Whisper Large V3 Turbo: High-Accuracy and Fast Speech Recognition Model
We already introduced Whisper in a previous article, as well as methods to perform prompt engineering and fine-tuning on it. Today we focus on its latest update, Whisper Large V3 Turbo.
Overview
Whisper Large V3 Turbo is the latest model of Whisper released by OpenAI in October 2024. While maintaining the accuracy of the Large V2 model, it significantly improves processing speed.
Architecture
Whisper Large V3 Turbo is a model that reduces the number of decoder layers in Whisper Large V3 from 32 to 4. With just 4 layers, the same as the tiny model, it achieves significant speed improvements.
This implementation is inspired by Distil-Whisper, which showed that using a smaller decoder can greatly improve speed while maintaining accuracy.
While Distil-Whisper uses distillation, Whisper Large V3 Turbo is retrained on Whisper’s original dataset. Since translation data is not included, its performance in translation mode has declined.
The graph below is a comparison of inference speed and accuracy. The horizontal axis represents inference speed, with faster models positioned further to the right. The turbo model achieves inference speeds between tiny and base models. The vertical axis represents accuracy (error rate), with lower positions indicating higher accuracy. Whisper Large V3 Turbo achieves accuracy equivalent to Large V2.
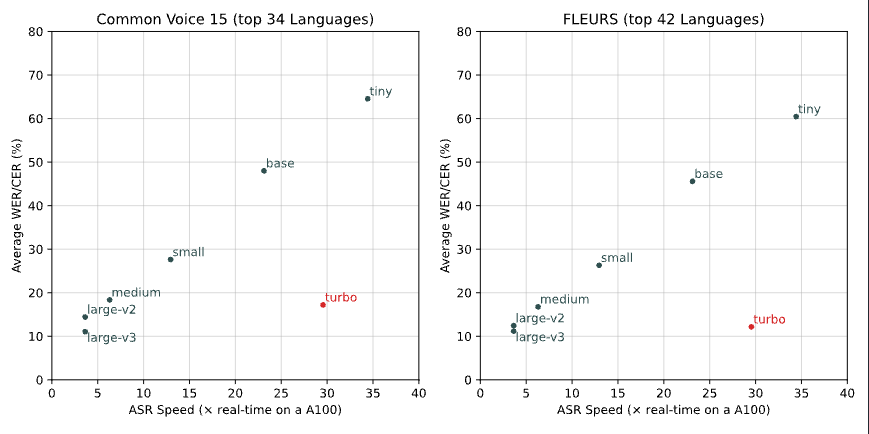
Source: https://github.com/openai/whisper/discussions/2363
Below is the accuracy by language. While there is a drop in accuracy for languages like Thai and Cantonese, the model maintains the same level of accuracy as Large V2 for Japanese.
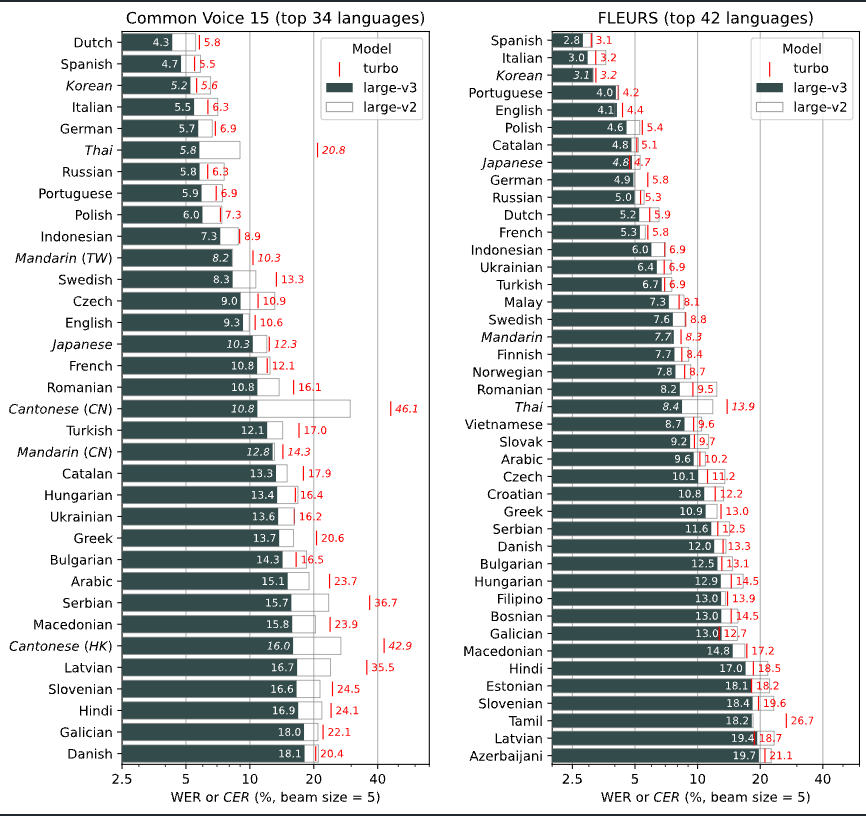
The model architecture of Whisper Large V3 Turbo is compatible with Whisper Large V3. Therefore, you can use the inference code for Whisper Large V3 without any modifications.
About Whisper Large V2 and V3
Whisper Large V2, often simply referred to as “Large,” is a high-accuracy model that has been part of Whisper since its early stages. Whisper Large V3, released in November 2023, is a newer model that expanded the supported languages from 99 to 100 with the addition of Cantonese, and increased the number of MelSpectrum bins from 80 to 128.
Usage
You can use Whisper Large V3 Turbo with ailia SDK using the following command:
$ python3 whisper.py --input input.wav -m turbo
Since Whisper Large V3 Turbo is compatible with Whisper Large V3, you can simply replace the model in ailia AI Speech to run it. Therefore, no library update is required, and it can also be used from Unity.
It can also be used from the ailia AI Speech Python package.
ailia-speechailia AI Speechpypi.org
Evaluation
When using ailia SDK and Whisper Large V3 Turbo on the CPU of a Mac M2, the inference time for converting 40 seconds of audio data is as follows:
small 9432 ms(encoder 659ms decoder 37ms)
turbo 18363 ms(encoder 2878ms decoder 37ms)
medium 29323 ms(encoder 2277ms decoder 353ms)
In terms of model architecture, the encoder is the same as Large V3, so the encoder is computationally heavy, while the decoder is significantly faster.
The encoder processes 30 seconds of audio at once, using a static shape, meaning the tensor shape does not change between frames. In contrast, the decoder operates with a dynamic shape, where the tensor shape changes between frames, necessitating shader recompilation. Since Whisper Large V3 Turbo has a heavy encoder and a lightweight decoder, it benefits from GPU acceleration, making it an architecture that can easily achieve performance improvements on the GPU.
When used with the GPU on an M2 Mac, the performance is as follows:
small 15588 ms(encoder 310ms decoder 69ms)
turbo 15775 ms (encoder 2129ms decoder 37ms)
medium 57175ms (encoder 1078ms decoder 241ms)
For models like small and medium, the CPU performs faster. However, with the turbo model, the GPU provides faster performance.
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.