Multilingual E5 : 多言語のテキストをEmbeddingする機械学習モデル
多言語のテキストをEmbeddingする機械学習モデルであるMultilingual E5のご紹介です。Multilingual E5を使用することで、多言語間のテキストの類似度を高精度に計算可能です。
Multilingual E5の概要
Multilingual E5は2022年12月に公開されたテキストのEmbeddingを行うモデルです。従来、オンプレミス環境での多言語の埋め込みでは2019年に公開されたSentenceTransformerのparaphrase-multilingual-mpnet-base-v2が使用されていましたが、Multilingual E5はそれよりも最新の高精度なモデルになります。
Multilingual E5のアーキテクチャ
テキストのEmbeddingはキーワードの不一致の問題を解消し、効率的な情報検索を可能にします。しかし、従来のモデルは、限定的なラベル付きデータや、低品質な機械翻訳のデータで学習されていたため、十分な精度が得られていませんでした。
E5では、CCPairsデータセットと呼ばれる、インターネット上のテキストペアをクリーニングしたデータセットで学習します。CCPairsデータセットは、CommunityQA、CommonCrawl、ScientificPapersなどのデータソースを組み合わせた後、フィルタリングを行なって構築します。
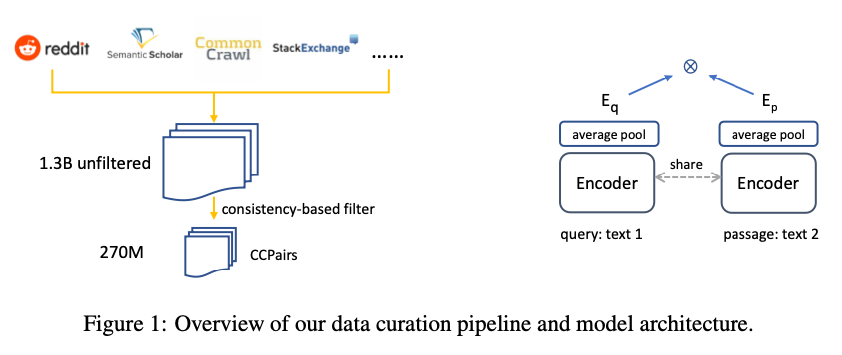
CCPairsデータセットの概要
Multilingual E5のデータセット
実際のMultilingual E5のデータセットは下記となります。
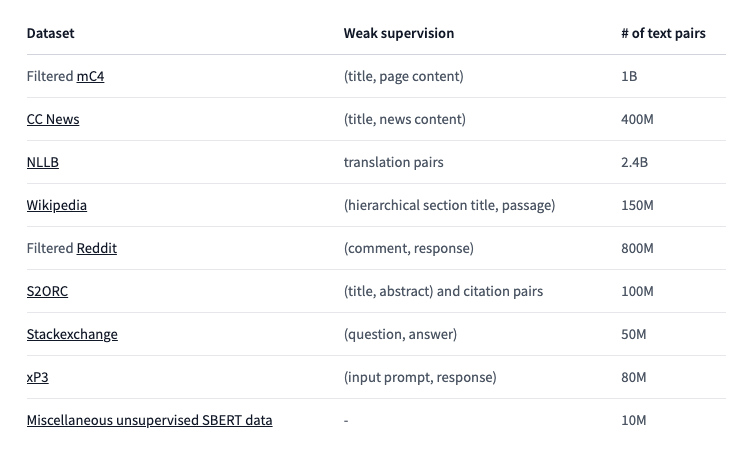
https://huggingface.co/intfloat/multilingual-e5-base
従来のSentenceTransformerのparaphrase-multilingual-mpnet-base-v2のデータセットはSTSb(Semantic Textual Similarity Benchmark)となります。Multilingual E5は、より多くのデータで学習されていることがわかります。

paraphrase-multilingual-mpnet-base-v2
SentenceTransformerとMultilingual E5の互換性
Multilingual E5の埋め込みの次元数はbaseで768、largeで1024です。トークナイザにはXLMRobertaが使用されており、SentenceTransformerと全く同じSentencePieceのモデルファイルが使用されているため、トークナイザはそのままで、モデルを差し替えるだけで、SentenceTransformerをE5に置き換えることが可能です。
Multilingual E5の制約
Multilingual E5の入力可能なトークン長は最大で512となります。これを超えると推論時にエラーになります。OpenAIのtext-embedding-ada-002の最大のトークン長は8191であるため、これよりも短いことに注意する必要があります。
Multilingual E5の使用方法
ailia SDKでMultilingual E5を使用するには下記のようにします。
$ python3 multilingual-e5.py -i sample.txt
sample.txtから各行をEmbeddingし、入力したQueryに最も近いテキストを表示します。
Unityからの使用
下記にUnityからMultilingual E5を使用するサンプルがあります。ailia SDKを使用し、PC上でクエリと文章の関連度を計算することで、サーバレスでlangchainやllama-indexのようなRAGを実装可能です。
QueryとQueryに対応する検索結果
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。