SigLIP2 : 次世代の0ショット物体識別モデル
次世代の0ショット物体識別モデルであるSigLIP2の紹介です。CLIPの後継として活用が広がっています。
SigLIP2の概要
SigLIP2はGoogle DeepMindが2025年2月に発表した0ショットの物体識別モデルです。入力された画像に対して、入力したテキストの物体かどうかの確率値を出力することが可能です。この分野ではCLIPが広く使用されていますが、CLIPとは異なりラベル単位で学習しており、安定性が向上しています。2021年のCLIP、2024年のSigLIP、2025年のSigLIP2という形で発展しています。
CLIPについて
CLIPは、任意のテキストラベルで、物体識別ができる0ショットのモデルです。
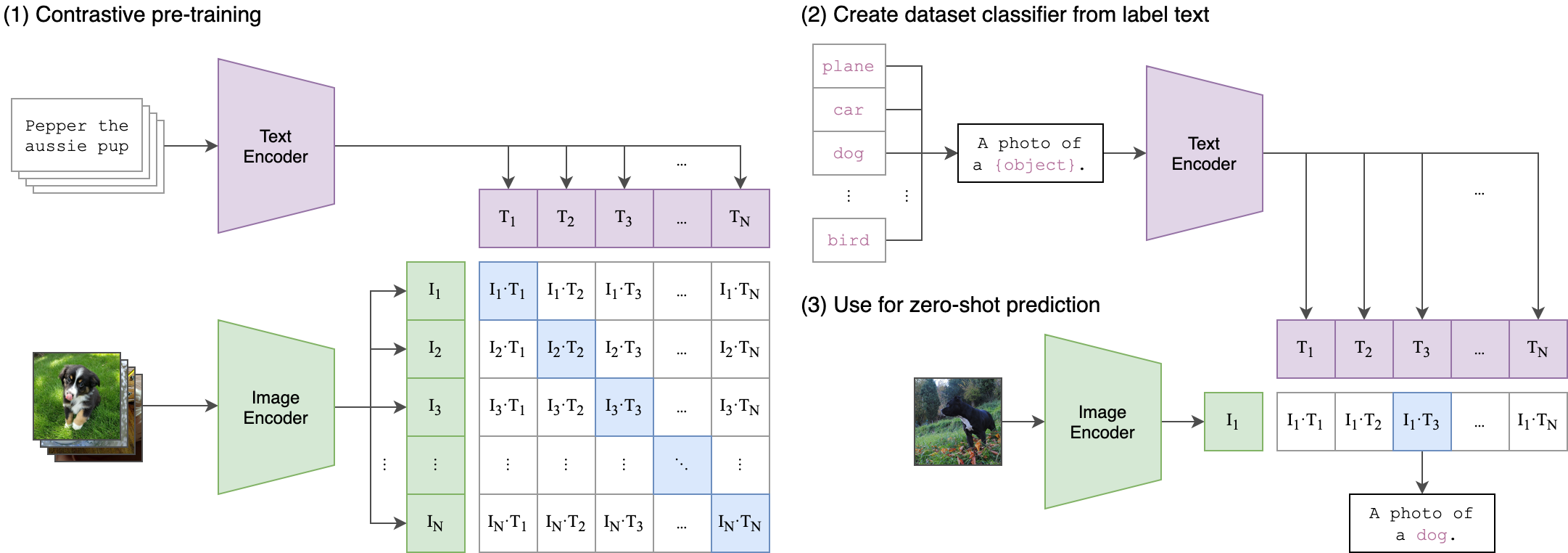
CLIPの概要(出典:https://github.com/openai/CLIP)
CLIPは、対応するテキストが正解である確率を計算した後、Softmaxを適用し、交差エントロピー損失で学習しています。そのため、入力するテキストの組み合わせに依存して学習されています。
SigLIPについて
SigLIPは、SoftmaxをSigmoidに置き換え、多クラス分類問題ではなく、「この画像とこのテキストは対応しているか?」の2値分類問題を解きます。そのため、入力するテキストの組み合わせに依存せず、テキスト単位で独立して学習されています。これにより、大規模バッチサイズが不要で、損失が安定しやすく、学習を単純で扱いやすくしています。

SigLIPのSigmoid Loss(出典:https://arxiv.org/abs/2303.15343)
SigLIPは、ImageNet-1kの0ショット分類タスクでCLIPよりも高い性能を持ちます。
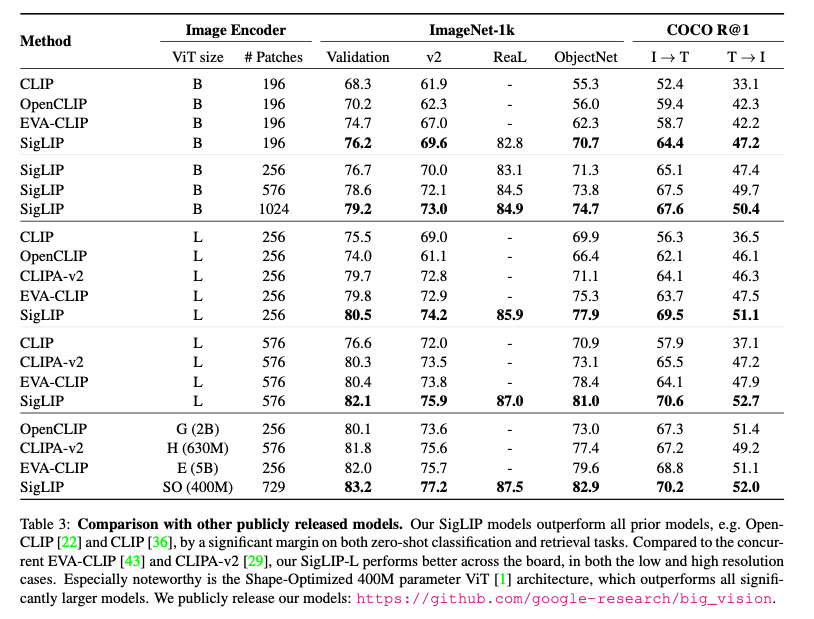
SigLipの性能(出典:https://arxiv.org/abs/2303.15343)
SigLIP2について
SigLIP2は、SigLIPの学習を改良することで高精度化したモデルです。SigLIP2のモデルアーキテクチャはSigLIPと後方互換性があり、ウエイトとトークナイザの置き換えだけで使用可能です。
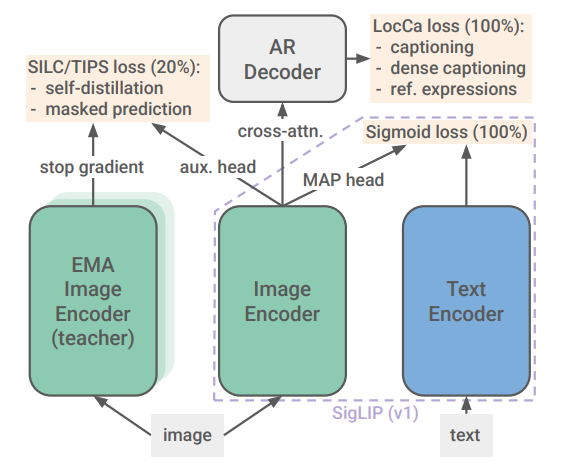
SigLIP2の構成(出典:https://arxiv.org/abs/2502.14786)
SigLIPのトークナイザはSentence PieceベースのSigLipProcessorでしたが、SigLIP2ではGemma Tokenizerが使用されています。
SigLIPとSigLIP2の精度比較です。SigLIP2はSigLIPに比べて大幅に性能が向上しています。mSigLIPはSigLIP2のマルチリンガル版になります。
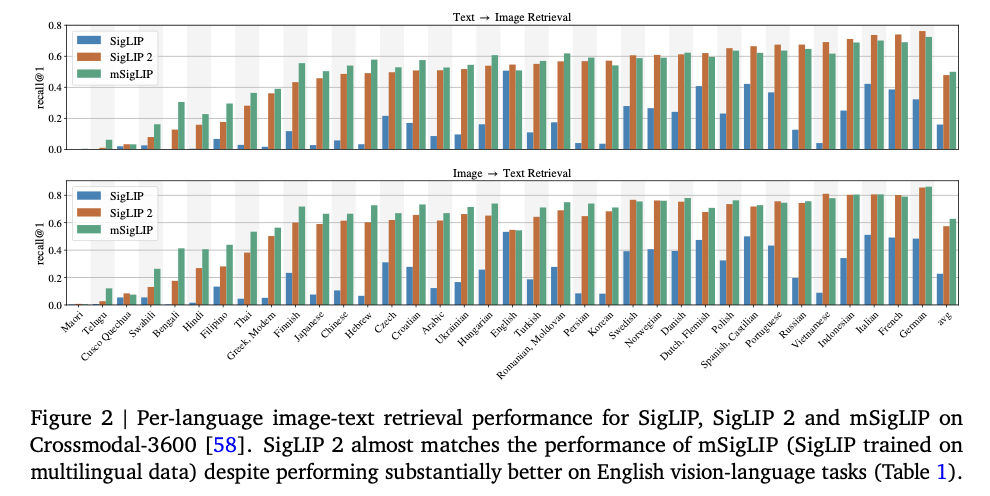
SigLip2の精度改善
SigLip2をailia SDKから使用する
ailia SDKからSigLip2を使用するには下記のコマンドを使用します。
$ python3 siglip2.py -i demo.jpg --text "2 cats" --text "a plane" --text "a remote" --text "3 dogs"
入力画像です。

出典:http://images.cocodataset.org/val2017/000000039769.jpg
{kind=link}
出力値です。
1: 2 cats - 65.41%
2: 3 dogs - 32.62%
3: a remote - 1.05%
4: a plane - 0.92%
SigLipの応用
SigLipはGoogleのVLMであるGemma3のVision Encoderとして使用されています。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。