ONNX : 公式オプティマイザの限界と自力最適化
エッジ向け推論フレームワークであるailia SDKではONNXを使用してGPUを使用した高速な推論を行うことができます。この記事では、ailia SDKの開発の過程で得られたONNXのモデル最適化の知見を紹介します。
前回記述したように ONNX 公式のオプティマイザを使うことで ONNX 形式モデルの推論向け最適化を行うことが可能なのですが、残念なことに ONNX 公式オプティマイザは万能ではありません。
ONNX 公式オプティマイザには、入力モデルによってはエラーで処理を中断したり、壊れたモデルファイルを出力することがあります。 この不具合は GitHub で issue [1 | 2] も作成されているのですが、長期間放置されています。
今回は ONNX 形式モデルの最適化を ONNX 公式オプティマイザを利用せずに行うとしたら、どうすればよいかを解説します。
今回の最適化対象
ONNX Model Zoo にある sufflenet v2 の最適化を考えます。このモデルに対して ONNX 公式オプティマイザで最適化を行うと、次のエラーが表示され最適化に失敗します。
Traceback (most recent call last):
File "official_optimize.py", line 41, in <module>
model = onnx.optimizer.optimize(model, ['fuse_bn_into_conv'] )
File "C:\opt\Python36\lib\site-packages\onnx\optimizer.py", line 55, in optimize
optimized_model_str = C.optimize(model_str, passes)
IndexError: invalid unordered_map<K, T> key
このモデルを python スクリプトのみで onnx.optimizer を利用せずに最適化することを考えます。
最適化スクリプト
sufflenet に対してそのまま適用可能な最適化スクリプトは次のリンクから取得可能です。
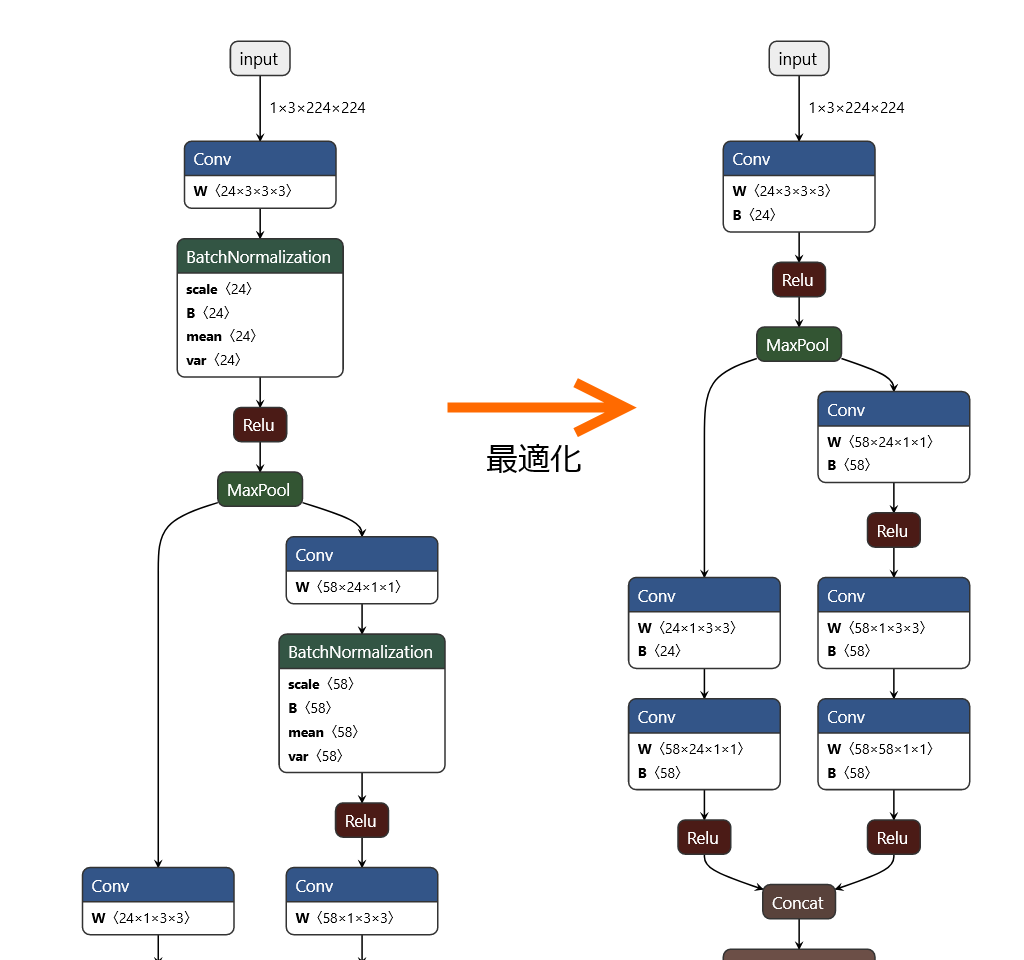
このスクリプトを実行すると、次の最適化前後の画像のように BatchNormalization を Conv に還元して最適化することができます。
動作確認環境
このスクリプトは次の環境で動作確認を行いました。
- Windows 10
- Python 3.6.6
- numpy 1.18.1
- onnx 1.6.0
- sufflenet v2 2019/3/10 版
最適化処理基本構成
python スクリプトで ONNX 形式モデルの最適化を行う場合、基本的な処理の流れは次の形になります。
- ONNX 形式モデルを読み込む
- 読み込んだモデルのノード構成やパラメータを変更する
- 変更したノード構成とパラメータを元に新しいモデルを作成する
- 変更後のモデルを保存する
1番目と4番目の ONNX 形式モデルの読み込みと保存には python の onnx ライブラリで提供されている機能を利用します。3番目の新しいモデルの作成には python の onnx.helper ライブラリの機能を利用します。
2番目のノード構成とパラメータの変更が最適化処理の実体です。ここでBatchNormalization のパラメータと Conv のパラメータの変換処理を行うのですが、この演算には python の numpy ライブラリを使います。
ただし、 onnx ライブラリでロードしたモデルのパラメータは onnx.TensorProto という形式で読み込まれています。これは直接 numpy の ndarray 形式として扱うことができません。TensorProto と ndarray の相互変換を行い numpy での演算が可能にするために onnx.numpy_helper ライブラリを利用します。
これらの ONNX が提供しているライブラリ API の詳細は ONNX の Python API Overview ドキュメントに記述されています。
BatchNormalization の Conv への還元
BatchNormalization には次のパラメータが存在します。
- scale
- bias
- mean
- var
Conv には次のパラメータが存在します。
- weight
- bias
BatchNormalization の実際の演算は次の疑似コードで示す内容です。
このコードは次の形に変更することが可能です。
上記疑似コードで [A] / [B] として示した scale_dash / bias_dash は Conv のパラメータの weight / bias に次のように還元することが可能です。
C/C++ 風味の疑似コードで記述すると上の形になりますが、python の numpy には要素単位処理とブロードキャストという機能があるのでより簡潔に記述することができます。python 風味の疑似コードで同じ処理を書くと次の形になります。
BatchNormalization のパラメータを Conv のパラメータに変換する処理はこれだけです。後は次の処理を行えばノード&パラメータの書き換え処理は完了です。
- 変更したパラメータを Initialier としてモデルに埋め込む
- 利用しなくなったパラメータを Initializaer から削除する
- 埋め込んだ Initializer を参照するように当該 Conv を書き換える
- 不要になった BatchNormalization を削除する
- 削除した BatchNormalization の出力を参照している入力を、Conv の出力を参照するように書き換える
こうした処理と、これらに付随する細々とした処理を行うのが、今回の最適化スクリプトです。あらためてリンクを提示します。
今回の最適化の効果
残念ながら最適化前後のモデルで ONNX Runtime を利用して推論を回してみたのですが、元々のモデルが十分高速なためか、実行時間に差を観測することができませんでした。このため、最適化の効果は省略します。
最適化前後のモデルで推論結果が変化しないことは確認しており、Netron でモデルの変換が意図通りに行われていることも確認できているため問題ないと判断しています。
まとめ
このように、ONNX 公式オプティマイザでエラーとなり最適化できない ONNX 形式モデルであっても、python の onnx ライブラリが提供する helper 機能を利用し個別にモデルを書き換えることで ONNX 公式オプティマイザと同じ最適化を行うことができます。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。