすることが望ましいようです。
Train Tools: train.train error No xformers / xformersがインストールされていないようです
Traceback (most recent call last):
File “C:\Users\kyakuno\Desktop\stable-diffusion\stable-diffusion-webui\extensions\sd-webui-train-tools\liasece_sd_webui_train_tools\sd_scripts\library\train_util.py”, line 1672, in replace_unet_cross_attn_to_xformers
import xformers.ops
ModuleNotFoundError: No module named ‘xformers.ops’; ‘xformers’ is not a packageDuring handling of the above exception, another exception occurred:
Xformersを導入するXformersを有効化すると、画像生成速度の大幅な向上と、使用するVRAM量の大幅削減という2つの効果を得ることができます。…wikiwiki.jp
Kohya’s GUIでTypeError: argument of type ‘WindowsPath’ is not iterableというエラーが発生する
Windowsの場合下記のようにbitsandbytesのバイナリを上書きする必要があるようです。
copy .\bitsandbytes_windows\*.dll .\venv\Lib\site-packages\bitsandbytes\
copy .\bitsandbytes_windows\cextension.py .\venv\Lib\site-packages\bitsandbytes\cextension.py
copy .\bitsandbytes_windows\main.py .\venv\Lib\site-packages\bitsandbytes\cuda_setup\main.py
Kohya’s GUIのxformersでエラーが発生する
新しいxformers(0.0.18)だとエラーが発生します。
RuntimeError: xformers::efficient_attention_forward_cutlass() expected at most 8 argument(s) but received 13 argument(s). Declaration: xformers::efficient_attention_forward_cutlass(Tensor query, Tensor key, Tensor value, Tensor? cu_seqlens_q, Tensor? cu_seqlens_k, int? max_seqlen_q, bool compute_logsumexp, bool causal) -> (Tensor, Tensor)
xformersの0.0.14をインストールする必要があります。
pip install -U -I --no-deps https://github.com/C43H66N12O12S2/stable-diffusion-webui/releases/download/f/xformers-0.0.14.dev0-cp310-cp310-win_amd64.whl
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。