Whisper Fine Tuning To Transcribe Jargon
This article explains how Whisper can be fine-tuned with a small amount of data set to make domain-specific terminology recognizable. By creating a dataset with Tacotron2 synthesized speech, a Whisper model can be created and recognize technical terms.
About Whisper
Whisper is a speech recognition model developed by OpenAI able to transcribe many languages with high accuracy. However a limitation of this model is that technical terms that don’t appear during training cannot be transcribed.
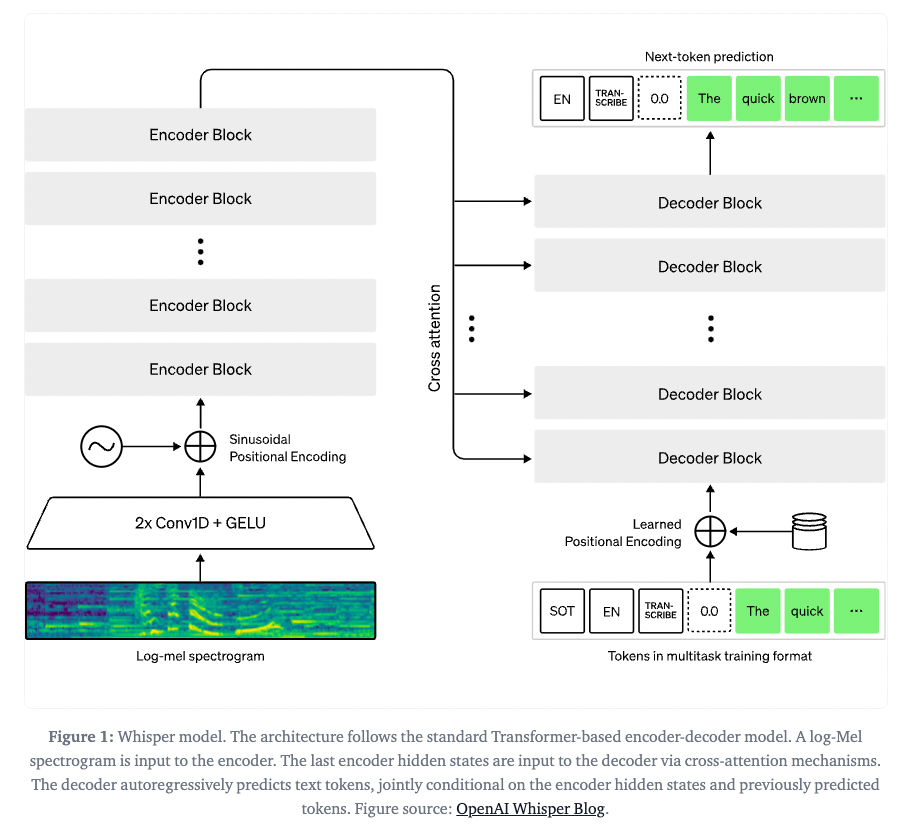
Whisper Architecture (Source: https://huggingface.co/blog/fine-tune-whisper)
Refer to the article below for more details about Whisper mechanisms.
Whisper : Speech recognition model capable of recognizing 99 languagesThis is an introduction to「Whisper」, a machine learning model that can be used with ailia SDK. You can easily use this…medium.com
Technical Terms Using Prompt Engineering
One method to include technical terms in Whisper’s knowledge base is to embed those terms in the initial prompt used by the language model. This method was described in details in the article below.
However we saw that this initial prompt has strong size limitations and cannot be used for a large dataset of new words.
Whisper Fine Tuning
The developers of transformers for Pytorch from Hugging Face added a feature to transformers to perform Whisper fine tuning.
This fine tuning technique to make Whisper learn new words by giving it audio / text pairs is described in the following blog post. Since Whisper predicts UTF8 bytecodes directly, so there is no need to update the initial vocabulary items when adding new words.
Note that when fine-tuning for languages with no space between words, like in Japanese, the the compute_metrics function mentioned in the blog post cannot correctly calculate the Word Error Rate (WER). In that case it is necessary to improve the metrics function using morphological analysis of the open source Japanese NLP library Ginza. This method is explained in the following blog post, available in Japanese only.
Dataset Structure
To build your own dataset, use DatasetDict and Dataset , and provide the path to the audio file in fileList and the text to be trained on sentenceList.
from datasets import DatasetDict, Dataset
common_voice = DatasetDict()
fileList = ["test/tsukuyomi1.wav", "test/tsukuyomi2.wav"]
sentenceList = ["こんにちは。今日は新しいAIエンジンであるailia SDKを紹介します。ailia SDKは高速なAI推論エンジンです。", "コア技術"]
common_voice["train"] = Dataset.from_dict({"audio": fileList, "sentence": sentenceList}).cast_column("audio", Audio(sampling_rate=16000))
Training
The training follows the procedure from Hugging Face and uses Seq2SeqTrainingArguments and Seq2SeqTrainer to set up the data set and run trainer.train()
trainer.train()
With 5 audio files, 40 epochs on an Mac M1 CPU, the training of Whisper Small takes about 20 minutes. When learning is complete, the results are output to whisper-small-en/checkpoint-40
Such training can be done based on speech synthesized generated using Tacotron2.
Inference
To run an inference using the newly trained model, load the model with WhisperForConditionalGeneration.from_pretrained as shown below.
import torch
from transformers import AutoProcessor, WhisperForConditionalGeneration
from datasets import load_dataset, DatasetDict, Dataset
from datasets import Audio
processor = AutoProcessor.from_pretrained("openai/whisper-small")
# original
#model = WhisperForConditionalGeneration.from_pretrained("openai/whisper-small")
# fine tuned
model = WhisperForConditionalGeneration.from_pretrained("whisper-small-ja/checkpoint-40")
model.config.forced_decoder_ids \
= processor.get_decoder_prompt_ids(language = "ja", task = "transcribe")
model.config.suppress_tokens = []
common_voice = DatasetDict()
fileList = ["test/ailia.wav"]
common_voice["train"] = Dataset.from_dict({"audio": fileList}).cast_column("audio", Audio(sampling_rate=16000))
for i in range(len(common_voice["train"])):
inputs = processor(common_voice["train"][i]["audio"]["array"], return_tensors="pt")
input_features = inputs.input_features
generated_ids = model.generate(inputs=input_features)
transcription = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(transcription)
Examples of inference code can be found in the official Hugging Face documentation.
Conversion to official Whisper weights
The script below converts from the official Whisper to the Hugging Face Whisper. The reverse operation is needed to use models trained with Hugging Face with regular Whisper.
from transformers import AutoProcessor, WhisperForConditionalGeneration
finetune_model = WhisperForConditionalGeneration.from_pretrained("whisper-small-ja/checkpoint-40")
WHISPER_MAPPING = {
"encoder.ln_post.weight": "encoder.layer_norm.weight", # added by ax
"encoder.ln_post.bias": "encoder.layer_norm.bias", # added by ax
"blocks": "layers",
"mlp.0": "fc1",
"mlp.2": "fc2",
"mlp_ln": "final_layer_norm",
".attn.query": ".self_attn.q_proj",
".attn.key": ".self_attn.k_proj",
".attn.value": ".self_attn.v_proj",
".attn_ln": ".self_attn_layer_norm",
".attn.out": ".self_attn.out_proj",
".cross_attn.query": ".encoder_attn.q_proj",
".cross_attn.key": ".encoder_attn.k_proj",
".cross_attn.value": ".encoder_attn.v_proj",
".cross_attn_ln": ".encoder_attn_layer_norm",
".cross_attn.out": ".encoder_attn.out_proj",
"decoder.ln.": "decoder.layer_norm.",
"encoder.ln.": "encoder.layer_norm.",
"token_embedding": "embed_tokens",
"encoder.positional_embedding": "encoder.embed_positions.weight",
"decoder.positional_embedding": "decoder.embed_positions.weight",
#"ln_post": "layer_norm", # disabled by ax
}
def rename_keys(s_dict):
keys = list(s_dict.keys())
for key in keys:
new_key = key
for v, k in WHISPER_MAPPING.items():
if k in key:
new_key = new_key.replace(k, v)
print(f"{key} -> {new_key}")
s_dict[new_key] = s_dict.pop(key)
return s_dict
state_dict = finetune_model.model.state_dict()
rename_keys(state_dict)
import whisper
model = whisper.load_model("small")
missing, unexpected = model.load_state_dict(state_dict, strict = False)
if len(missing):
print("Weight name not found", missing)
raise
result = model.transcribe("test/axell_130.wav", language="ja", verbose=False)
for s in result["segments"]:
start = s['start']
end = s['end']
text = s['text']
print(str(start) + "\t" + str(end) + "\t" + text)
About ailia Speech
ailia Inc. provides a library that allows AI speech recognition using Whisper to run offline as a Unity or C++ API, including custom prompt features.
ailia AI Speech : Speech Recognition Library for Unity and C++Introducing ailia AI Speech, an AI speech recognition library which allows you to easily implement speech recognition…medium.com
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.