Llama3の論文を読む
世界最高レベルのLLMであるLlama3の論文には、最新のLLMの研究に関する知見が多く含まれています。本記事では、Llama3の論文で興味深かった点を紹介します。
Llama3について
Llama3はMetaが開発し、2024年7月に公開された世界最高レベルのLLMです。Llama3の論文には、最先端の性能を持つLLMの開発方法が記載されています。

出典:https://arxiv.org/abs/2407.21783
モデルパラメータ
Llama3には、8B、70B、405Bの3つのモデルがあります。
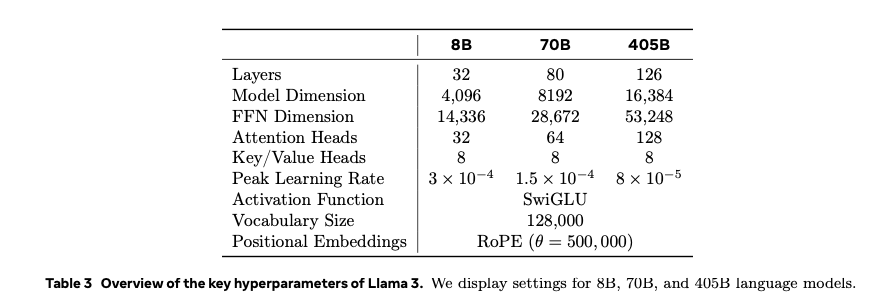
P.7
本論文では、Llama3.1をLlama3と呼んでいます。Llama3.1では、Multilingual、Long context、Tool useに対応しています。

P.2
Llama3は非常に高いベンチマークスコアを達成しています。
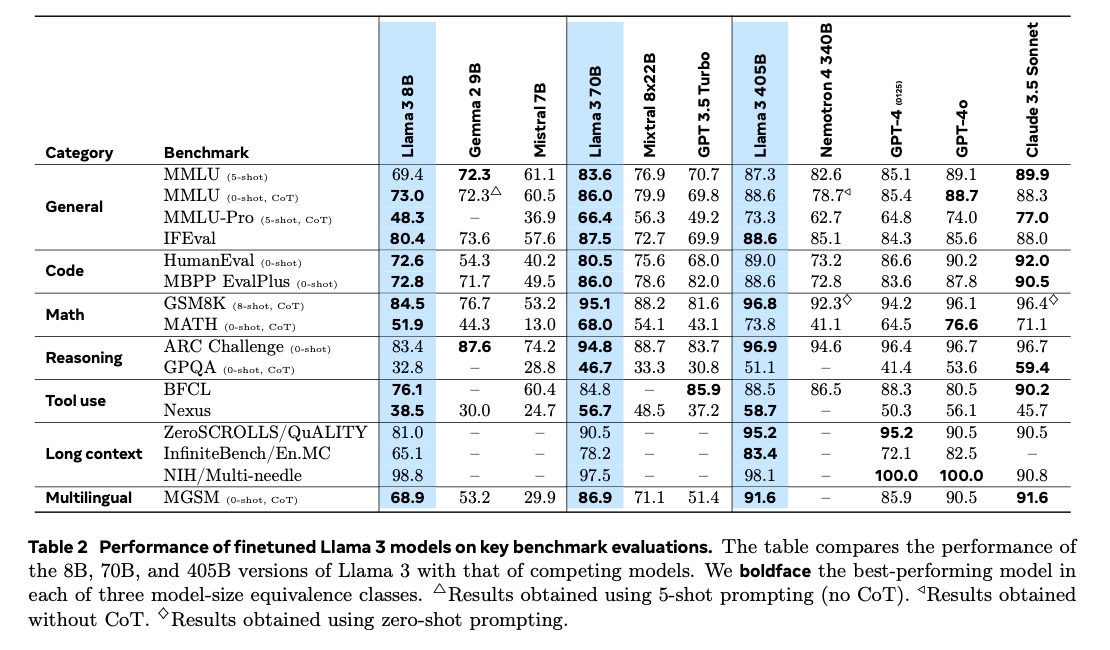
P.3
Llama3の小型のモデルは、大規模なモデルの蒸留は使用しておらず、それぞれに最適な学習を行っています。
学習データ量
405B(4050億パラメータ)のモデルは15600B(15.6兆)のトークンで学習されています。これは、Llama2 70Bの50倍のデータ量です。
(感想)Chinchilla scaling lowではモデルサイズの10倍のトークン数のデータセットが必要というのが言われていますが、LLAMA3はモデルサイズの38倍のトークン数のデータセットで学習されています。
コンテキストウィンドウサイズ
LLAMA3のコンテキストウィンドウサイズは128Kトークンですが、事前学習は8Kコンテキストトークンサイズで行い、その後の継続的な事前トレーニングで128Kコンテキストトークンサイズに拡張します。コンテキストサイズは6段階で段階的にウィンドウサイズを大きくし、800Bの学習トークンでコンテキストウィンドウサイズを拡張します。
(感想)論文中、継続的な事前トレーニング(continued pre-training)と呼ばれていることから、ファインチューニングという概念ではなく、全ては継続的な事前学習という考え方で設計されているようです。また、最初から128Kトークンで学習されているわけではないようです。
学習データ
マークダウンを学習するとモデルパフォーマンスが低下するため、マークダウンのマーカーは除去されています。

P.5
(感想)マークダウンはそのまま学習されていると思っていたため、意外でした。
モデルアーキテクチャ
モデルアーキテクチャは一般的なTransformerアーキテクチャを使用しています。性能向上は、データの質と多様性の向上、そして学習の規模の拡大によって実現されています。
学習機材
16K個のH100 GPUと、80GBのHBM3を使用しています。
(感想)H100 GPUは一台、470万円程度なので、752億円規模の機材で学習されています。
学習時のエラー対処
学習中のGPUの使用率は38〜43%です。学習には54日で、合計466件の学習の中断が発生しています。47件はファームウェアのアップデートやオペレータの自動保守、419件は予期しない中断でした。GPUやホストコンポーネントの故障、サイレントデータなどのハードウェアの不良、計画外の個別ホストのメンテナンスです。
GPUの問題が最大のカテゴリで、3件は手動での対処が必要、残りの問題は自動化で対処されています。GPUまたはNVLinkのいずれかの障害は、多くの場合、ロード・ストア操作の停止として現れ、CUDAカーネル内で明確なエラーコードを返しません。Pytorchを改良し、通信ライブラリの状態を監視し、タイムアウトを自動的に行います。
(感想)学習に使用するGPUが多いため、ハードウェア障害が定常的に発生する問題があります。どのようにハードウェア障害への対処を自動化するかが重要なようです。
コードの学習
AIが生成したコードを、静的解析と、単体テストの生成と実行によって、エラーフィードバックし、反復的な自己修正を行います。
多言語対応
事前学習用データには、英語のトークンが非英語のトークンよりも圧倒的に多く含まれています。事前トレーニングの後、分岐させ、多言語のトークンで事前トレーニングを継続することで、多言語対応します。
(感想)最初から多言語のデータで学習するわけではなく、事前トレーニングの後に多言語のトークンを加えるようです。
ツール呼び出し
全てのツール呼び出しはPythonインタープリタによって実行され、Llama3システムプロンプトで有効にする必要があります。
(感想)システムプロンプトでAgent向けのツール呼び出しを有効化できるようです。
事実性
ハルシネーションの対策のための調整を行います。事後トレーニングは、「自分が知っていることを知る(know what it knowns)」ように調整すべきで、新しい知識を加えるべきでないという原則があります。(Does Fine-Tuning LLMs on New Knowledge Encourage Hallucinations?)その原則に従いながら、事前トレーニングデータに含まれる事実データと、モデルが生成した結果を一致させる必要があります。
そのため、事前学習データからデータスニペットを抽出し、Llama3で質問と回答を生成します。リファレンスとしてデータスニペットからLlama3で生成した回答と、リファレンスを使用しなかった回答が食い違っていないかをLlama3にジャッジさせます。これにより、事実に基づく内容のみを生成できるように調整します。不確かな質問には答えるのを拒否するようにします。

P.27 4.3.6 Factuality
(感想)学習時にハルシネーションへの対策が実装されています。リファレンスとしてデータスニペットからLlama3で生成する方法は、RAGの考え方に近く、事実性の向上のために、RAGで生成したデータを真実として比較して学習しているということは、RAGはハルシネーションの抑制に有効であるという印象を受けます。ハルシネーションについては、下記のGoogleのDeepMindの研究で、ハルシネーションを抑えるには、1桁大きいモデルサイズが必要という研究があるため、モデルサイズは大きいものを使った方が良さそうです。
操縦性
システムプロンプトを通じて操縦性を強化します。特に、応答の長さ、形式、トーンやキャラクター・ペルソナについて、操縦性を強化するように調整します。

P.28
(感想)システムプロンプトには、応答の長さ・形式・トーン・キャラクター・ペルソナを与えると良さそうです。
安全性
事前トレーニングには様々なフィルターを適用します。個人情報を含むと考えられるウェブサイトを識別するフィルタなどを使用します。化学兵器および生物兵器などに関する回答を行えないように調整します。
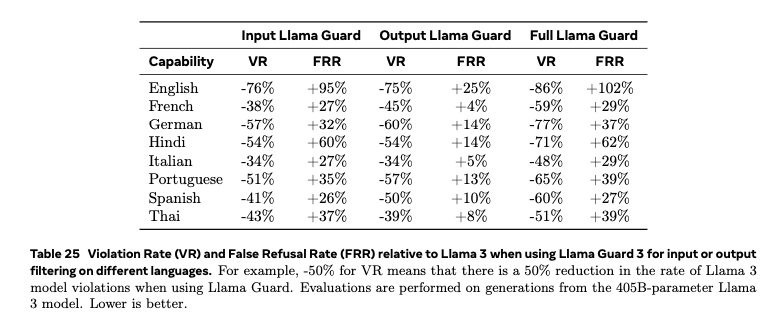
P.50
推論
405BのモデルはGPUに収まらないため、FP8に量子化します。ほとんどのパラメータとアクティベーションを量子化します。アテンションノパラメータは量子化しません。最初と最後のTransformer層では量子化を行いません。日付などの高い難解性を持つトークンは、大きなアクティベーション値を引き起こす可能性があります。FP8で高い値のスケールファクタを使用すると無視できない数のアンダーフローが発生する場合があります。
(感想)全てのレイヤーを量子化するわけではなく、適応的な量子化が使用されています。また、日付が高い難解性を持つと明記されているのは、実感と合っているなと思いました。
まとめ
Llama3の設計方針を知ることができる、とても良い論文でした。実際にLlama3の規模のLLMを学習することはコスト的に難しいですが、設計方針を知ることで、Llama3をどのように使うと最適なのかを知ることができました。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。