PytorchDcTts : テキストから音声合成を行う機械学習モデル
ailia SDKで使用できる機械学習モデルである「PytorchDcTts」のご紹介です。エッジ向け推論フレームワークであるailia SDKとailia MODELSに公開されている機械学習モデルを使用することで、簡単にAIの機能をアプリケーションに実装することができます。
PytorchDcTtsの概要
PytorchDcTts(Pytorch Deep Convolutional Text-to-Speech)は2017年10月に公開された機械学習モデルです。テキストを入力して音声ファイルを出力することができます。
PytorchDcTtsのアーキテクチャ
音声合成のタスクでは、一般的にRNN(再帰的ニューラルネットワーク)が使用されますが、学習に時間がかかるという問題があります。この問題に対して、PytorchDcTtsはCNNで音声合成を構成することで、一般的なゲーミングPCで15時間程度で学習できるようにしています。
ディープラーニングを使用しない音声合成は、複数のコンポーネントを使用した複雑なシステムでした。例えば、text analyzer、F0 generator、spectrum generator、pause estimator、vocodarの組み合わせになります。
ディープラーニングによって、これらの複数のコンポーネントはend-to-endの1つのモデルに集約され、inputからoutputをダイレクトに計算可能にします。
PytorchDcTtsのモデルアーキテクチャは下記となります。TextEncでInput Textをベクトル化、AttentionでTextとMelspectrogramのペアを算出して重み付け、AudioDecでMelspectrumを計算、SSRN(Spectrogram Super-resolution Netrowk)で音声の品質改善を行います。
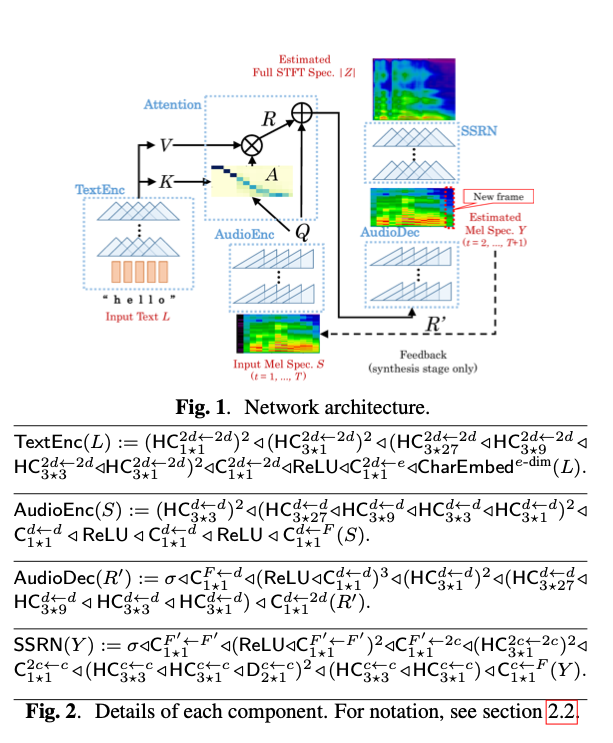
出典:https://arxiv.org/pdf/1710.08969
音声合成の例です。上から、Attention、mel spectrogram、linear STFT spectrogramです。
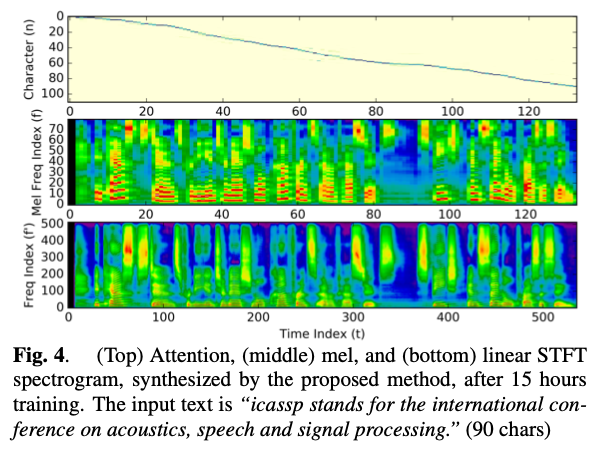
出典:https://arxiv.org/pdf/1710.08969
学習用のデータセットとしてLJ Speech Datasetを使用します。これは、13Kのテキストとスピーチのペアのデータセットです。合計で24時間のデータ量があります。
PytorchDcTtsの使用方法
下記のコマンドで任意のテキスト(英語)からwavファイルを出力することができます。
python3 pytorch-dc-tts.py -i "Hello world" -s output.wav
実行例は下記です。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。