BERTのONNXモデルをFP16で推論可能にする
BERTをONNXにエクスポートした際、FP16で推論できない場合があります。このようなケースでの原因の調査方法と、推論を行えるように修正する方法を解説します。
BERTについて
BERTは自然言語処理のモデルです。ビッグデータで学習したBERTを転移学習することで、少量のデータで、さまざまな自然言語を行うことが可能になります。
日本語BERT(https://huggingface.co/cl-tohoku)
BERTのONNX変換
Transformersに含まれるconvert_graph_to_onnx.pyを使用することで、BERTをONNXに変換することが可能です。
python3 convert_graph_to_onnx.py — framework pt — model cl-tohoku/bert-base-japanese-whole-word-masking ./work/bert-base-japanese-whole-word-masking.onnx — pipeline fill-mask
BERTのONNX変換の課題
Transformers 4.29.2でBERTをONNXに変換すると、FP32では正常に推論できますが、FP16では出力が不正になります。
FP32の推論結果
INFO bert_maskedlm.py (82) : Input text : 私[MASK]お金で動く。
INFO bert_maskedlm.py (85) : Tokenized text : ['私', '[MASK]', 'お', '金', 'で', '動', 'く', '。']
INFO bert_maskedlm.py (97) : Indexed tokens : [1007, 4, 87, 352, 17, 167, 66, 10]
INFO bert_maskedlm.py (112) : Predicting...
INFO bert_maskedlm.py (126) : Predictions :
INFO bert_maskedlm.py (130) : 0 の
INFO bert_maskedlm.py (130) : 1 は
INFO bert_maskedlm.py (130) : 2 [UNK]
INFO bert_maskedlm.py (130) : 3 、
INFO bert_maskedlm.py (130) : 4 (
FP16の推論結果
INFO bert_maskedlm.py (82) : Input text : 私[MASK]お金で動く。
INFO bert_maskedlm.py (85) : Tokenized text : ['私', '[MASK]', 'お', '金', 'で', '動', 'く', '。']
INFO bert_maskedlm.py (97) : Indexed tokens : [1007, 4, 87, 352, 17, 167, 66, 10]
INFO bert_maskedlm.py (112) : Predicting...
INFO bert_maskedlm.py (126) : Predictions :
INFO bert_maskedlm.py (130) : 0 [CLS]
INFO bert_maskedlm.py (130) : 1 [MASK]
INFO bert_maskedlm.py (130) : 2 [PAD]
INFO bert_maskedlm.py (130) : 3 [UNK]
INFO bert_maskedlm.py (130) : 4 [SEP]
原因の特定
どのレイヤーで出力が不正になるかを確認するため、ailia SDKを使用して全てのテンソルの値を出力します。ailia SDKでは、inputやoutput指定されていないテンソルの値も全てダンプすることが可能です。最適化で消えているテンソルに対してはget_blob_dataがエラーを投げるため、exceptでcatchしています。
for i in range(0,ailia_model.get_blob_count()):
try:
data = ailia_model.get_blob_data(i)
print("Idx", i, ailia_model.get_blob_name(i), data)
except:
continue
すると、Idx.7のBlob 212からNaNになっていることがわかります。
Idx.6 211 -3.4028235e+38
Idx.7 212 [[[[nan nan nan nan nan nan]]]]
Netronで確認すると、attention_maskからのMulのBiasが-3.40e+38と、FP16では表現できない値となっており、NaNが出力されます。
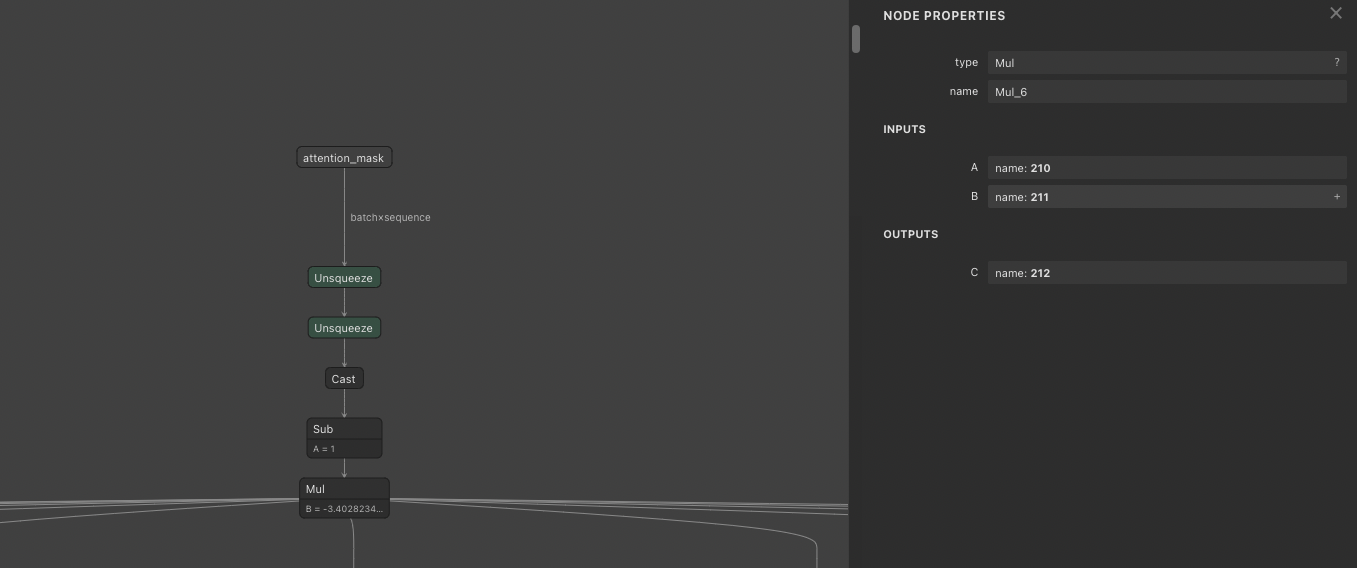
Blob 212
そこで、GithubのTransformersのIssueを確認すると、2022年1月20日の下記のPRで、昔はF-10000(-1e4)が書き込まれていたのが、FP16もしくはFP32の最大値が書き込まれるように修正されています。
これは、FP16におけるFine Tuningの精度改善のために取り込まれたようです。
元々の-10e4は、GoogleのオリジナルのBERTの実装から来ているようです。
IMO, the -10e4 comes from the original Google implementation of BERT and we just copied it everywhere. However I've now seen a couple of issues related to this.
コードの書き換え
原因がわかったので、MulのBiasがFP16に収まるようにするため、modeling_utils.pyを書き換えます。
extended_attention_mask = (1.0 - extended_attention_mask) * -1e4#torch.finfo(dtype).min
変更してExportすることで、FP16でも正しく推論できるようになりました。
FP16での推論結果
INFO bert_maskedlm.py (134) : Predictions :
INFO bert_maskedlm.py (138) : 0 の
INFO bert_maskedlm.py (138) : 1 は
INFO bert_maskedlm.py (138) : 2 [UNK]
INFO bert_maskedlm.py (138) : 3 、
INFO bert_maskedlm.py (138) : 4 (
INFO bert_maskedlm.py (140) : Script finished successfully.
まとめ
本記事では、BERTを題材に、FP16で正しい出力が得られない場合に、どのように解析し、どのように修正するかを解説しました。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。