Florence2 : 軽量でエッジ実装可能なVision Language Model
軽量でエッジ実装可能なVLMであるFlorence2の紹介です。
Florence2の概要
Florence2はMicrosoftの開発した軽量なVLM(Vision Language Model)です。2023年11月に公開されました。入力された画像に対して、キャプション生成、Bounding Boxの計算、OCR、セグメンテーションが可能です。
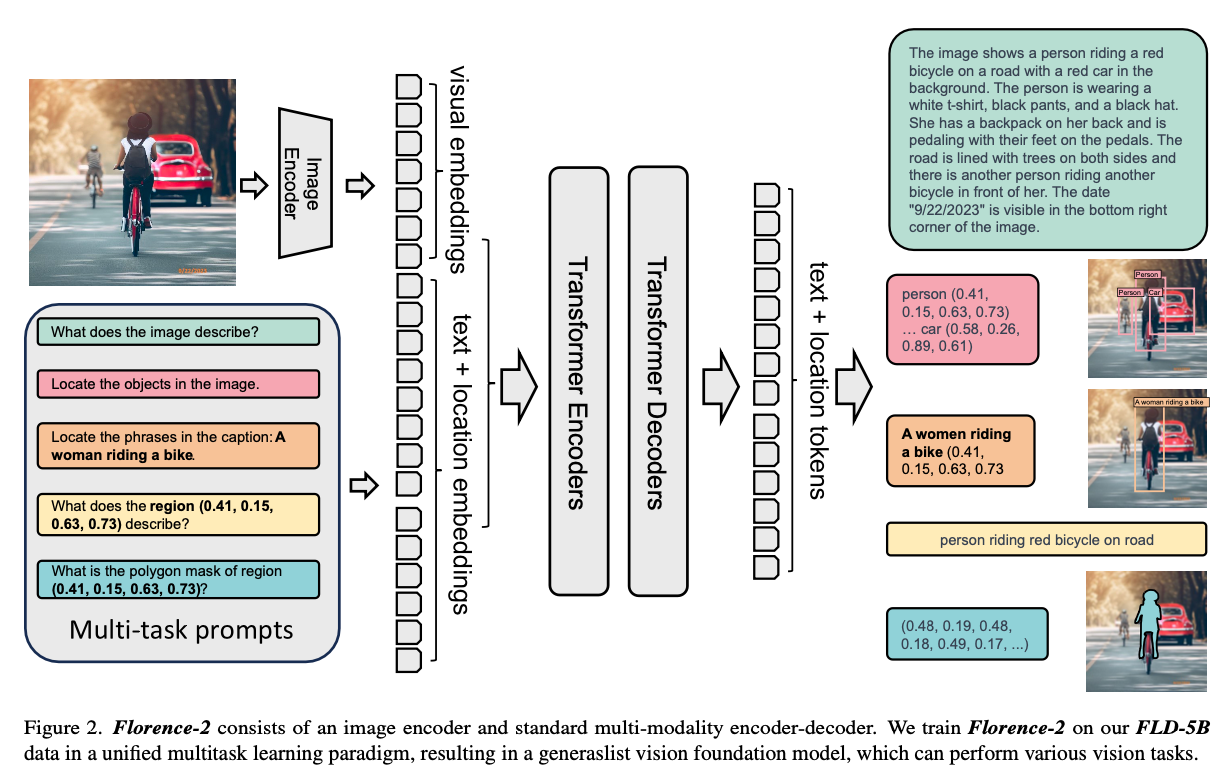
Florence2の特徴
Florence2は、OSSのVLMで有名なLLAVAよりも軽量で、エッジ実装が可能です。また、キャプションモデルのBLIP2よりも高精度になっています。
ただし、軽量な分、LLAVAのように自由なプロンプトが使用できるわけではなく、固定のプロンプトを使用します。例えば、キャプション生成のプロンプトでは、「What does the image describe?」を固定的に使用します。「How many cars exists?」などに書き換えると、正しい出力は得られません。
任意のプロンプトを使用したい場合は、Florence2で画像をテキストに変換し、そのテキストとプロンプトを別のLLMに入力する形になります。
Florence2のデータセット
Florence2は、人力によらずに大規模なデータセットを作成しています。このデータセットはFLD-5Bという名称で、1億2600万枚の画像に対して、54億個のアノテーションが付与されています。
データセットの作成には、SegmentAnything、Azure Document Inteligence (OCR)、Grounding Dino、LLMを使用しています。Object DetectionのBounding Boxもテキスト情報として扱っています。
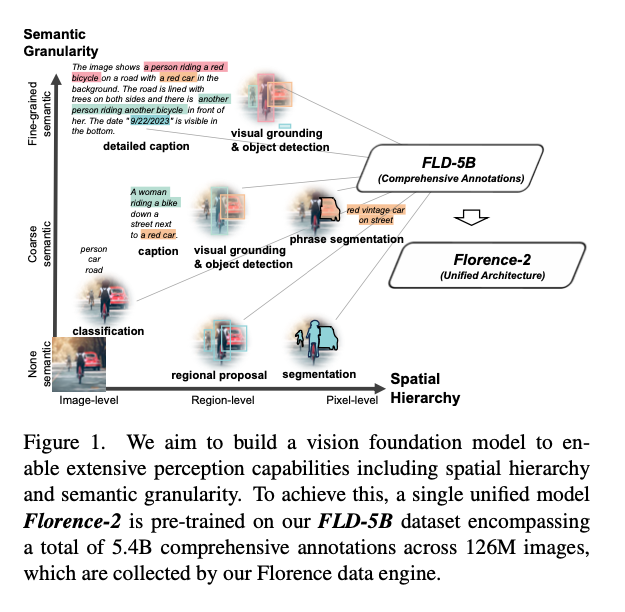
Florence2は、各種の大規模なモデルを使用してデータセットを作り、そのデータセットを使用して学習することで、軽量なモデルを構築しています。
Florence2のアーキテクチャ
Florence2は、Sequence To Sequenceを使用しており、全てのタスクを翻訳問題として定式化しています。
ObjectDetectionのためのボックス表現では(x0, y0, x1, y1)、OCRのためのクワッドボックス表現では(x0, y0, x1, y1, x2, y2, x3, y3)、セグメンテーションマスクのためのポリゴン表現では(x0, y0, … , xn, yn)を使用しています。
入力されたプロンプトはTokenizerでTokenizeされ、Text EncoderでEmbeddingされます。入力された画像は768x768にリサイズされ、Vision EncoderでEmbeddingされます。
入力されたプロンプトが‘What does the image describe?’であれば、[ 0 2264 473 5 2274 6190 116 2]というトークンになり、(1, 8, 768)のEmbeddingになります。
テキストと画像のEmbeddingはConcatした上で、Encoderに入力し、hidden_stateを取得、Decoderで1トークンずつ出力します。
TokenizerはBartTokenizerです。モデルアーキテクチャは、Vision EncoderにDaVIT、EncoderとDecoderにLayerNormを使用した一般的なTransformerを使用しています。
Florence2の使用方法
ailia SDKでFlorence2を使用するには下記のコマンドを使用します。
python3 florence2.py -i input.jpg -p CAPTION
プロンプトには、下記のいずれかを指定可能です。
choices=[
"CAPTION",
"DETAILED_CAPTION",
"MORE_DETAILED_CAPTION",
"CAPTION_TO_PHRASE_GROUNDING",
"OD",
"DENSE_REGION_CAPTION",
"REGION_PROPOSAL",
"OCR",
"OCR_WITH_REGION",
],
入力画像です。

出典:https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg
DETAILED_CAPTIONの出力です。
{'<MORE_DETAILED_CAPTION>': 'The image shows a vintage Volkswagen Beetle car parked on a cobblestone street in front of a yellow building with two wooden doors. The car is a light blue color with a white stripe running along the side. It has a round body and a small rear window. The wheels are silver with black rims. The building appears to be old and dilapidated, with peeling paint and crumbling walls. The sky is blue and there are trees in the background.'}
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。