CLAP : テキストから音声を検索可能にする特徴抽出モデル
テキストから音声を検索可能にする特徴抽出モデルであるCLAPのご紹介です。CLAPを使用することで、テキストと音声から特徴ベクトルを抽出し、距離計算を行うことで、テキストから音声検索が可能となります。
CLAPの概要
CLAPは、LAION-AIが2022年11月に発表した、テキストから音声を検索可能にする特徴抽出モデルです。テキストから画像を検索可能にするCLIPの音声版となります。

CLAP(出典:https://github.com/LAION-AI/CLAP)
画像向けのCLIPはOpenAIがLAION-5Bで学習したものであり、CLAPはデータセットの開発元のLAION-AIが学習も行なったものとなります。
CLAPを使用することで、入力されたテキストと音声から特徴ベクトルを取得することができ、特徴ベクトル同士の距離を計算することで、テキストと音声の類似度を計算することができます。
CLAPのアーキテクチャ
近年、インターネット上の大規模なデータを使用した学習が行われています。代表的なのはCLIPで、大規模なテキストと画像のペアによる学習を行うことで、テキストから画像の検索を実現し、大きな成功を収めています。
この方式は、テキストと音声でも同様でも実現可能であると考えられます。関連研究として、AudioCLIPやWaveCLIPが提案されていますが、これらは画像と音声、もしくはテキストと画像と音声のペアで学習されており、テキストと音声のペアによるモデルではありません。また、これらは小規模なデータセットで学習されており、テキストと音声のペアでの学習の真価を発揮できていません。
CLAPは、633,526のテキストと音声のペアで構築された、大規模なLAION-Audio-630Kを使用して学習されています。
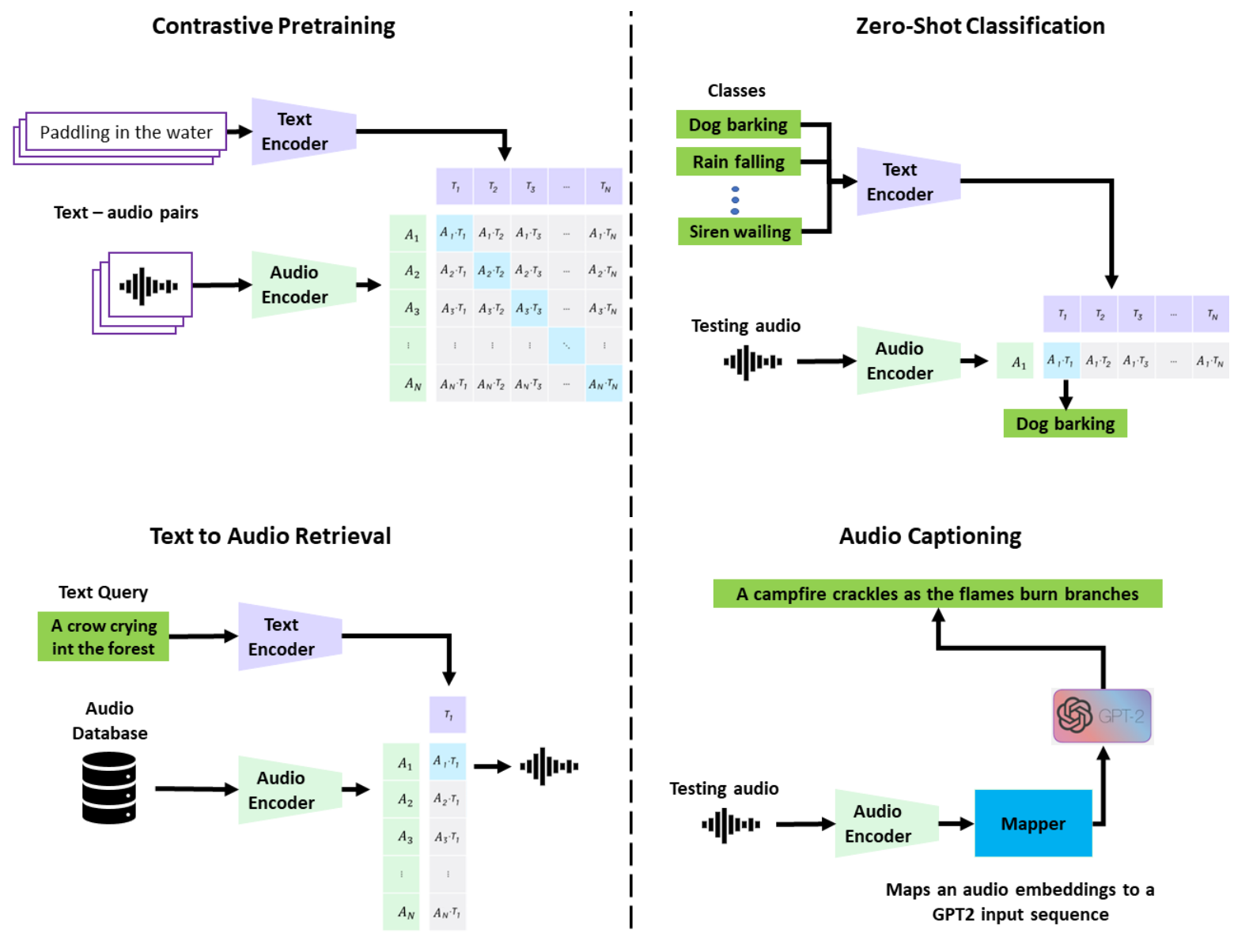
CLAPのアーキテクチャは下記となります。CLIPと同様に、テキストと音声のペアで距離が小さくなるように学習されており、テキストもしくは音声を与えることで、特徴ベクトルを計算可能です。この特徴ベクトル同士の距離を計算することで、任意のテキストから音声を検索可能です。
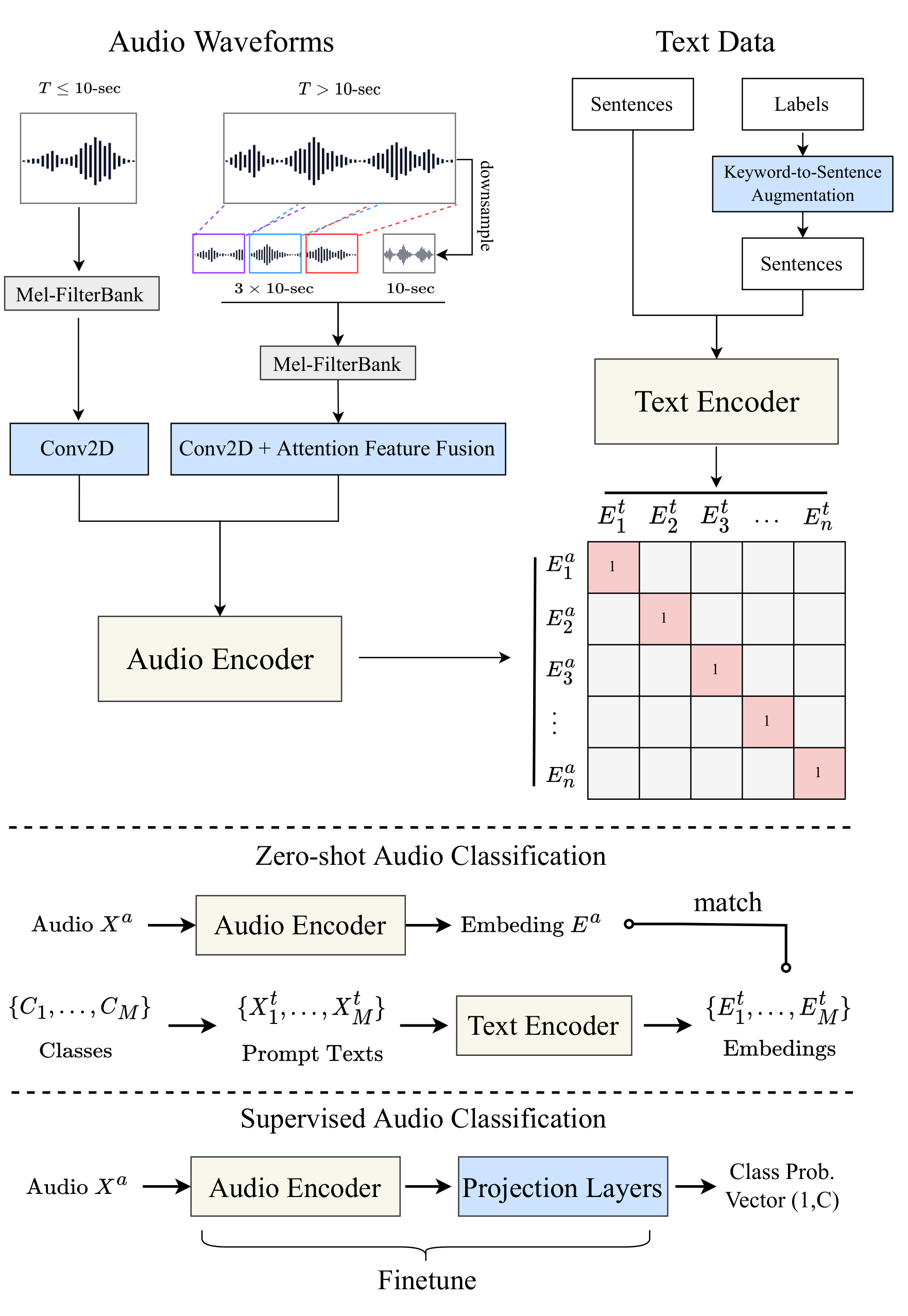
出典:https://github.com/LAION-AI/CLAP
テキストのトークナイザにはRobertaTokenizerを使用しています。RobertaTokenizerは、CLIPと同様にBPEベースのトークナイザとなります。
音声は、MelSpectrum空間で処理を行います。librosaでMelSpectrumに変換して使用します。mel_binsは64で、window_sizeは1024、hop_sizeは480を使用しています。
音声が10秒未満の場合は、N回リピートした後、端数を0パディングします。その後、同じ波形を4つStackしたものを入力とします。音声が10秒以上の場合は、音声の前半、中盤、後半の3つをランダムに選択したものと、全体をリサンプルしたものの、合計4つの波形をStackして使用します。そのため、AIモデルに入力する音声データの形状は(4, 1001, 64)となります。4はStack分、1001は10秒分、64はmel_binsが対応します。
このように、4つの波形をStackするモデルをFusionモデルと呼びます。Fusionを使用しないモデルの場合、10秒になるようにランダムクロップします。
AIモデルの出力する特徴ベクトルの次元数は512です。距離計算にはCos Similarityを使用します。
CLAPの精度
CLAPの精度は下記となります。環境音を分類する、ESC-50データセットにおける0ショット(再学習なし)での認識精度を比較しています。なお、CLAP自体は任意のテキストを使用して分類可能なため、ESC-50に含まれるカテゴリ以外も認識可能です。
ESC50データセットのカテゴリ(出典:https://github.com/karolpiczak/ESC-50)
CLAPはLAION版以外にも複数の著者によるものがあります。従来技術として比較対象となっているCLAP [5]はWavText5Kの5Kのデータセットで学習されたモデルとなります。LAION版のCLAPは、630Kのデータセットを用いることで、0ショットでの分類精度を、82.6%から89.1%まで改善しています。
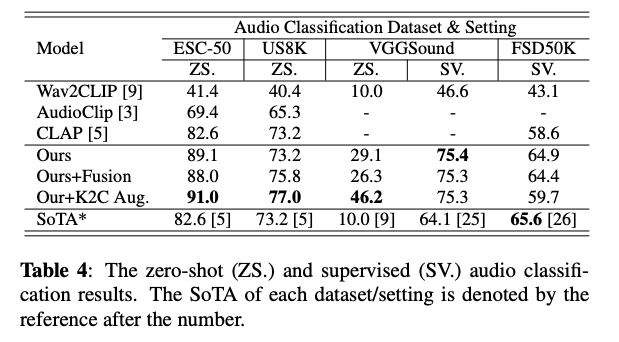
精度(出典:https://arxiv.org/pdf/2211.06687.pdf)
2023年バージョン
2023.4.7にLargeモデルが公開されています。これらのモデルは、LAION-Audio-630kデータセットに加えて、MusicとSpeechのデータセットを加えたものです。これらのモデルは、Fusionモデルではなく、通常モデルとなり、4つの波形をStackするのではなく、10秒に収まるようにランダムクロップしています。また、Audio EncoderにAudio TokenベースのHTSATを使用しています。
Microsoftバージョン
MicrosoftもMicrosoftバージョンのCLAPを公開しています。Microsoftバージョンでは、128Kのaudioとtextのペアで学習を行っています。
MicorosoftバージョンのCLAPも、LAIONバージョンのCLAPと同じアーキテクチャを持っており、ESC50 datasetで93.9%の精度を達成しています。
ESC50 Accuracy: 93.9%
出典:https://github.com/microsoft/CLAP
CLAPの使用方法
ailia SDKでLAION-CLAPを使用するには、下記のコマンドを使用します。
$ python3 clap.py --input dog_bark.wav
出力結果は下記となります。指定したテキストラベルごとに確率が表示され、dogおよびdog barkingが最も近いことがわかります。
===== cosine similality between text and audio =====
cossim=0.1514, word=applause applaud clap
cossim=0.2942, word=The crowd is clapping.
cossim=0.0391, word=I love the contrastive learning
cossim=0.0755, word=bell
cossim=-0.0926, word=soccer
cossim=0.0309, word=open the door.
cossim=0.0849, word=applause
cossim=0.4183, word=dog
cossim=0.3819, word=dog barking
検出対象のタグを変更したい場合は、clap.pyのtext_inputsを書き換えてください。
text_inputs = [
"applause applaud clap",
"The crowd is clapping.",
"I love the contrastive learning",
"bell",
"soccer",
"open the door.",
"applause",
"dog",
"dog barking"
]
voiceとsongカテゴリを追加して、人の声に対して処理をした結果は下記となります。voiceカテゴリのスコアが最も高くなります。
===== cosine similality between text and audio =====
audio: BASIC5000_0001.wav
cossim=0.0891, word=applause applaud clap
cossim=0.1216, word=The crowd is clapping.
cossim=0.0633, word=I love the contrastive learning
cossim=0.1159, word=bell
cossim=-0.0559, word=soccer
cossim=-0.0210, word=open the door.
cossim=0.0098, word=applause
cossim=-0.0106, word=dog
cossim=-0.0605, word=dog barking
cossim=0.2877, word=voice
cossim=0.1041, word=song
歌を入力すると、songカテゴリのスコアが最も高くなります。
===== cosine similality between text and audio =====
audio: 049 - Young Griffo - Facade.wav
cossim=0.0767, word=applause applaud clap
cossim=0.0737, word=The crowd is clapping.
cossim=-0.0014, word=I love the contrastive learning
cossim=-0.0110, word=bell
cossim=-0.0063, word=soccer
cossim=-0.0065, word=open the door.
cossim=0.0440, word=applause
cossim=0.0031, word=dog
cossim=-0.0542, word=dog barking
cossim=0.0625, word=voice
cossim=0.2091, word=song
内部的には、音声とテキストから、512次元の特徴ベクトルが計算され、音声とテキストとの距離計算が行われるため、この特徴ベクトルを使用することで、クラスタリングや、音声同士の距離計算なども可能です。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。