StableDiffusion: Machine Learning Model to Generate Images From Text
StableDiffusion is a machine learning model that generates images from text. The trained model is publicly available, and images can be generated freely on a PC.
Overview
StableDiffusion is a machine learning model for generating images from text published in August 2022. Service such as DALLE2 and Midjourney exist to generate images from text, but in both cases, the trained models are private and must be accessed via a web service. StableDiffusion allows users to freely generate images on their PCs because the trained models are publicly available.
Usage
To use Stable Diffusion on Windows, pre-built binaries are provided by GRisk and available at the link below.
After unzipping Stable Diffusion GRisk GUI.rar, launch the Stable Diffusion GRisk GUI.exe
Since the default parameters do not generate a proper image, set the Steps to 150 and the Resolution to 512. Then enter a text prompt and click Render to generate an image. The generated images are stored in the results folder.
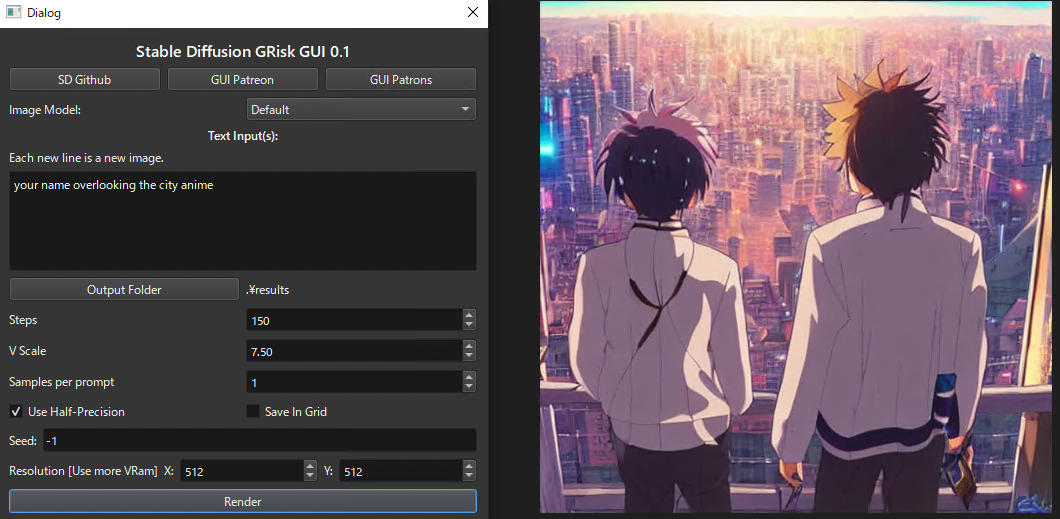
UI of Stable Diffusion GRisk
When the number of words in the prompt is small, the output tends to be unstable, perhaps because the feature vector does not have enough information to construct a picture. Therefore, it seems best to provide information about the picture you want in as much detail as possible.

“hastune miku standing on the mountain anime”

“your name overlooking the city anime”
Image generation takes about 32 seconds on a machine equipped with an RTX3080.
Dataset
StableDiffusion was trained on the LAION-5B dataset which contains 5.85 billion image/text pairs.
The contents of the dataset can be searched from the following page. The search uses CLIP’s Embedding, indicating that CLIP is also effective for image searches.
Clip frontClip frontClip frontrom1504.github.io
StableDiffusion was trained on images from LAION-2B at resolution 256x256, then on 170 million 512x512 resolution images from LAION-5B.
Training duration
The training of StableDiffusion took 150,000 hours on an AWS A100 machine with 40GB VRAM.
Architecture
StableDiffusion uses the Text Encoder from CLIP and the AutoEncoder from UNet to construct the LatentDiffusionModel (diffusion model) then the final image.
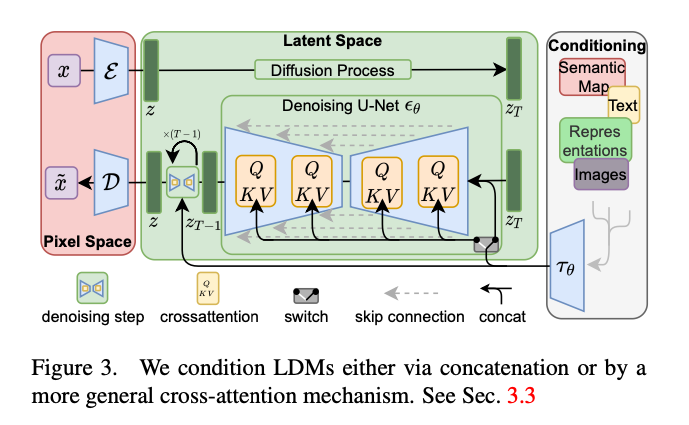
StableDiffusion architecture (Source: https://arxiv.org/abs/2112.10752)
The architecture of the image generation is similar to DALLE-2, which also uses CLIP features and diffusion models.
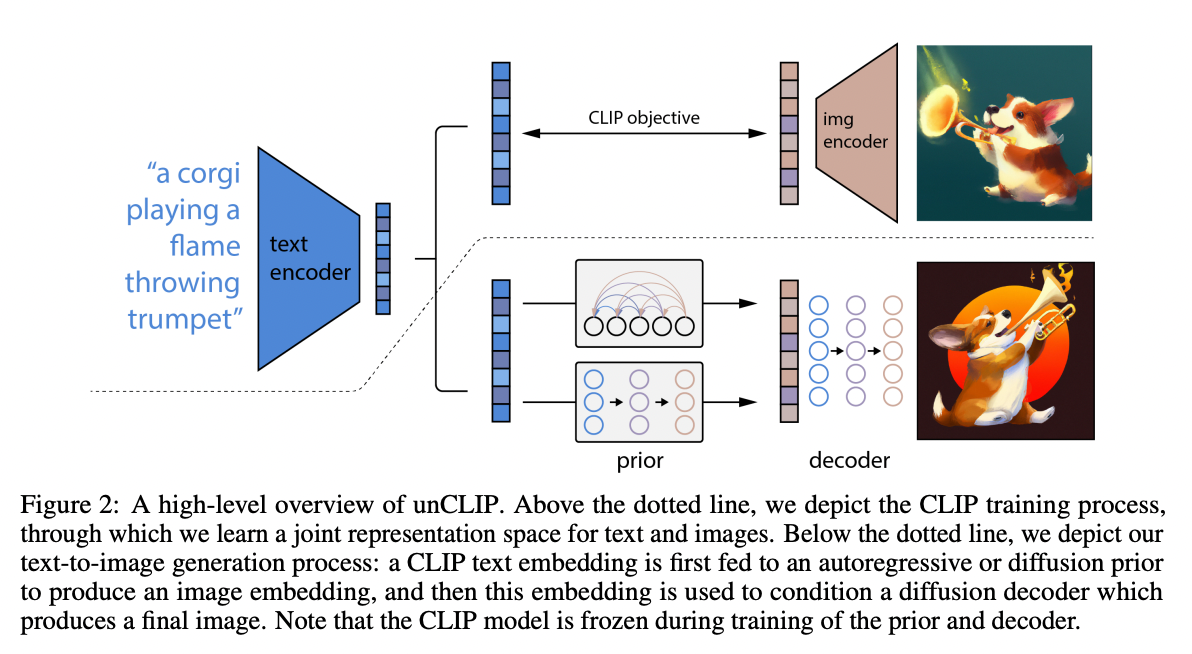
Source: https://cdn.openai.com/papers/dall-e-2.pdf
CLIP is trained on 400 million images on the Internet and can output the similarity between any text and image. Unlike conventional classifiers, it is trained with text pairs instead of labels, thus achieving zero-shot image classification even for unknown images. Since CLIP feature vectors have information that indicates the meaning of the image, they can be applied not only to image classification but also to image generation.
CLIP: Learning Transferable Visual Models From Natural Language SupervisionThis is an introduction to「CLIP」, a machine learning model that can be used with ailia SDK. You can easily use this…medium.com
First, CLIP’s text encoder is used to obtain feature vectors from the text. After converting each word into a word vector, the transformer extracts feature vectors that indicate the meaning of the text.
From the feature vector generated by the text encoder, a diffusion model in the space of feature vectors is used to generate a feature vector for the image encoder.
Finally, the image decoder is used to convert the feature vector into an image.
In the diffusion model, feature vectors are generated by starting from noise and repeatedly denoising. UNet is used for denoising.
It uses the same classifier-free guidance as GLIDE.
Support in ailia SDK
StableDiffusion currently requires Pytorch. We are investigating the possibility of converting the model to ONNX to run it with the ailia SDK.
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.