Qwen Audio: Text Generation from Audio Input
This is an introduction to「Qwen Audio」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
Qwen Audio is a multimodal version of the large model series Qwen, taking audio as input, released by Alibaba in November 2023. It allows users to input audio and generate text based on any given prompt.
Promptable audio language models are gaining attention for their ability to interact with audio. However, there were no pre-trained audio models trained on large-scale data.
Qwen Audio addresses this limitation by being pre-trained on large-scale data, enabling it to cover more than 30 tasks and various types of audio, including human speech, natural sounds, music, and singing, thereby enhancing universal audio understanding.
However, directly training on all tasks and datasets can lead to interference issues due to differences in task focus, language, annotation granularity, and text structure, which result in significantly varied text labels associated with different datasets.
To overcome this challenge, a multi-task training framework is designed to encourage knowledge sharing while avoiding interference. This is achieved by conditioning the decoder on a hierarchical sequence of tags, allowing shared and specific tags to be used effectively.
Building on the capabilities of Qwen Audio, Qwen Audio-Chat has been further developed to support both audio and text inputs, enabling multi-turn conversations and accommodating various audio-centric scenarios.
Architecture
In Qwen Audio, an audio encoder based on Whisper Large V2 is applied to the input audio, converting it into embeddings that capture its meaning. Then, a decoder based on Qwen 7B is used to generate text.
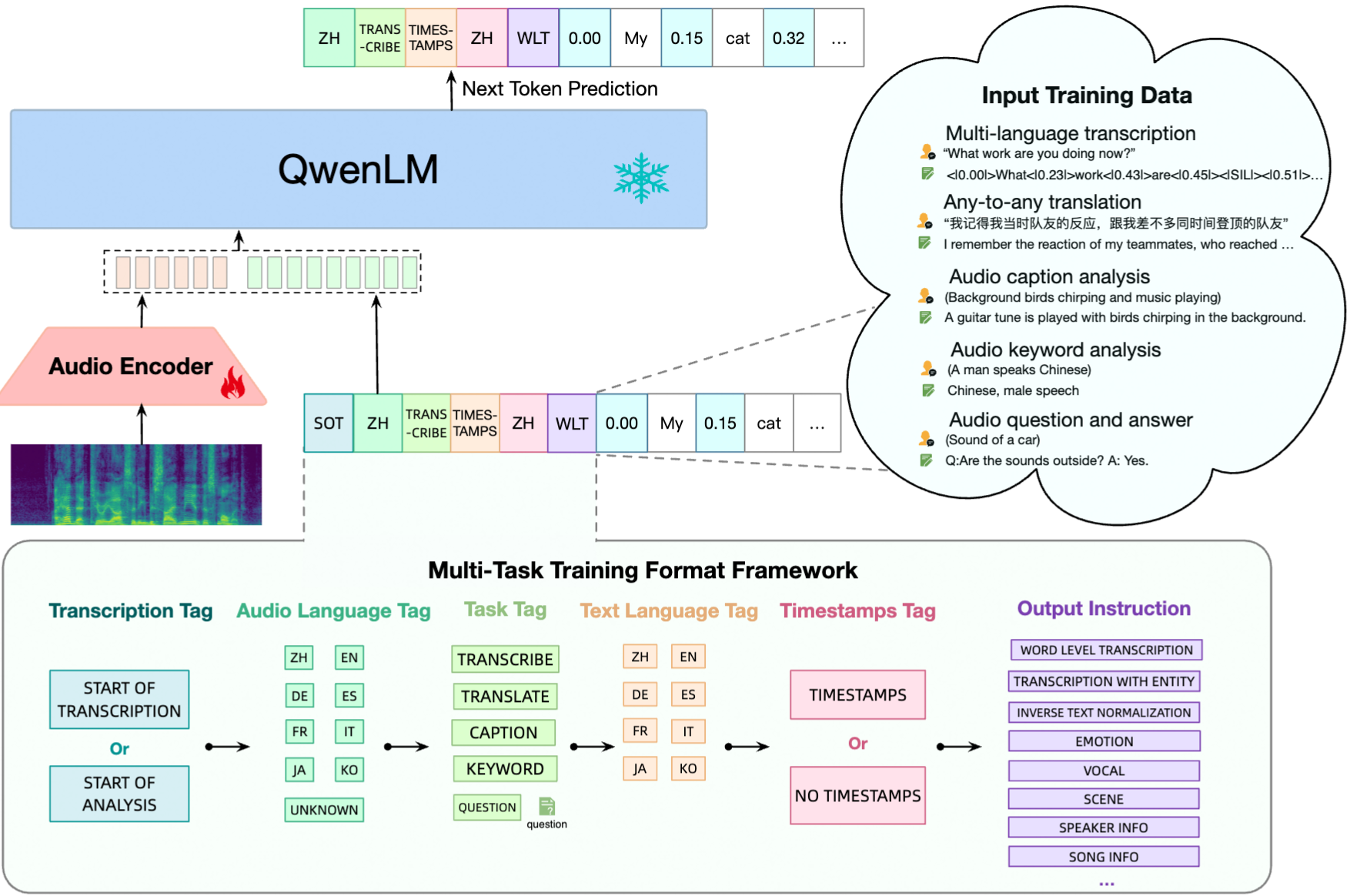
Qwen Audio architecture (Source: https://arxiv.org/abs/2311.07919)
Whisper Large V2 is a 32-layer Transformer model that includes two convolutional down-sampling layers. Its audio encoder consists of 640 million parameters. While Whisper Large V2 has been trained using supervised learning for speech recognition and translation, its encoded representations still contain rich information.
The language model is initialized with pre-trained weights derived from Qwen-7B, which is a 32-layer Transformer decoder model with 4,096 hidden units and a total of 7.7 billion parameters.
Tasks available
Qwen Audio supports various tasks, including:
- Automatic speech recognition
- Speech-to-text translation
- Speech recognition with word-level timestamps
- Automatic audio captioning
- Acoustic scene classification
- Speech emotion recognition
- Audio Question Answering
- Vocal sound classification
- Music note analysis
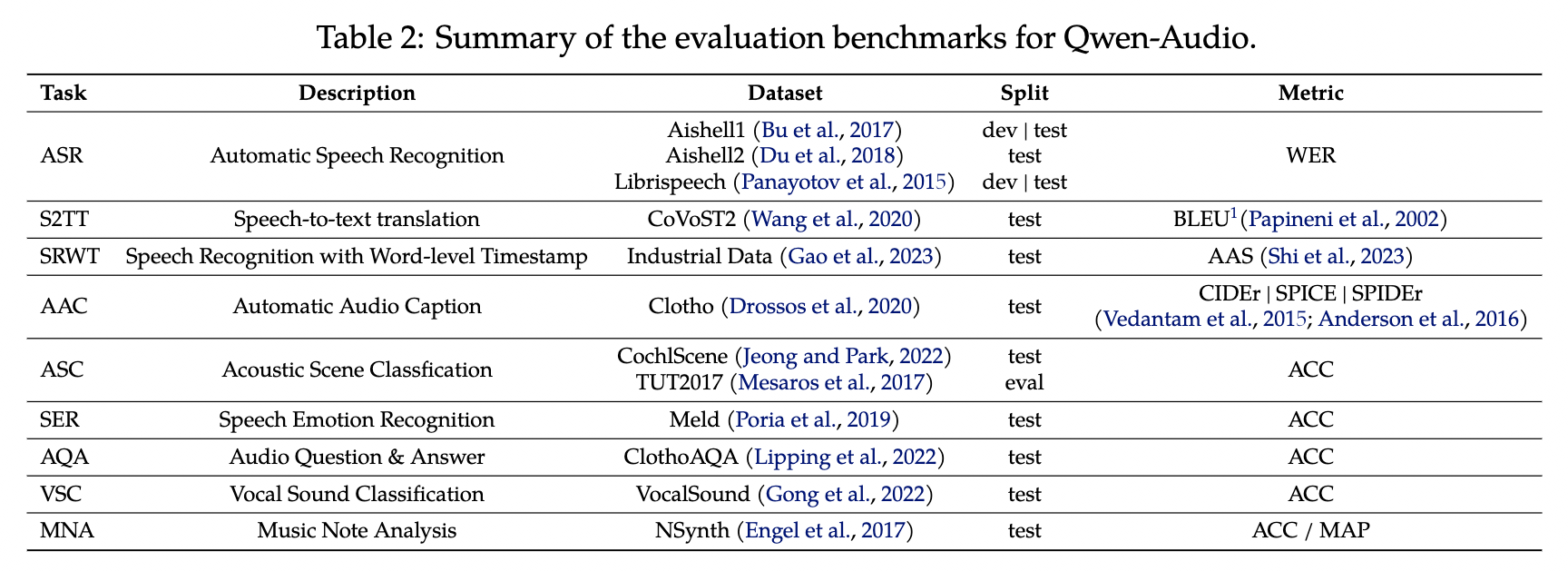
Qwen Audio tasks overview (Source: https://arxiv.org/abs/2311.07919)
The following datasets are used in Qwen Audio. In addition to speech recognition, diverse data is incorporated for tasks such as dialect identification, gender recognition, emotion recognition, speaker verification, speaker separation, speaker age prediction, vocal sound classification, acoustic scene classification, singer identification, instrument classification, musical note analysis, and audio genre recognition.
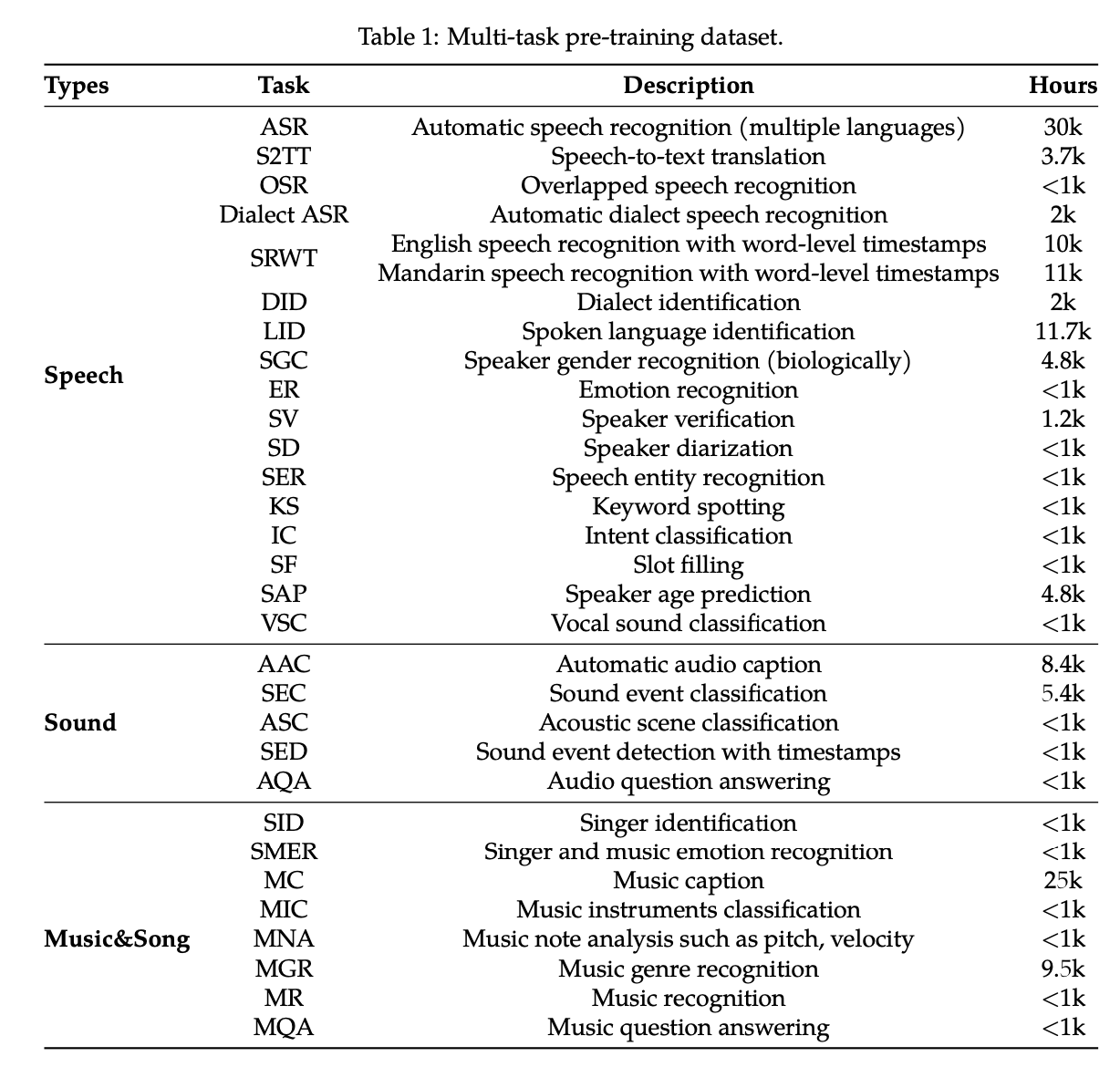
QwenAudio datasets (Source: https://arxiv.org/abs/2311.07919)
Performances
Qwen Audio achieves high performance across various benchmark tasks without the need for task-specific fine-tuning. This is a remarkable result, similar to the impact of BERT in natural language processing.

Qwen Audio performances (Source: https://arxiv.org/abs/2311.07919)
Usage
You can use Qwen Audio with ailia SDK with the following command. Since Qwen Audio utilizes a 7B-class decoder, approximately 32GB of memory is required. Additionally, execution may take some time.
python3 qwen_audio.py --input 1272-128104-0000.flac --prompt "what does the person say?"
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.