Grounding DINO: Detect Any Object from Text
This is an introduction to「Grounding DINO」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
Grounding DINO is an object detection model capable of detecting any object. By inputting the object you want to detect in text, you can obtain the bounding box for that object within an image.
Grounding DINO ouput (Source: )https://github.com/IDEA-Research/Grounded-Segment-Anything/blob/main/assets/demo7.jpg)
{kind=link}
Architecture
GLIP(starting with a G, stands for Grounded Language-Image Pre-training)has been proposed as the object detection version of CLIP, which calculates candidate regions and embeddings for objects using a Visual Encoder and text embeddings using a Text Encoder. The Word-Region Alignment Score is then computed by taking the dot product of these embeddings. This enables object detection based on any given text.
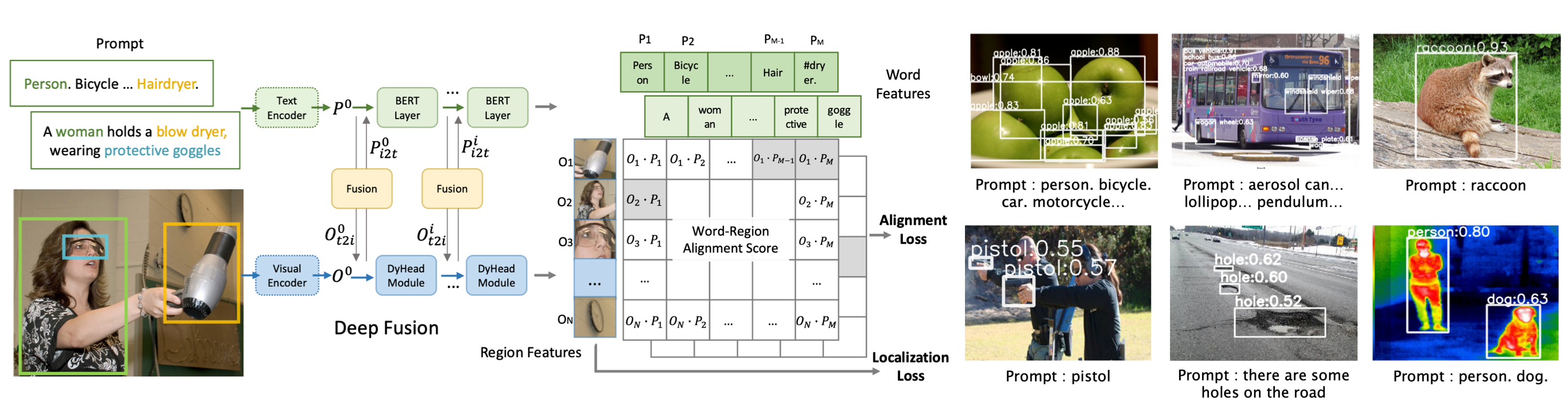
GLIP architecture (Source: https://github.com/microsoft/GLIP)
Additionally, DINO (DETR with Improved No-objects) has been proposed as an object detector using the Transformerarchitecture instead of the usual algorithm based on anchor boxes and overlaps of ROI, that have been mainly used until now in models such as YOLO. This change of methodology is referred to as DETR (DEtection TRansformers), which removes the need for fixed algorithms like NMS (Non-Max Suppression), allowing for End-to-End optimization.
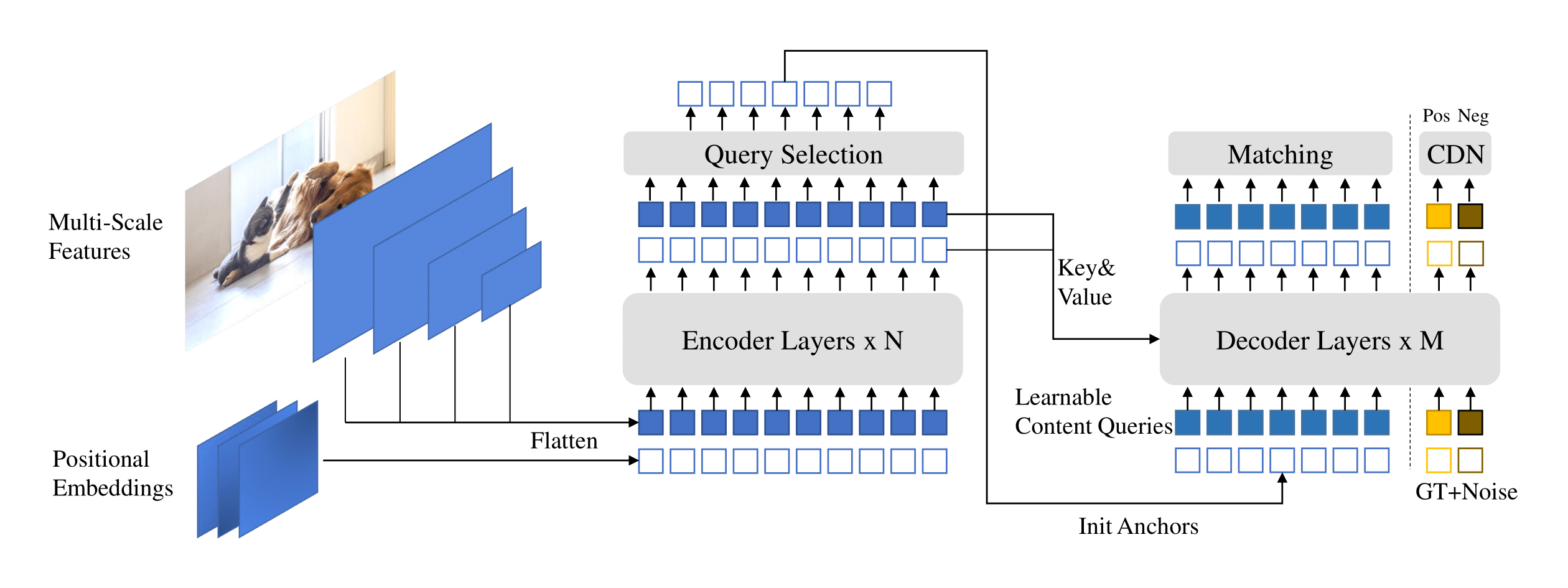
DINO architecture (Source: https://github.com/IDEA-Research/DINO)
Grounding DINO is a model architecture that combines the object detection component of GLIP with DINO.
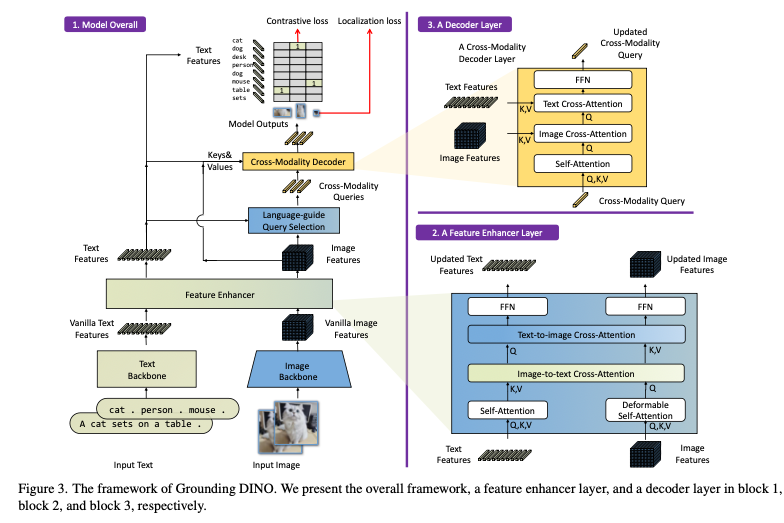
Grounding DINO architecture (Source: https://arxiv.org/abs/2303.05499)
For text tokenization, Grounding DINO uses the BERT-base model, similar to GLIP.
Usage
To use Grounding DINO with ailia SDK, use the following command to specify the input image and the label of the object(s) you want to detect.
python3 groundingdino.py -i input.jpg --caption "Horse. Clouds. Grasses. Sky. Hill."
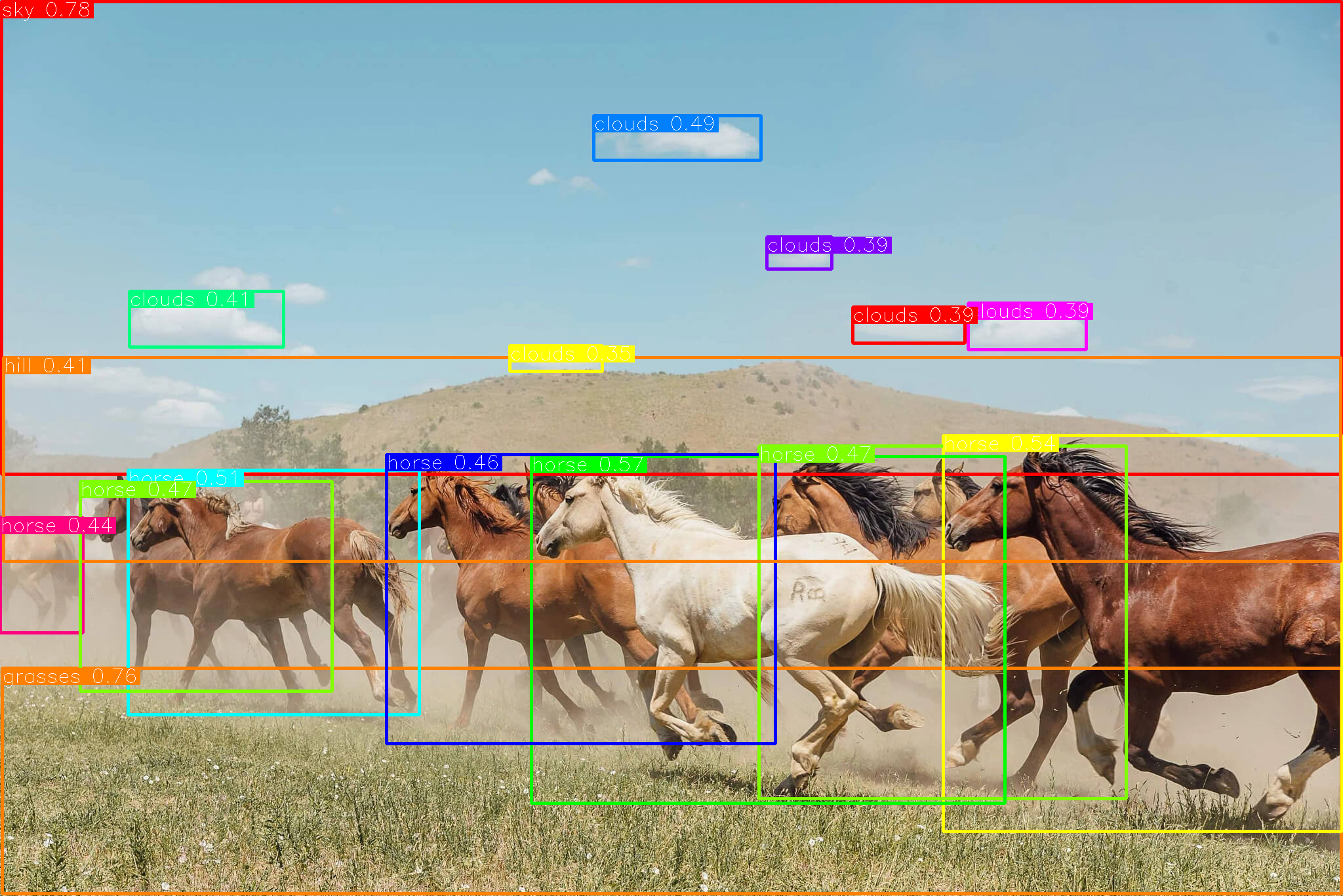
Let’s see how this model performs on the sample picture taken from Detic.
{kind=link}
blue bottle

red cup

web camera

References
DINO Paper — DETR with Improved DeNoising Anchor Boxes for End-to-End Object Detection
GLIP Paper — Grounded Language-Image Pre-training
Grounding DINO Paper — Grounding DINO: Marrying DINO with Grounded Pre-Training for Open-Set Object Detection
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.