SPAN: Efficient Super-Resolution Model Using Parameter-Free Attention
This is an introduction to「SPAN」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
SPAN (Swift Parameter-free Attention Network for Efficient Super-Resolution) is a super-resolution model released in November 2023 by the Georgia Institute of Technology and Xiaomi. It ranked first in both overall performance and execution time in the NTIRE 2024 super-resolution challenge.
Main features
SPAN is a highly efficient super-resolution model that balances the number of parameters, inference speed, and image quality. Traditionally, model efficiency has been improved by reducing FLOPs and parameters to achieve faster processing. However, simply reducing FLOPs or parameters does not always lead to improved inference speed. SPAN accelerates the model while maintaining accuracy by introducing parameter-free attention.
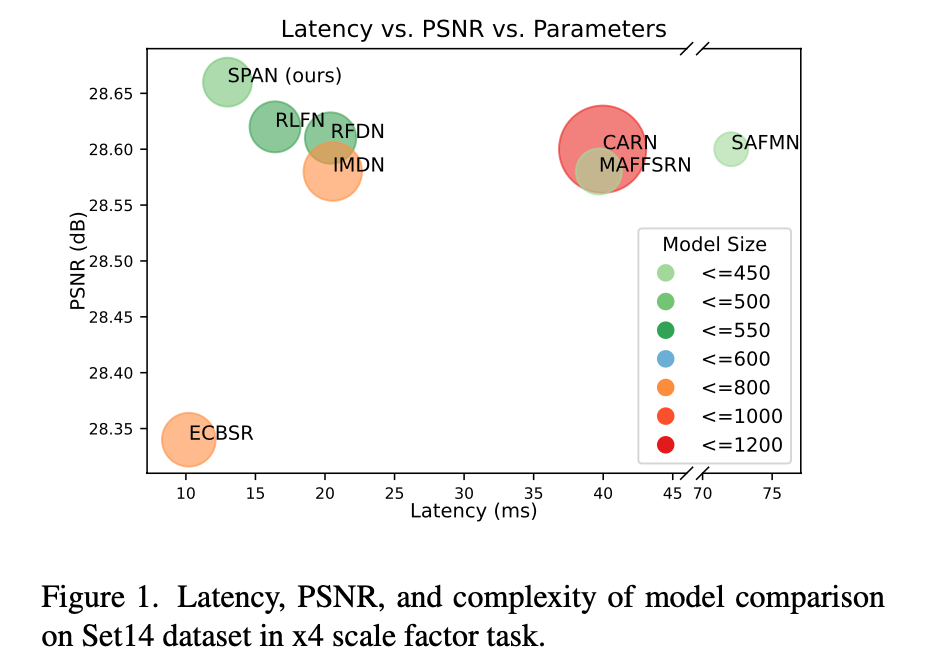
SPAN benchmark (Source: https://arxiv.org/abs/2311.12770)
Architecture
SPAN proposes a parameter-free attention mechanism. It directly computes the attention map using an activation function from high-level feature information generated by the convolutional layer.
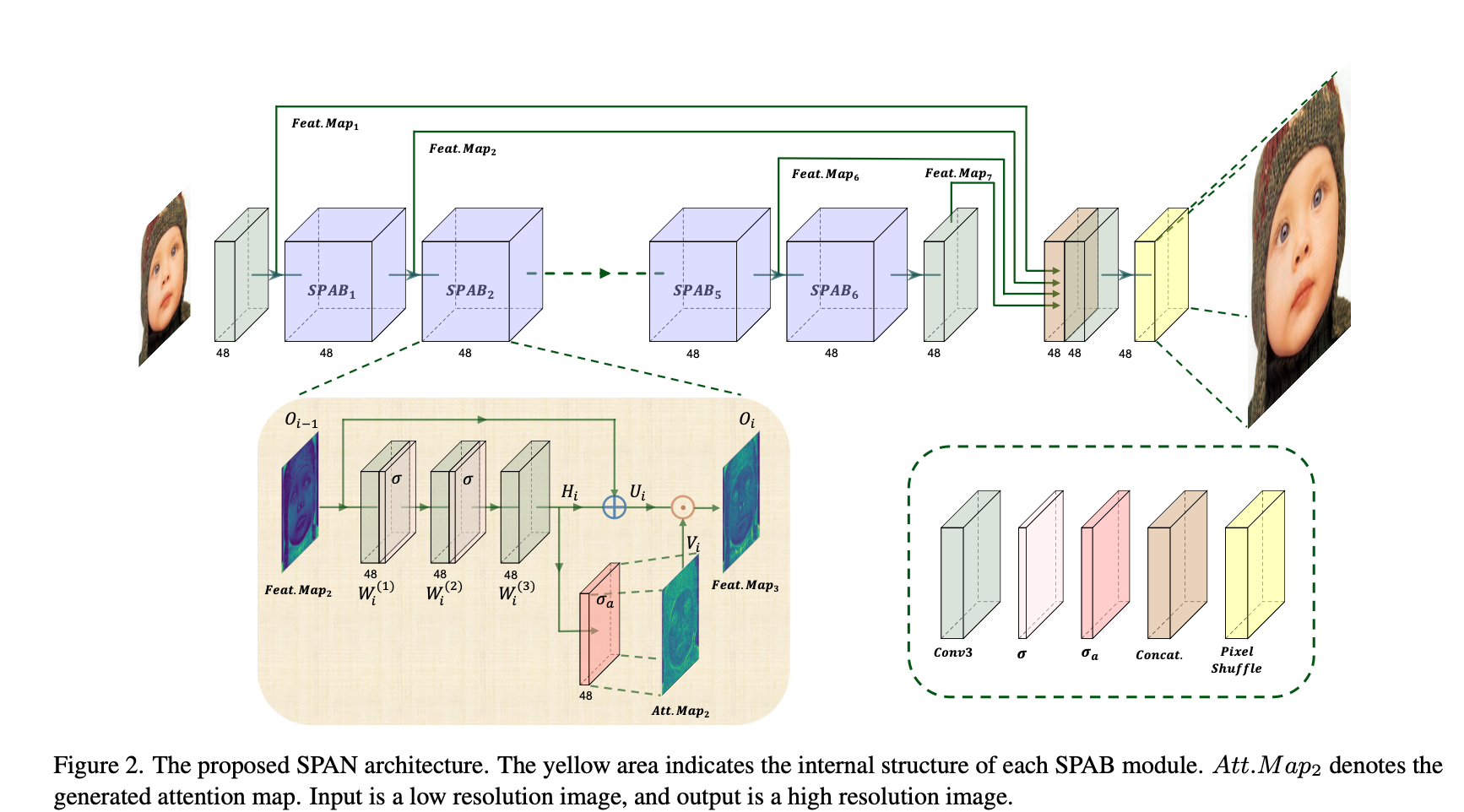
SPAN architecture (Source: https://arxiv.org/abs/2311.12770)
An attention map is necessary because a super-resolution model needs to focus on areas rich in local information, such as complex textures, edges, and color transitions. Without an attention map, the model is more prone to artifacts caused by blurring.
In SPAN, the edge and texture information required for attention is directly detected through convolutional kernels learned during training.

Output attention maps (Source: https://arxiv.org/abs/2311.12770)
Comparison with Transformer-based attention
In SPAN, Attention is designed to be parameter-free. This makes it different from the Attention mechanism in a typical Transformer in several ways.
In a standard Transformer Attention mechanism (e.g., Self-Attention), multiple linear transformations (usually for queries, keys, and values) are involved, and additional parameters are used to learn the relationships between elements.
On the other hand, SPAN directly utilizes the output of the Convolution layer to generate the Attention map, eliminating the need for additional trainable parameters or complex computations. This process has the following characteristics:
- Use of Symmetric Activation Functions: SPAN generates the Attention Map using symmetric activation functions, which enhances computational simplicity and speed.
- Parameter-Free: Since SPAN’s Attention mechanism does not introduce additional trainable parameters, the overall model complexity and computational cost remain low. In contrast, a typical Transformer’s Attention mechanism adds many parameters, increasing computational burden.
- Residual Connection: SPAN employs residual connections to minimize information loss while enabling efficient feature extraction. This helps balance information enhancement and retention within the Attention mechanism.
As a result, SPAN adopts a simpler and more efficient approach, significantly improving the trade-off between inference speed and performance. This makes it particularly practical in resource-constrained scenarios.
Benchmark to other SOTA models
The performance of SPAN is as follows: On the BSD100 dataset with 4× upscaling, it achieves a PSNR of 27.62 in just 13.67 ms. It is characterized by both high accuracy and speed.
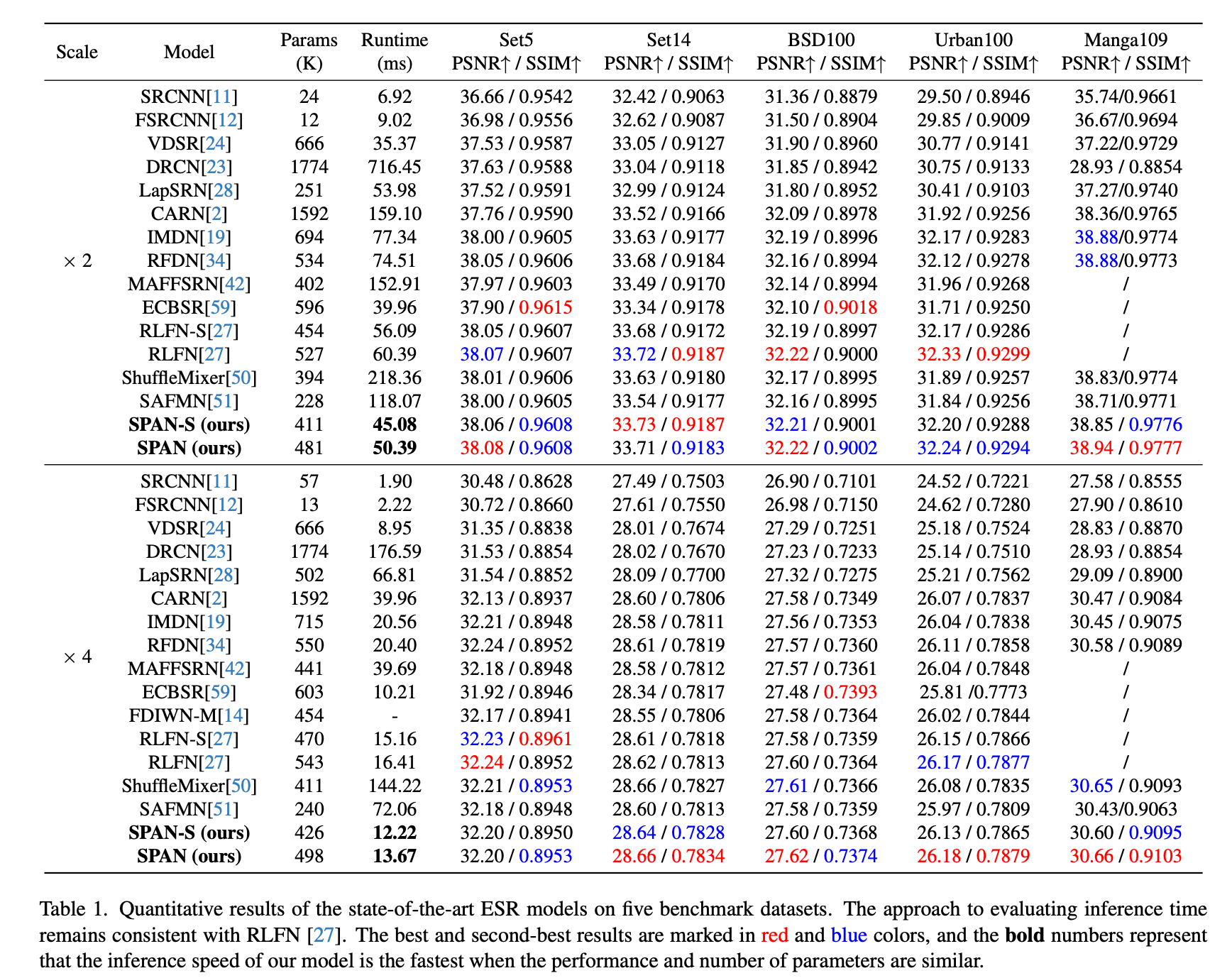
SPAN benchmark (Source: https://arxiv.org/abs/2311.12770)
Checkpoints
SPAN has four publicly available checkpoints, combining scaling factors of ×2 and ×4 with channel counts of 48 and 52.
Quality benchmark
This is a quality comparison between Real-ESRGAN and SPAN (×4, ch52). Real-ESRGAN tends to apply strong denoising, whereas SPAN preserves finer textures in the image compared to Real-ESRGAN.

RealESRGAN (Source: https://github.com/sanghyun-son/EDSR-PyTorch/blob/master/test/0853x4.png)
{kind=link}

SPAN (Source: https://github.com/sanghyun-son/EDSR-PyTorch/blob/master/test/0853x4.png)

RealESRGAN (Source: https://github.com/sanghyun-son/EDSR-PyTorch/blob/master/test/0853x4.png)

SPAN (Source: https://github.com/sanghyun-son/EDSR-PyTorch/blob/master/test/0853x4.png)
Performance benchmark
This is a speed comparison on an M2 Mac (ailia SDK 1.5) using MPS. SPAN runs significantly faster than Real-ESRGAN.
RealESRGAN (510x339 -> 1785x1186)
2989ms
SPAN (510x339 -> 2040x1356)
x4 ch48 : 139ms
x4 ch52 : 168ms
Usage
You can use SPAN in ailia SDK using the following command.
python3 span.py -i input.jpg
The scaling factor can be set to either 2× or 4×, with the default being 2× upscaling.
python3 span.py -i input.jpg --scale 4
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.