LipGAN : リップシンク動画を生成する機械学習モデル
リップシンク動画を生成する機械学習モデルであるLipGANのご紹介です。LipGANを使用することで、音声と動画からリップシンク動画を生成することが可能です。
LipGANの概要
LipGANはリップシンク動画を生成する機械学習モデルです。2019年10月に公開されました。音声ファイルと動画ファイル、もしくは静止画を入力として、音声に合わせてリップシンクする動画を出力することが可能です。LipGANはWav2Lipの前バージョンで、Wav2Lipに比べて使用しやすいライセンス(MIT)となっています。分野としてはTalkingFaceGenerationとなります。
LipGANのアーキテクチャ
LipGANでは、音声ファイルを入力として、MFCCを計算し、Audio Encoderに通すとともに、顔画像からFace EncoderでEmbeddingを計算、それらの特徴を合わせてFace Decoderに通すことで出力画像を得ます。
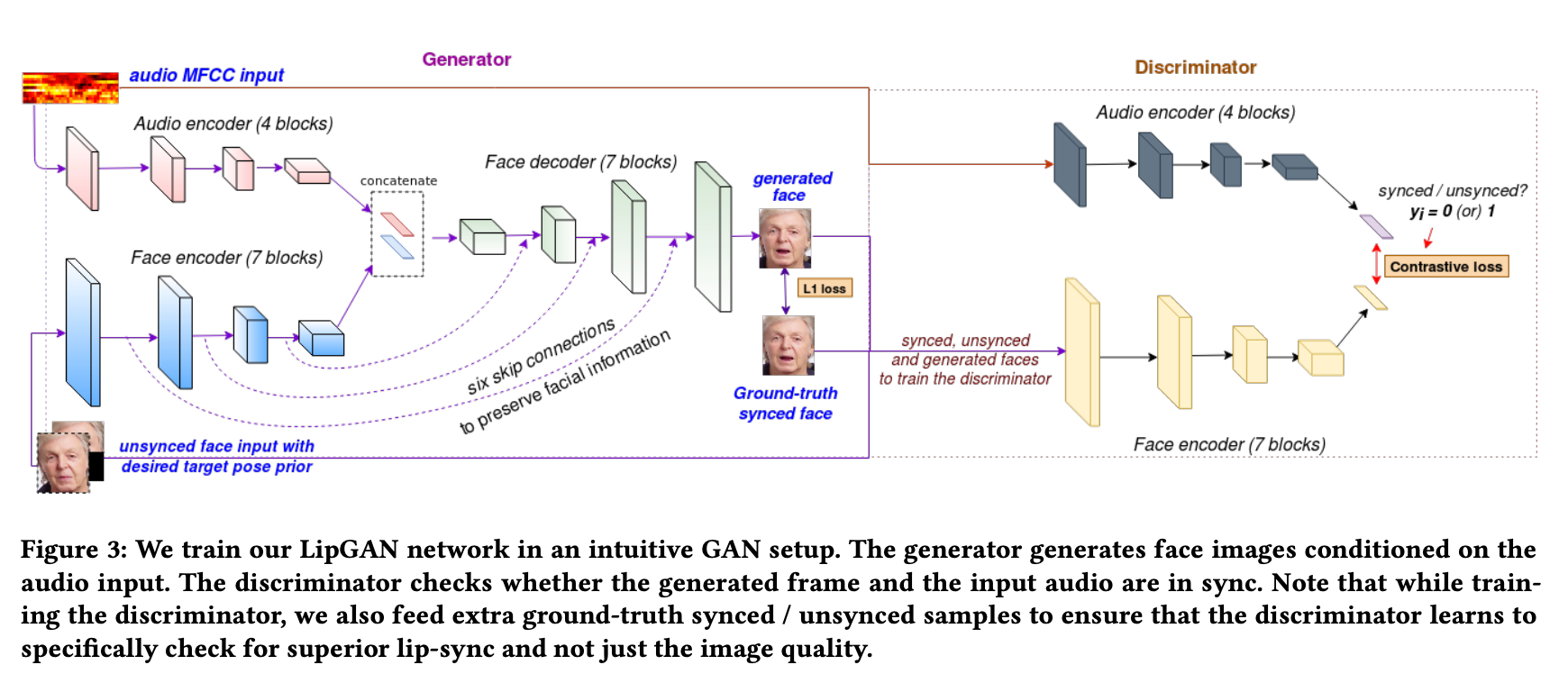
LipGANのアーキテクチャ(出典:https://cdn.iiit.ac.in/cdn/cvit.iiit.ac.in/images/Projects/facetoface_translation/paper.pdf)
実装はKerasで行われています。顔検出にはDlibを使用しています。
MFCCの計算はオリジナルではMatlabを使用していましたが、fully_pythonicブランチでlibrosaを使用したMelSpecturmを使用したバージョンも公開されています。
顔画像の入力は96x96画素で6channelです。最初の3channelにはBGR順で0–1のレンジの顔画像を、後半の3channelには顔の下半分を0で埋めた画像を与えます。 出力は96x96画素で3channelです。

LipGANの入力1、LipGANの入力2、LipGANの出力
音声の入力は、オーバラップした27要素(337ms相当)のMelSpectrumです。
デフォルトの生成フレームレートは25fpsです。処理はフレーム独立となっています。
LipGANのデータセット
LipGANの学習では、LRS2 datasetを使用しています。LRS2 datasetには、29時間のtalking facesのデータが含まれています。
LipGANの使用方法
ailia SDKを使用することで、下記のコマンドで、input.jpgとinput.wavからリップシンク動画のoutput.mp4を出力可能です。
$ python3 lipgan.py --input input.jpg --audio input.wav --savepath output.mp4
ffmpegが必要ですが、音声付きの動画を生成する場合は、merge_audioオプションを使用します。
$ python3 lipgan.py --input input.jpg --audio input.wav --savepath output.mp4 --merge_audio

LipGANの出力例
LipGANの出力は96x96画素のため、顔が大きい場合にぼやけるという課題があります。realesrganオプションを使用することで超解像を併用することも可能です。
$ python3 lipgan.py --input input.jpg --audio input.wav --savepath output.mp4 --realesrgan
UnityからLipGANを使用する
Unityとailia SDKを使用して、AudioClipと静止画、もしくはビデオからLipGANを使用してリップシンクを行うサンプルを提供しています。
LipGANをUnityで使用する例
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。