LLaVA: Large Language Model That Understands Images
This is an introduction to「LLaVA」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
LLaVA is a large language model which original version was released in December 2023 by the University of Wisconsin-Madison, Microsoft Research, and Columbia University. Similar to OpenAI’s GPT-4V (V for Vision), it allows you to input images and ask questions about them through prompts.
Architecture
One of the key challenges in developing multimodal (text + image) AI models is the lack of sufficient training data. LLaVA addresses this by designing a pipeline that builds a training dataset, named LLaVA-Instruct-150K, of images augmented with what they call “instructions” using a large language model that handles only text.
Instead of using GPT-4V, which can process images, LLaVA employs GPT-4, which cannot handle images, to construct the dataset. The input context of GPT-4 consists of captions describing the images and the bounding boxes within the images. By passing in captions and bounding box locations to the language-only model paired with the understanding of the image, you can form conversations about the image in a cheap and efficient manner. Based on this context, GPT-4 generates responses that include conversations, detailed descriptions, and complex reasoning.

Source: https://arxiv.org/pdf/2304.08485
Next, the dataset made of all those GPT-4-generated responses is linked with the source images through AI model training described hereafter.
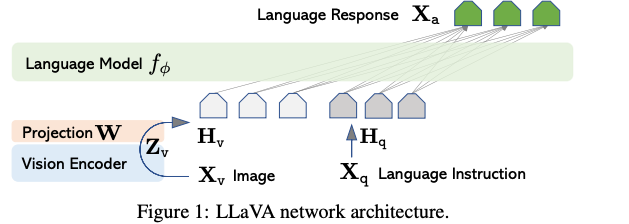
LLaVA architecture (Source: https://arxiv.org/pdf/2304.08485)
For images, LLaVA employs a pre-trained CLIPvisual encoder, which excels in processing visual content by extracting meaningful features from images and videos.
The language component, Vicuna, is a sophisticated llama2-based language model that handles the textual input, maintaining context and generating responses.
The image features computer by the visual encoder are then connected to language embeddings through a projection matrix. This allows input images and input text to be mapped to the same embedding space, allowing the LLM to understand the context from both the image and the input prompt in a unified manner.
Usage examples
When presented with the image shown below and asked, “What is unusual about this image?” LLaVA can respond that ironing at the back of a minivan is what makes the situation unusual.
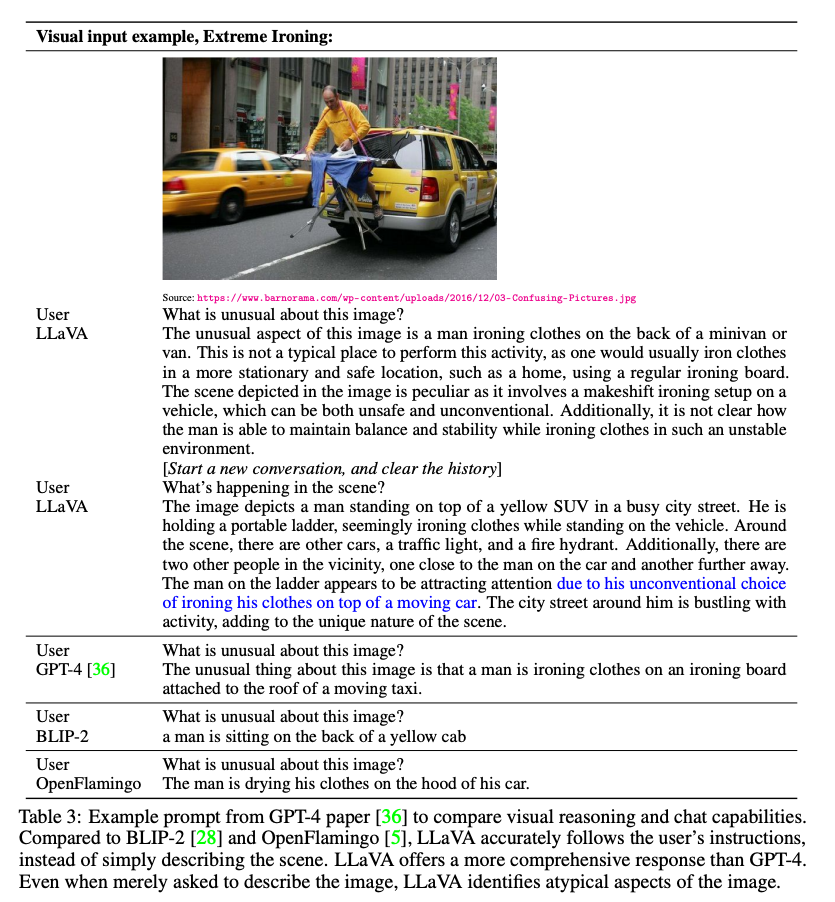
Source: https://arxiv.org/pdf/2304.08485
Main iterations
The original LLaVA model has been improved with the following updates:
- LLaVA-1.5 integrates academic task-oriented data, improving performance on VQA, OCR, and region-level perception tasks.
- LLaVA-1.6 (LLaVA-NeXT) expanded support for different LLMs, increased input image resolution to 4x more pixels, and improved reasoning capabilities overall.
LLaVA-NeXT also has various improved versions on its own, details available at the blog below:
LLaVA-NeXT — Versionsllava-vl.github.io
There are also many specialized version of LLaVA such as
- LLaVA-RLHF which uses a new alignment algorithm that augments the reward model with additional factual information. This is a significant development in aligning large multimodal models with human preferences and reducing hallucinations.
- LLaVA-Med which can answer open-ended research questions on biomedical images
Usage with ailia SDK
To use LLaVA with the ailia SDK, you can use the following command. It requires approximately 28GB of memory in FP32, if you don’t have sufficient VRAM, you can run it on the CPU using the -e 1 option.
$ python3 llava.py --input input.jpg --prompt "What are the things I should be cautious about when I visit here?" -e 1
Let’s run this example prompt “What are the things I should be cautious about when I visit here?” on the following image.

Source: https://llava-vl.github.io/static/images/view.jpg
{kind=link}
Here is the response we get:
When visiting this location, which features a pier extending over a large body of water, you should be cautious about several things. First, be mindful of the weather conditions, as the pier may be affected by strong winds or storms, which could make it unsafe to walk on. Second, be aware of the water depth and currents, as they can change rapidly and pose a risk to swimmers or those who venture too close to the edge. Additionally, be cautious of the presence of any wildlife in the area, as they may pose a potential danger or distraction. Finally, be mindful of the pier's structural integrity, as it may be subject to wear and tear over time, and it is essential to ensure that it is safe for use.
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.