SegmentAnything : セグメンテーションの対象を座標で指定できるセグメンテーションモデル
セグメンテーションの対象を座標で指定できるセグメンテーションモデルであるSegmentAnythingのご紹介です。
SegmentAnythingの概要
SegmentAnythingはMetaが開発したセグメンテーションモデルです。2023年4月に公開されました。任意の座標を指定して、その周辺領域をセグメンテーションすることが可能です。背景切り抜きなどの画像編集に最適です。
Segment Anythingのアーキテクチャ
近年、WEB上の大量のデータで学習することで、従来よりも飛躍的に高精度な言語モデルや基盤モデルが登場しています。しかし、セグメンテーションのための大規模なデータセットは存在しませんでした。Segment Anythingでは、1100万枚以上の画像と、10億以上のマスクを含む大規模なデータセットを新規に構築することで、セグメンテーションの基盤モデルを構築しています。
Segmeny Anythingでは、この新しい大規模なデータセットで学習することで、位置やボックス、テキストなどをPromptとしたセグメンテーションを実現しています。
Segment Anythingのアーキテクチャです。Image EncoderでEmbeddingに変換した後、Promptを元にMask Decoderでセグメンテーションを生成します。Image encoderにはViT、Prompt EncoderにはCLIPのText Encoder、Mask DecoderはTransformerとMLPを使用しています。
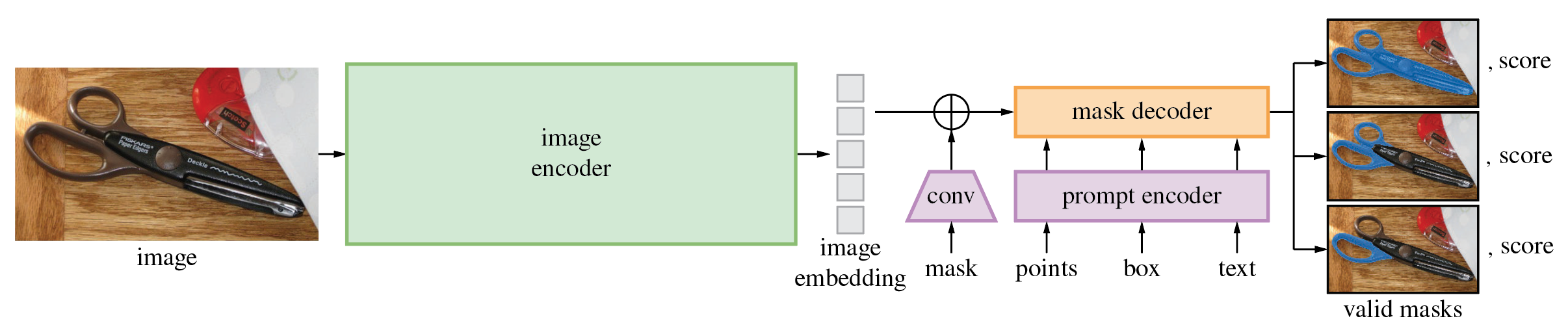
SegmentAnythingのアーキテクチャ(出典:https://github.com/facebookresearch/segment-anything)
ボックスを元にセグメンテーションした例です。指定したボックスの中にあるタイヤだけをセグメンテーションすることが可能です。

座標を指定したセグメンテーション(出典:https://github.com/facebookresearch/segment-anything)
Image Encoderの出力は画像に対して一意なため、一度、Image EncoderでEmbeddingを計算すれば、Mask Decoderは座標を変えながら複数回実行することが可能です。演算負荷はImage Encoderの方が高く、Mask Decoderは比較的軽量となっています。
デフォルトでは、長辺が1024になるようにリサイズされてから、Image Encoderに入力されます。前処理はImageNet形式で、meanを引いてからstdで除算します。画像はRGB順です。
Mask Decoderの出力は複数のマスクとなっており、デフォルトでは最もスコアの高いマスクが選択されます。
SegmentAnythingの応用
物体検出や骨格検出と併用し、セグメンテーション対象を自動選択して処理を行うことで、レイヤー分けの自動化などに応用が可能です。
SegmentAnythingの使用方法
ailia SDKでは1.2.16からSegmentAnythingに対応しています。SegmentAnythingを使用するには、下記のコマンドを使用します。
$ python3 segment-anything.py - input intput.jpg - savepath output.jpg
guiオプションを付与することで、画像をクリックした場所をインタラクティブにセグメンテーションすることも可能です。
$ python3 segment-anything.py --gui

タイヤをクリック

車をクリック
様々な画像でのテスト
SDXLで生成した画像に対して、GUIモードで背景や人物をクリックしてテストしてみます。

背景を選択

人物を選択

背景を選択

キャラクターを選択
(© Unity Technologies Japan/UCL)
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。