UnetSourceSeparation: A machine learning model to remove audio noise and extract voices
This is an introduction to「UnetSourceSeparation」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
UnetSourceSeparation is a audio separation model released in March 2019. It can cancel background noise from an input audio file and extract voices.
UnetSourceSeparation demonstration
The official demo of voice separation is shown below. The original voice and the processed voice are played alternately.
Architecture
In speech processing, it is common to perform Short Time Fourier Transform (STFT) on the input speech and apply CNN in frequency space. the output of FT (Fourier Transform) is a Complex Value, which consists of Magnitude and Phase.
Phase estimation is difficult, and in conventional speech separation, only Magnitude is estimated. However, when the Phase of the original material is used as it is, there is no problem when the Signal-to-Noise Ratio (SNR) is high (low noise), but when the SNR is low (high noise), there is a problem that noise remains.
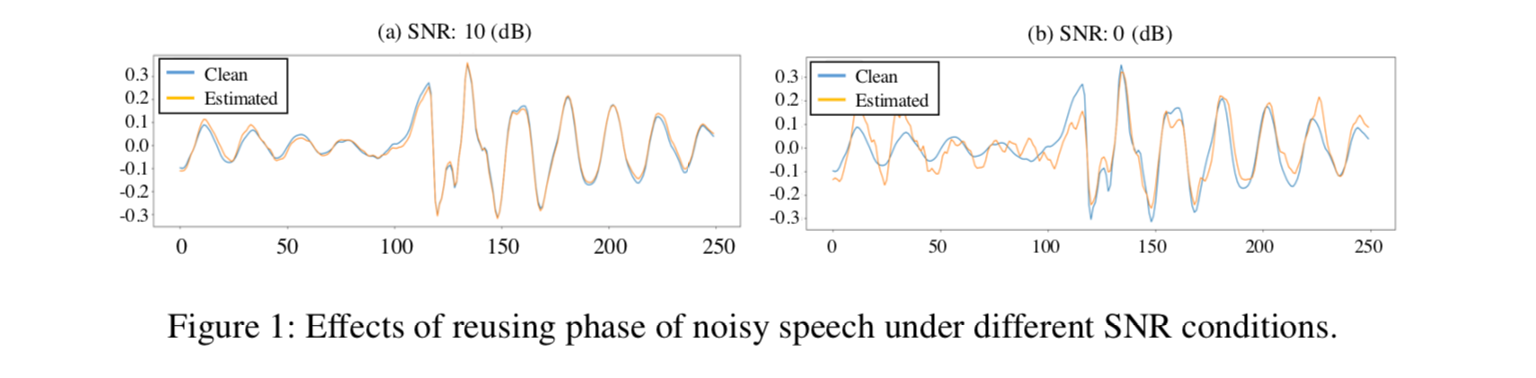
Source:https://arxiv.org/pdf/1903.03107v1
In UnetSourceSeparation, the new Complex Value Convolution enables Phase prediction.
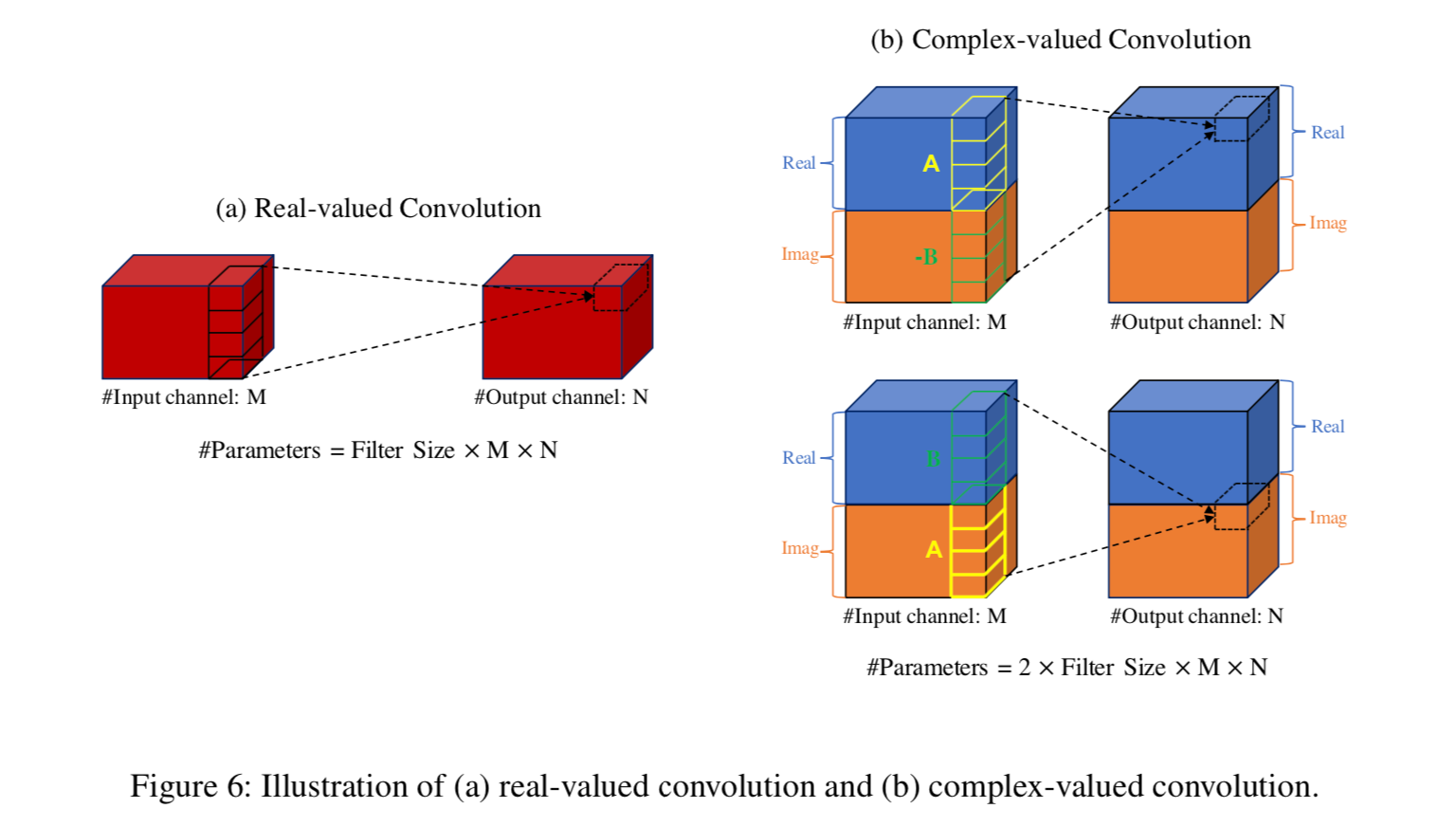
Source:https://arxiv.org/pdf/1903.03107v1
The architecture of UnetSourceSeparation is as follows. The input audio is processed using STFT to obtain the frequency components and then passed through Unet architecture using Complex Convolution. It then creates a mask and use it to remove the noise, and returns to the waveform using Inverse Short-Time-Fourier-Transform (ISTFT).
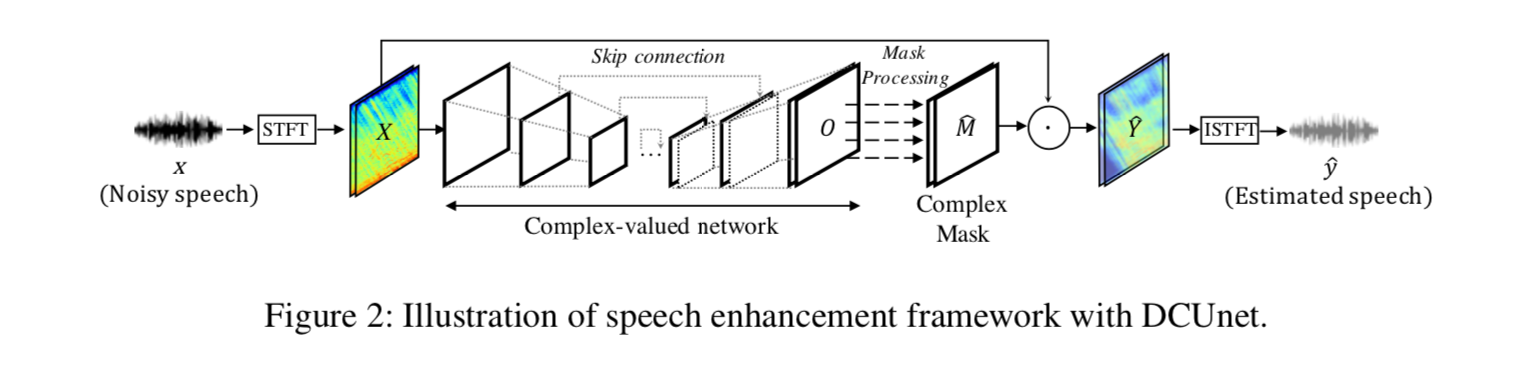
Source:https://arxiv.org/pdf/1903.03107v1
The DSD100 dataset is used for training.
Usage
Given an input audio file, the output audio file is generated. The default model used it the noise reduction model for voice separation in general speech.
$ python3 unet_source_separation.py --input WAV_PATH --savepath SAVE_WAV_PATH
To perform voice extraction in a music song, add the parameter --arch large
$ python3 unet_source_separation.py --input WAV_PATH --savepath SAVE_WAV_PATH --arch large
ailia-ai/ailia-modelsNoisy speech (audio file) Audio from creative commons youtube videos…github.com
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.