StableDiffusion : テキストから画像を生成する機械学習モデル
StableDiffusionはテキストから画像を生成する機械学習モデルです。学習済みモデルが公開されており、PC上で自由に画像を生成することが可能です。
StableDiffusionの概要
StableDiffusionは2022年8月に公開されたテキストから画像を生成する機械学習モデルです。テキストから画像を生成するサービスとして、DALLE2やMidjourneyが存在しますが、いずれも学習済みモデルが非公開であり、WEBサービスを経由してアクセスする必要がありました。StableDiffusionは学習済みモデルが公開されているため、PC上で自由に画像を生成することが可能です。
StableDiffusionの使用方法
WindowsでStable Diffusionを使用するには、GRiskの提供するビルド済みバイナリが便利です。
Stable Diffusion GRisk GUI.rarを解凍した後、Stable Diffusion GRisk GUI.exeを起動します。
デフォルトのパラメータでは正常な画像が生成できないため、Stepsを150、Resolutionを512に設定します。次に、Promptにテキストを入力し、Renderを実行することで画像を生成可能です。生成された画像はresultsフォルダに格納されます。
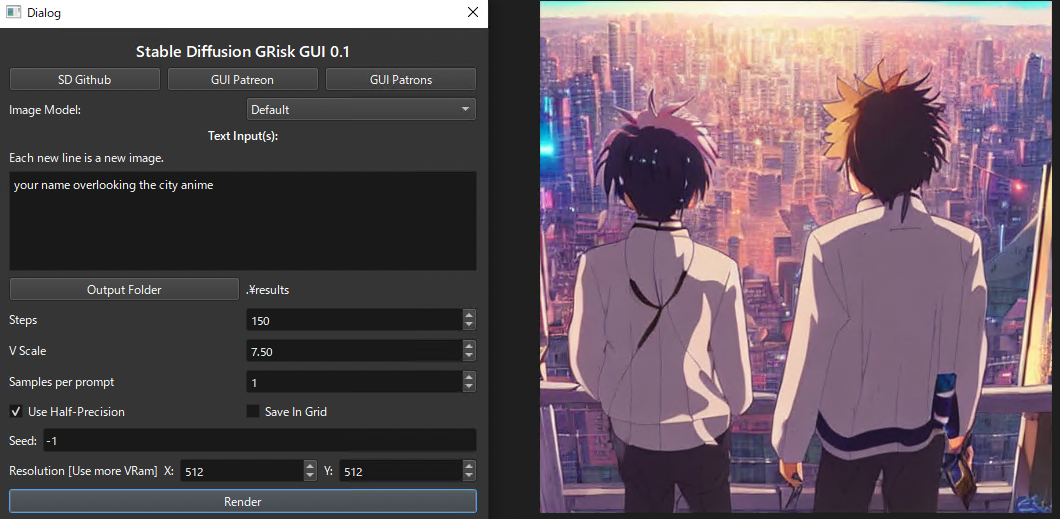
Stable Diffusion GRiskのGUIと出力の例
単語数が少ないと、テキストの特徴ベクトルが絵を構成するのに十分な情報量を持たないためか、出力が安定しない傾向にあります。そのため、できるだけ詳細に欲しい絵の情報を入力した方が良いようです。

“hastune miku standing on the mountain anime”

“your name overlooking the city anime”
RTX3080を使用した場合、32秒程度で画像を生成可能です。
StableDiffusionのデータセット
StableDiffusionはLAION-5Bデータセットで学習されています。LAION-5Bデータセットには58.5億枚の画像とテキストのペアが含まれます。
データセットの内容は下記のページから検索可能です。検索にはCLIPのEmbeddingを使用しており、CLIPが画像検索に対しても有効であることがわかります。
Clip frontClip frontClip frontrom1504.github.io
StableDiffusionでは、LAION-2Bを使用して256x256解像度で学習した後、LAION-5Bの1億7000枚の画像を使用して512x512解像度を学習しています。
StableDiffusionの学習時間
StableDiffusionはAWSのA100 (40GB VRAM)を使用して150,000時間の学習を行なっています。
StableDiffusionのアーキテクチャ
StableDiffusionでは、CLIPによるText Encoderと、UNetによるAutoEncoderを使用し、LatentDiffusionModel(拡散モデル)によってtext2imageを構築しています。
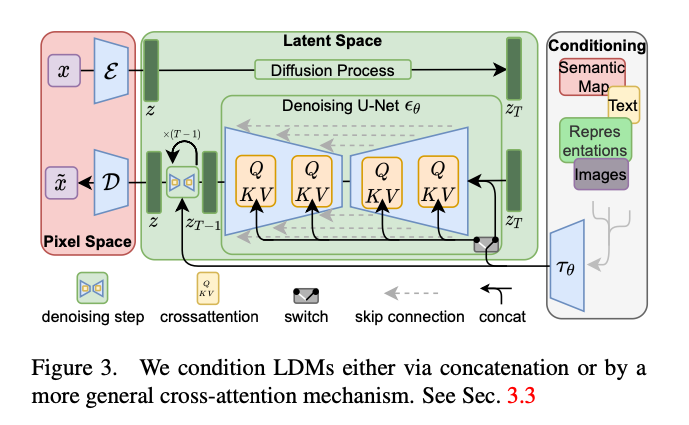
StableDiffusionのアーキテクチャ(出典:https://arxiv.org/abs/2112.10752)
画像生成のアーキテクチャはCLIP特徴と拡散モデルを使用するDALLE-2と同様です。
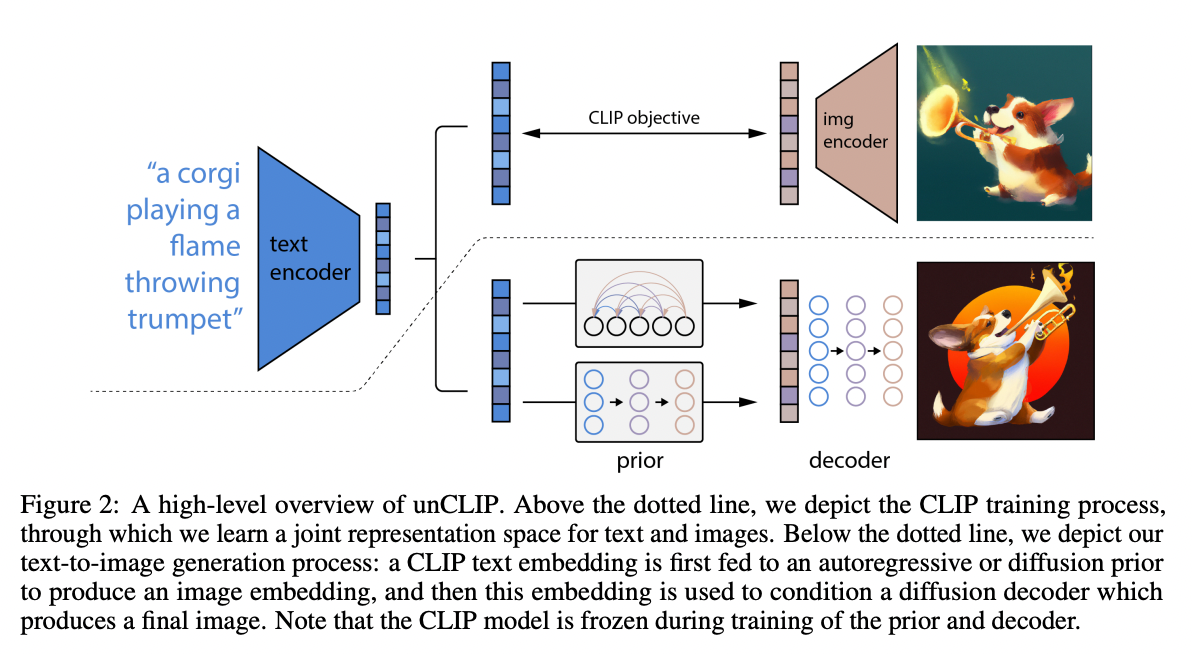
出典:https://cdn.openai.com/papers/dall-e-2.pdf
CLIPはWeb上の4億枚の画像で学習されており、任意のテキストと画像の類似度を出力することが可能です。従来のClassifierとは異なり、ラベルではなくテキストとのペアで学習しているため、未知の画像に対してもzero-shotでの画像分類を実現します。CLIPの特徴ベクトルは、画像の意味を示す情報を持っているため、画像分類のみならず、画像生成にも応用可能です。
CLIP : 超大規模データセットで事前学習され、再学習なしで任意の物体を識別できる物体識別モデルailia SDKで使用できる機械学習モデルである「CLIP」のご紹介です。「CLIP」を使用することで、任意の物体の識別を行うことが可能です。medium.com
まず、CLIPのテキストエンコーダを使用して、テキストから特徴ベクトルを取得します。単語ごとに単語ベクトルに変換した後、Transformerでテキストの意味を示す特徴ベクトルが抽出されます。
テキストエンコーダで取得した特徴ベクトルから、特徴ベクトルの空間で拡散モデルを使用して、CLIPのイメージエンコーダの特徴ベクトルに変換します。
最後に、イメージデコーダを使用して特徴ベクトルを画像に変換します。
拡散モデルでは、ノイズからスタートし、デノイズを繰り返すことで特徴ベクトルを生成します。デノイズにUNetを使用しています。
生成した画像に対して、CLIPのイメージエンコーダを適用すると、テキストに沿った特徴ベクトルが得られるため、テキストに沿った画像が生成されることになります。
GLIDEと同様にclassfier-free guidanceを使用しています。
ailia SDKからStableDiffusionを使用する
ailia SDK 1.2.14から、StableDiffusionに対応しています。下記のコマンドで画像生成が可能です。
$ python3 stable-diffusion-txt2img.py --input "a photograph of an astronaut riding a horse"
StableDiffusionの画像生成はVRAMを10GB以上使用するため、VRAMが少ない環境では、-e 0オプションを付与してCPU実行してください。
$ python3 stable-diffusion-txt2img.py --input "a girl" -e 0
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。