ST-GCN : 骨格から人物のアクションを検出する機械学習モデル
ailia SDKで使用できる機械学習モデルである「ST-GCN」のご紹介です。エッジ向け推論フレームワークであるailia SDKとailia MODELSに公開されている機械学習モデルを使用することで、簡単にAIの機能をアプリケーションに実装することができます。
ST-GCNの概要
ST-GCNは2018年1月に提案されたモデルで、OpenPoseなどで取得した骨格情報から人物のアクションを検出する機械学習モデルです。
NTU RGB-DもしくはKineticsデータセットで学習されており、下記の60カテゴリのアクションを検出可能です。
The dataset consists of 60 labelled actions. Specifically: drink water, eat meal/snack, brushing teeth, brushing hair, drop, pickup, throw, sitting down, standing up (from sitting position), clapping, reading, writing, tear up paper, wear jacket, take off jacket, wear a shoe, take off a shoe, wear on glasses, take off glasses, put on a hat/cap, take off a hat/cap, cheer up, hand waving, kicking something, put something inside pocket / take out something from pocket, hopping (one foot jumping), jump up, make a phone call/answer phone, playing with phone/tablet, typing on a keyboard, pointing to something with finger, taking a selfie, check time (from watch), rub two hands together, nod head/bow, shake head, wipe face, salute, put the palms together, cross hands in front (say stop), sneeze/cough, staggering, falling, touch head (headache), touch chest (stomachache/heart pain), touch back (backache), touch neck (neckache), nausea or vomiting condition, use a fan (with hand or paper)/feeling warm, punching/slapping other person, kicking other person, pushing other person, pat on back of other person, point finger at the other person, hugging other person, giving something to other person, touch other person’s pocket, handshaking, walking towards each other and walking apart from each other.
ST-GCNの入力と出力
入力は(1, 3, 300, 18, 2)となっており、(batch, channel, frame, joint, person)が対応します。channel=0が-0.5〜0.5で正規化された骨格のx座標、channel=1が骨格のy座標、channel=2がconfidence値となっています。jointは骨格の番号です。personは人物1と人物2になっています。
出力は(batch,class,output_frame,joint,person)のconfidence値となります。アクションを検出するには、classごとにconfidence値を積算し、もっとも大きいclassを選択します。output_frameは入力のフレーム数/4となります。
voting_label = output.sum(axis=3).sum(axis=2).sum(axis=1).argmax(axis=0)
同時に出力されるfeatureはどのキーポイントが貢献したかを可視化するためのものであり、ビジュアライズのみに使用します。
ST-GCNのアーキテクチャ
ST-GCNではグラフコンボリューションを使用しています。隣接する骨格の位置関係の時間推移からアクションを推定します。
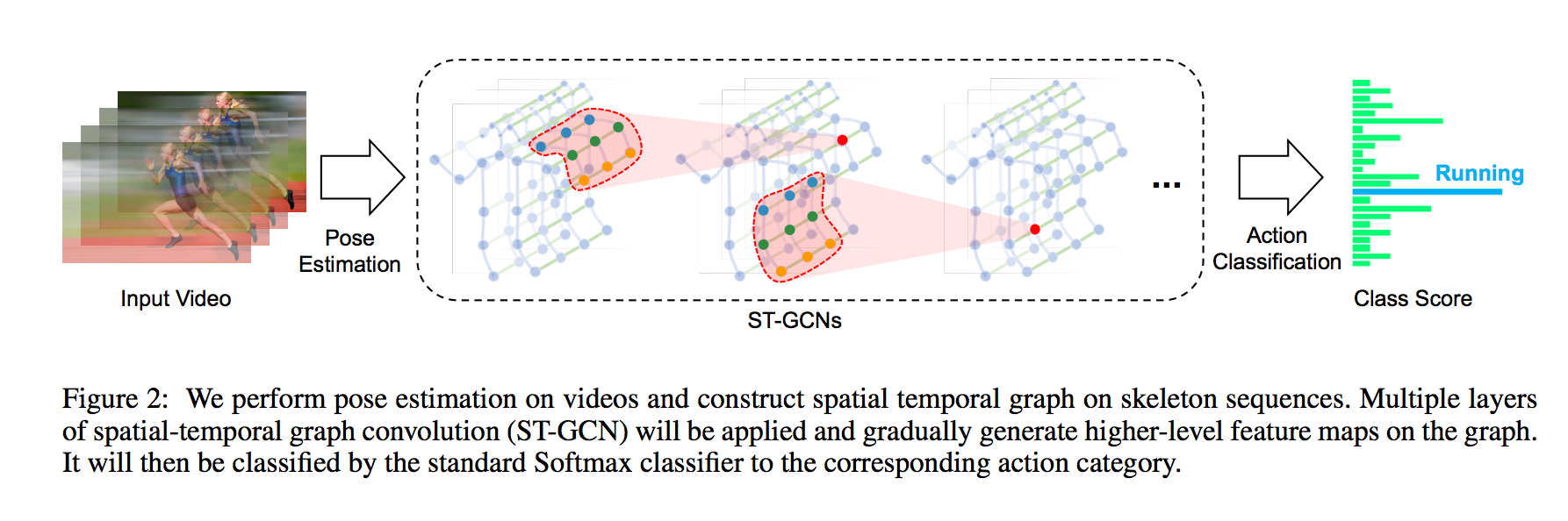
出典:https://arxiv.org/pdf/1801.07455.pdf
グラフコンボリューションは、ノード間のつながり情報を元に畳み込みを行います。例えば、ノードAにノードBとノードCが接続されている場合、A、B、Cの値に対して畳み込みを行います。これにより、3Dモデルの頂点情報などに対しても機械学習を適用可能になります。グラフコンボリューションは従来のコンボリューションの上位概念にあたり、メッシュ状にノードを接続すると、従来のコンボリューションと等価な演算となります。
ST-GCNは従来の3D Convolutionによるアクション検出に比べて、骨格の情報のみからアクションを推定可能なため、より高速に動作します。また、骨格の情報のみを単に2D Convolutionにかけるよりも、グラフコンボリューションによって骨格のキーポイント間の関係を考慮した畳み込みを行えるため、より高精度になります。
ST-GCNは(batch,channel,fame,joint,person)の5次元を入力とし、NTU-RGB+Dを使用したモデルだと(1,3,300,18,2)を入力とします。
ST-GCNはNTU-RGB+Dにおいて高い性能を発揮します。
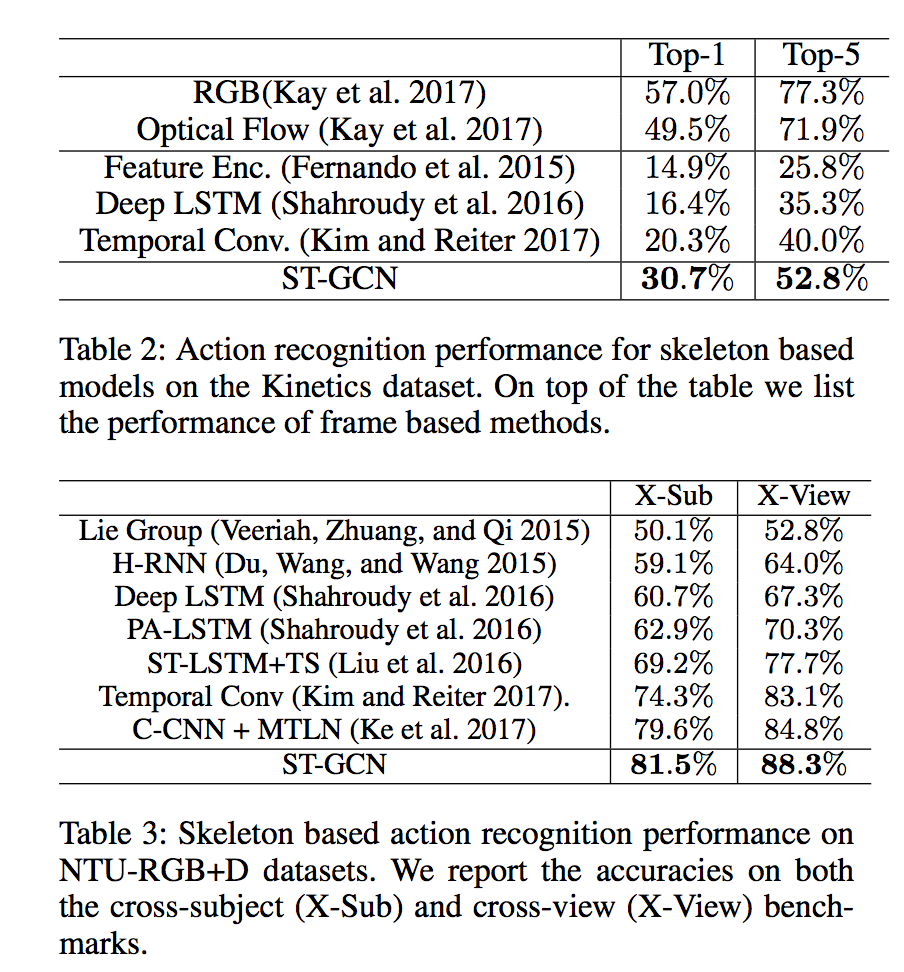
出典:https://arxiv.org/pdf/1801.07455.pdf
現在のSOTAは下記で確認できます。
ST-GCNは推論時も5次元でテンソルを扱う必要があり、5次元テンソルに対応しているフレームワークが必要です。また、einsumオペレータを使用しており、ONNXのopset=12を使用するか、対応オペレータへの書き換えが必要です。
ST-GCNのデータセット
ST-GCNはNTU RGB+Dの3D skeletons (5.8GB)もしくはKineticsのアクション動画データセットからOpenposeでスケルトンを抽出したデータセット(7.5GB)を使用して学習しています。
学習に使用するデータとラベルはyamlファイルで指定します。
独自のデータセットでの学習
kinetics_trainフォルダにはポーズのキーポイントが含まれるjsonデータが含まれています。独自のデータセットで学習する場合は、このjsonと同等のファイルをOpenPoseなどを使用して作成します。
skeletonのposeには18のキーポイントが、xyxy順で格納されています。また、scoreにはconfidence値が格納されています。動画に複数人含まれることを考慮して、skeletonは配列になっています。frame_indexは1から開始します。なお、dataは300フレーム以下である必要があります。
{“data”: [{“frame_index”: 1, “skeleton”: [{“pose”: [0.518, 0.139, 0.442, 0.272, 0.399, 0.288, 0.315, 0.400, 0.350, 0.549, 0.487, 0.264, 0.507, 0.356, 0.548, 0.408, 0.413, 0.584, 0.401, 0.785, 0.383, 0.943, 0.497, 0.582, 0.485, 0.750, 0.479, 0.908, 0.514, 0.119, 0.000, 0.000, 0.483, 0.128, 0.000, 0.000], “score”: [0.305, 0.645, 0.647, 0.865, 0.841, 0.505, 0.361, 0.726, 0.487, 0.708, 0.546, 0.575, 0.695, 0.713, 0.343, 0.000, 0.395, 0.000]}]}, {“frame_index”: 2, “skeleton”: [{“pose”: [0.516, 0.155, 0.438, 0.272, 0.395, 0.288, 0.315, 0.405, 0.352, 0.552, 0.483, 0.261, 0.505, 0.351, 0.548, 0.416, 0.413, 0.590, 0.401, 0.791, 0.383, 0.946, 0.499, 0.587, 0.487, 0.750, 0.481, 0.910, 0.516, 0.136, 0.000, 0.000, 0.495, 0.141, 0.000, 0.000], “score”: [0.249, 0.678, 0.624, 0.838, 0.858, 0.506, 0.293, 0.706, 0.471, 0.728, 0.567, 0.566, 0.665, 0.719, 0.367, 0.000, 0.593, 0.000]}]}, …, “label”: “jumping into pool”, “label_index”: 172}
ラベル情報はkinetics_train_label.jsonに記載されています。キーがファイル名となり、上記のポーズ情報を読み込みにいきます。label_indexは0から始まります。
“ — -QUuC4vJs”: {
“has_skeleton”: true,
“label”: “testifying”,
“label_index”: 354
},
“ — 3ouPhoy2A”: {
“has_skeleton”: true,
“label”: “eating spaghetti”,
“label_index”: 116
},
学習を行う場合、上記のjsonからnpyファイルを生成します。
python3 tools/kinetics_gendata.py — data_path /dataset/kinetics-skeleton — out_folder /dataset/kinetics-skeleton
学習を行います。
python3 main.py recognition -c ../train_kinetics.yaml — use_gpu False
学習時のDataLoaderにdrop_last=Trueが指定されているため、データ量が少ないとLossがNaNになります。そのような場合、設定のyamlファイルのbatch_sizeを1にします。
ONNXへのエクスポート
net/utils/tgcn.pyに含まれるeinsumを置き換える必要があります。
#x = torch.einsum(‘nkctv,kvw->nctw’, (x, A))
x = x.permute(0, 2, 3, 1, 4).contiguous()
n, c, t, k, v = x.size()
k, v, w = A.size()
x = x.view(n * c * t, k * v)
A = A.view(k * v, w)
x = torch.mm(x, A)
x = x.view(n, c, t, w)
また、RuntimeError: Failed to export an ONNX attribute ‘onnx::Gather’, since it’s not constant, please try to make things (e.g., kernel size) static if possibleが発生するため、st_gcn.pyを書き換えます。
#x = F.avg_pool2d(x, x.size()[2:])
x = F.avg_pool2d(x, (75,18))
上記の変更を行うと、下記のコードでエクスポート可能です。extract_feature関数がエクスポート対象です。
self.model.eval()
class ExportStgcnModel(torch.nn.Module):
def __init__(self, model):
super(ExportStgcnModel, self).__init__()
self.model = model
def forward(self, x):
return self.model.extract_feature(x)from torch.autograd import Variable
x = Variable(torch.randn(1, 3, 300, 18, 2)) # (1, channel, frame, joint, person)
output = self.model(x)
export_model = ExportStgcnModel(self.model)
torch.onnx.export(export_model, x, ‘st-gcn_pytorch.onnx’, verbose=True, opset_version=10)
torch 1.6.0では内部の最適化処理で下記のエラーが発生するため、エクスポートにはtorch 1.5.0を使用する必要があります。
# File “/usr/local/lib/python3.7/site-packages/torch/onnx/utils.py”, line 409, in _model_to_graph
#_export_onnx_opset_version)
#RuntimeError: expected 1 dims but tensor has 2
ST-GCNの使用方法
ailia SDKでST-GCNを使用するには、下記のコマンドを使用します。WEBカメラの入力に対してOpenPoseで骨格を検出し、アクションを推定します。
python3 st-gcn.py -v 0
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。