Prompt Engineering in Whisper
Whisper, an AI model for speech recognition also uses a language model internally, therefore we can apply some prompt engineering concepts to improve the recognition accuracy of unknown words.
Whisper Overview
Whisper is a speech recognition model developed by OpenAI, the company behind ChatGPT. Whisper converts the input speech into a feature vector and generates text based on this feature vector one character at a time in a language model. It was described in details in the following article.
Whisper : Speech recognition model capable of recognizing 99 languagesThis is an introduction to「Whisper」, a machine learning model that can be used with ailia SDK. You can easily use this…medium.com
Prompt engineering has been the focus of much attention recently with the success of ChatGPT. Let’s see how this concept can be applied to Whisper.
Prompt Engineering
Whisper uses the concepts of prompt and prefix as it is mentioned for example in this github discussion.
Here the prompt is a sequence of tokens given as prior information, typically a sequence of tokens decoded in the audio segment preceding the one currently being processed. Its goal is to keep a consistent output between segments by keeping track of previously transcribed information.
The prefix is a sequence of tokens representing a partial transcription for the current audio input, allowing for resuming the transcription after a certain point within the 30-second speech. The prefix is for example used for real-time transcription of live audio.
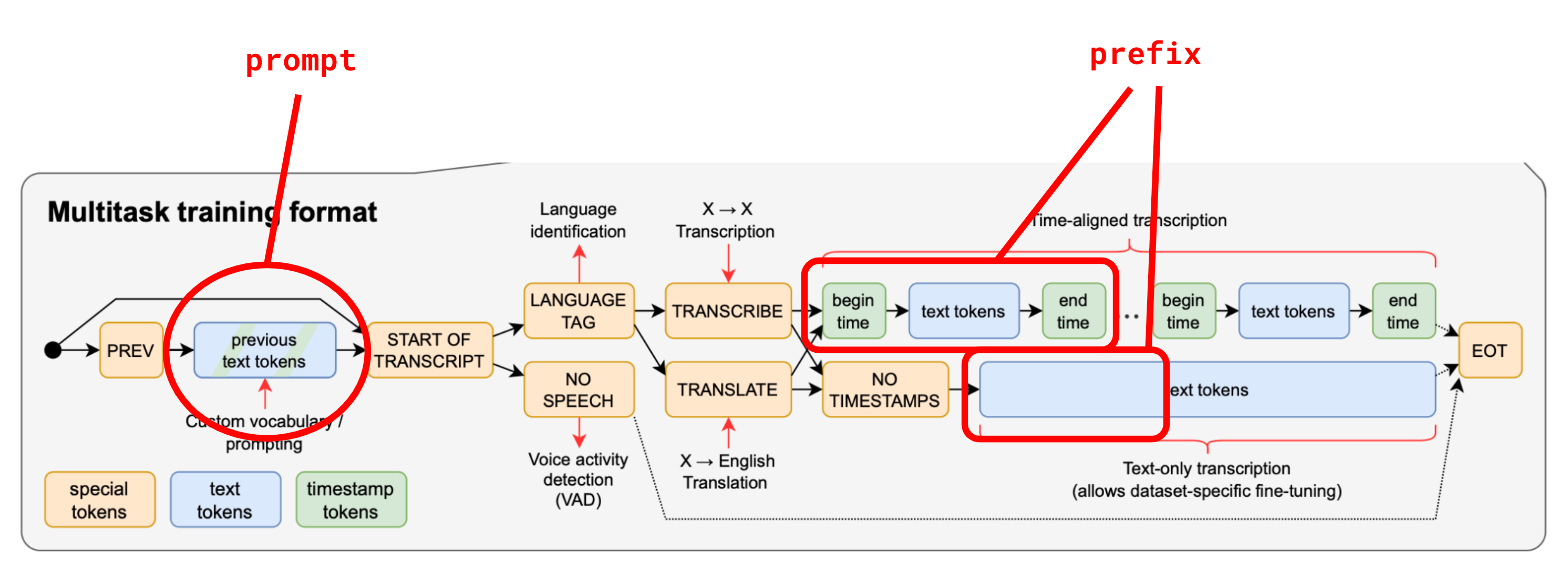
Concepts of prompt and prefix in Whisper (Source: https://github.com/openai/whisper/discussions/117#discussioncomment-3727051)
In the official Whisper implementation, a prompt can be given as input via the initial_prompt string argument. It is possible to customize Whisper by embedding non-textual information from one previous audio segment in this prompt.
Applications of Custom Prompts
A useful use of custom prompt is to improve the recognition unknown words such as of people’s names and technical terms.
Another interesting use case of custom prompts is to clearly mark the change of speaker by an hyphen in a transcribed conversation. This can be done using the following initial prompt, where an hyphen is inserted between the question and its answer, however is does not work for all languages.
initial_prompt="- How are you? - I'm fine, thank you."
Prompt Constraints
The size of the context in Whisper is 448, which represents the total number of tokens for input and output, but the official Whisper implementation is constrained to half the number of tokens for input, up to 224 tokens. If your custom prompt needs to be larger, for example if your transcription contains a lot of unknown words, then other methods have to be used.
We mentioned the initial_prompt parameter earlier that can be used to give a custom prompt. However this will only be used in the first 30 seconds speech, because in the next segment the prompt is overwritten by the decoding result of the current segment.
As suggested in the github discussion below, the ailia MODELS implementation applies the prompt argument to segments other than the first, so it is possible to keep the custom prompt across segments.
Below is an usage example of prompts with ailia MODELS.
python3 whisper.py -i recording.m4a --prompt "openai chatgpt"
About ailia Speech
ailia Inc. provides a library that allows AI speech recognition using Whisper to run offline as a Unity or C++ API, including custom prompt features.
ailia AI Speech : Speech Recognition Library for Unity and C++Introducing ailia AI Speech, an AI speech recognition library which allows you to easily implement speech recognition…medium.com
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.