Florence2: Lightweight Vision Language Model For Edge Deployment
This is an introduction to「Florence2」, a machine learning model that can be used with ailia SDK. You can easily use this model to create AI applications using ailia SDK as well as many other ready-to-use ailia MODELS.
Overview
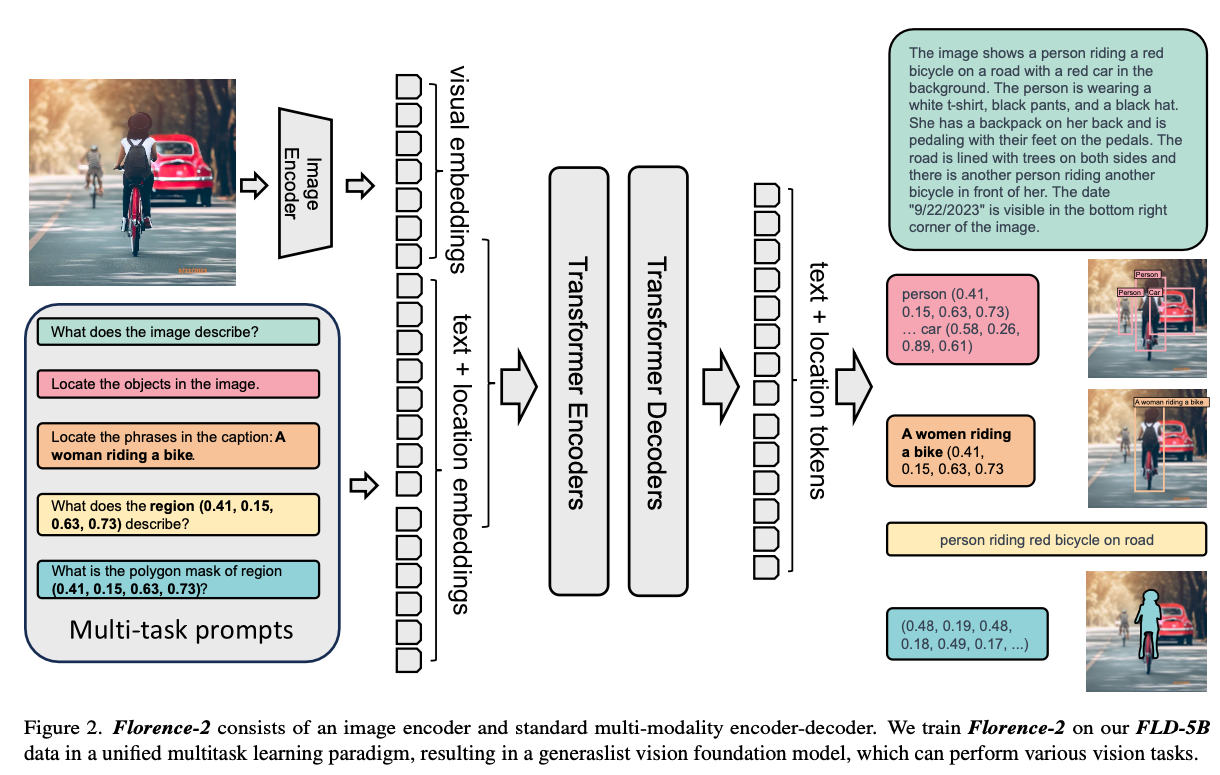
Florence2 is a lightweight Vision Language Model (VLM) developed by Microsoft released in November 2023. It can generate captions for input images, calculate bounding boxes, perform OCR, and handle segmentation.
Florence 2 characteristics
Florence2 is lighter than LLAVA, the well-known open-source VLM, and can be deployed on edge devices. Additionally, it achieves higher accuracy than the captioning model BLIP2.
However, being lightweight also means that it doesn’t support free-form prompts like LLAVA does. Florence2 only supports fixed prompts. For example, for image captioning tasks, it uses the fixed prompt “What does the image describe?”. If you change it to something like “How many cars exist?”, it won’t produce the correct output.
If you want to use custom prompts, you would need to first convert the image to text with Florence2, then input that text along with the prompt into a separate LLM.
Training data
Florence2 creates large-scale datasets without relying on human labor. This dataset, named FLD-5B, consists of 1.26 billion images with 5.4 billion annotations.
The dataset creation was performed using other models and services such as Segment Anything, Azure Document Intelligence (OCR), Grounding Dino, and LLM. Bounding boxes for object detection tasks are also treated as text information.
Florence2 relies on those various large-scale models to create datasets, but the result of training on these datasets is a very lightweight model.
Architecture
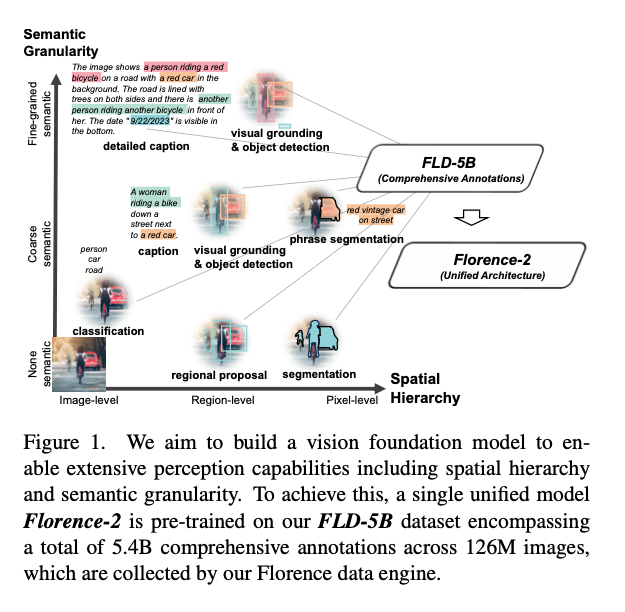
Florence2 uses Sequence-to-Sequence and formulates all tasks as translation problems.
For the object detection task, it uses (x0, y0, x1, y1) to represent a bounding box. For the OCR task, the quad box is defined as (x0, y0, x1, y1, x2, y2, x3, y3), and the polygon representation of a segmentation masks is defined as(x0, y0, …, xn, yn).
The input prompt is tokenized by a Tokenizer and embedded by a Text Encoder. The input image is resized to 768x768 and embedded by a Vision Encoder.
If the input prompt is “What does the image describe?”, it is tokenized as [0 2264 473 5 2274 6190 116 2], resulting in an embedding of shape (1, 8, 768).
The text and image embeddings are concatenated and input into the Encoder to obtain the hidden state, which is then output one token at a time by the Decoder.
The Tokenizer is BartTokenizer. The model architecture uses DaVIT for the Vision Encoder and a standard Transformer with LayerNorm in both the Encoder and Decoder.
Usage
Florence2 can be used with ailia SDK using the following command.
python3 florence2.py -i input.jpg -p CAPTION
You can specify any of the following pre-defined prompts depending on the task to achieve.
choices=[
"CAPTION",
"DETAILED_CAPTION",
"MORE_DETAILED_CAPTION",
"CAPTION_TO_PHRASE_GROUNDING",
"OD",
"DENSE_REGION_CAPTION",
"REGION_PROPOSAL",
"OCR",
"OCR_WITH_REGION",
],
Here is the result on the following image.

Source: https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/car.jpg
The DETAILED_CAPTION output would be:
{'<MORE_DETAILED_CAPTION>': 'The image shows a vintage Volkswagen Beetle car parked on a cobblestone street in front of a yellow building with two wooden doors. The car is a light blue color with a white stripe running along the side. It has a round body and a small rear window. The wheels are silver with black rims. The building appears to be old and dilapidated, with peeling paint and crumbling walls. The sky is blue and there are trees in the background.'}
ailia Inc. has developed ailia SDK, which enables cross-platform, GPU-based rapid inference.
ailia Inc. provides a wide range of services from consulting and model creation, to the development of AI-based applications and SDKs. Feel free to contact us for any inquiry.