LangChainを使用して任意のドキュメントからChatGPTで回答する
LangChainを使用して任意のドキュメントからChatGPTで回答する方法を解説します。
LangChainの概要
ChatGPTは学習していないデータから回答を行うことができないため、コンテキストを外挿することが行われています。この方法はRAG(Retrieval Augmented Generation)と呼ばれており、質問文に外部のテキストを挿入してLLMに回答させることで実現します。
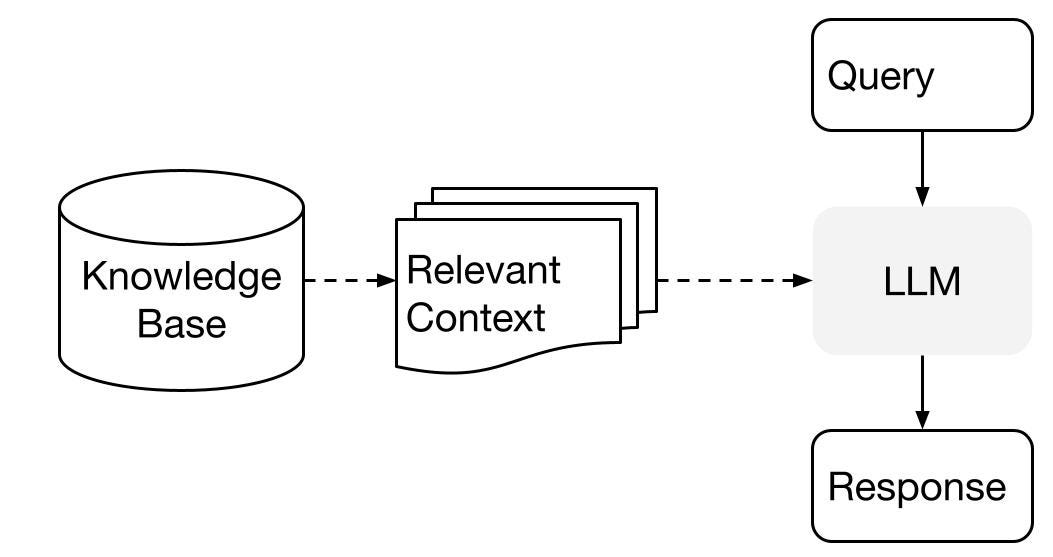
出典:https://gpt-index.readthedocs.io/en/latest/getting_started/concepts.html
LangChainを使用すると、簡単にRAGを実装することができます。任意のドキュメントからインデックスを作成し、そのコンテキストを元に回答を行うことが可能です。
インデックスの作成
PDFからインデックスを作成するには下記のようにします。まず、PDFを読み込みテキストを生成した後、TextSplitterでchunkに分割します。その後、Embeddingを計算し、ローカルのベクトルデータベースであるChromaDBに書き込みます。
from langchain.document_loaders import PDFMinerLoader
loader = PDFMinerLoader("AR02ALA_UM01_21J.pdf")
documents = loader.load()
from langchain.text_splitter import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter(chunk_size=400, chunk_overlap=0)
texts = text_splitter.split_documents(documents)
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
from langchain.vectorstores import Chroma
db = Chroma.from_documents(texts, embeddings, persist_directory="./storage")
db.persist()
インデックスからの回答
インデックスから回答を得るには下記のようにします。ChromaDBにインデックスを読み込み、retriverを取得、RetrievalQAを使用して回答を生成します。
RetrivalQAでstuffを指定した場合、Refinementは行いません。ベクトルデータベースからTOP_K個のchunkを取得し、複数のchunkをまとめてChatGPTに質問し、1回で回答を得ます。
from langchain.embeddings import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
from langchain.vectorstores import Chroma
db = Chroma(persist_directory="./storage", embedding_function=embeddings)
retriever = db.as_retriever()
from langchain.llms import OpenAI
llm = OpenAI(model_name="text-davinci-003", temperature=0, max_tokens=500)
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
import sys
args = sys.argv
if len(args) >= 2:
query = args[1]
else:
query = "ailia SDKが対応しているOSを教えてください。"
answer = qa.run(query)
print("Q:", query)
print("A:", answer)
応用
ストリーミング出力
ストリーミング出力を行うには、OpenAIにstreaming=Trueを与え、カスタムコールバックを与えます。
llm = OpenAI(model_name="text-davinci-003", temperature=0, max_tokens=500, streaming=True, callback_manager=CallbackManager([MyCustomCallbackHandler()]), )
from langchain.chains import RetrievalQA
qa = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=retriever)
query = "ailia SDKとは何ですか。"
answer = qa.run(query)
カスタムコールバックは下記のBLOGに実装例があります。
ChromaDBに複数のドキュメントを登録してフィルタする
ChromaDBのmetadataのsourcesにはファイル名が入っています。as_retriverにおいて、search_kwargsのfilterを使用することで、特定のドキュメントだけを検索対象にすることが可能です。
retriever = db.as_retriever(
search_kwargs={
"k": TOP_K,
"filter": {"source":filter}
})
トラブルシューティング
macOSでChromaDBがインストールできない
pip3 install chromadbを行うと、下記のエラーになります。
clang -Wno-unused-result -Wsign-compare -Wunreachable-code -fno-common -dynamic -DNDEBUG -g -fwrapv -O3 -Wall -iwithsysroot/System/Library/Frameworks/System.framework/PrivateHeaders -iwithsysroot/Applications/Xcode.app/Contents/Developer/Library/Frameworks/Python3.framework/Versions/3.9/Headers -arch arm64 -arch x86_64 -Werror=implicit-function-declaration -I/private/var/folders/_5/1td0d93j50j3h3l13x3tbczm0000gn/T/pip-build-env-g6zyba0j/overlay/lib/python3.9/site-packages/pybind11/include -I/private/var/folders/_5/1td0d93j50j3h3l13x3tbczm0000gn/T/pip-build-env-g6zyba0j/overlay/lib/python3.9/site-packages/numpy/core/include -I./hnswlib/ -I/Applications/Xcode.app/Contents/Developer/Library/Frameworks/Python3.framework/Versions/3.9/include/python3.9 -c ./python_bindings/bindings.cpp -o build/temp.macosx-10.9-universal2-3.9/./python_bindings/bindings.o -O3 -march=native -stdlib=libc++ -mmacosx-version-min=10.7 -DVERSION_INFO=\"0.7.0\" -std=c++14 -fvisibility=hidden
clang: error: the clang compiler does not support '-march=native'
error: command '/usr/bin/clang' failed with exit code 1
その場合、下記のようにすると問題を回避可能です。
export HNSWLIB_NO_NATIVE=1
使用したコード
今回、使用したサンプルは下記にアップロードしてあります。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。