ai-edge-torchの量子化の詳細解説
ai-edge-torchの中で量子化がどのように行われているかを解説します。
ai-edge-torchの量子化について
ai-edge-torchではtorchのグラフをpt2eで量子化した後、tfliteに変換します。torchのグラフに対して、どのように量子化が適用され、tfliteのパラメータに反映されるかを詳細に解説します。

ai-edge-torch(出展:https://developers.googleblog.com/ja/ai-edge-torch-high-performance-inference-of-pytorch-models-on-mobile-devices/)
ai-edge-torchの変換フロー
ai-edge-torchで量子化モデルを作成するスクリプトの例は下記となります。prepare_pt2eで量子化用のモデルを作成し、キャリブレーションデータで推論を実行、convert_pt2eで量子化モデルを作成、convertでtfliteに変換し、exportで保存します。
quantizer = pt2e_quantizer.PT2EQuantizer().set_global(
pt2e_quantizer.get_symmetric_quantization_config()
)
model = quantize_pt2e.prepare_pt2e(model, quantizer)
model(torch.from_numpy(img)) # calibration
model = quantize_pt2e.convert_pt2e(model, fold_quantize=False)
with_quantizer = ai_edge_torch.convert(
model,
sample_inputs,
quant_config=quant_config.QuantConfig(pt2e_quantizer=quantizer),
)
with_quantizer.export("resnet18_int8.tflite")
このスクリプトの内部で実行されるフローは、torchのpt2eの変換フローに準拠しています。torchの動的グラフに対して、prepare_pt2eを呼び出して作成した静的グラフにキャリブレーションし、convert_pt2eで量子化モデルを作成、Loweringでデバイスモデルを生成します。

pt2eの動作(出展:https://pytorch.org/tutorials/prototype/pt2e_quant_ptq.html)
torchのグラフをprepare_p2eすると、QuantizationSpecが付与されたFXグラフ(静的グラフ)が再生されます。torchは動的な計算グラフを特徴としていますが、torch FXを使用することで、動的グラフをトレースし、静的グラフに変換します。
FXグラフにキャリブレーションデータを入れて推論することで、prepare_pt2eで設定したQuantizationSpecとAnnotationに応じて、各テンソルのMin/MaxやHistogramなどのキャリブレーション情報を生成します。
pt2e_convertを呼ぶと、FXグラフがExported Program形式 に変換されます。Exported Programは下記のようなIR(中間表現)です。
ExportedProgram:
class GraphModule(torch.nn.Module):
def forward(self, p_mask_downsampler_encoder_0_weight: "f32[4, 1, 3, 3]", p_mask_downsampler_encoder_0_bias: "f32[4]", p_mask_downsampler_encoder_1_weight: "f32[4]", p_mask_downsampler_encoder_1_bias: "f32[4]", p_mask_downsampler_encoder_3_weight: "f32[16, 4, 3, 3]", p_mask_downsampler_encoder_3_bias: "f32[16]", p_mask_downsampler_encoder_4_weight: "f32[16]", p_mask_downsampler_encoder_4_bias: "f32[16]", p_mask_downsampler_encoder_6_weight: "f32[64, 16, 3, 3]", p_mask_downsampler_encoder_6_bias: "f32[64]", p_mask_downsampler_encoder_7_weight: "f32[64]", p_mask_downsampler_encoder_7_bias: "f32[64]", p_mask_downsampler_encoder_9_weight: "f32[256, 64, 3, 3]", p_mask_downsampler_encoder_9_bias: "f32[256]", p_mask_downsampler_encoder_10_weight: "f32[256]", p_mask_downsampler_encoder_10_bias: "f32[256]", p_mask_downsampler_encoder_12_weight: "f32[256, 256, 1, 1]", p_mask_downsampler_encoder_12_bias: "f32[256]", p_pix_feat_proj_weight: "f32[256, 256, 1, 1]", p_pix_feat_proj_bias: "f32[256]", p_fuser_layers_0_dwconv_weight: "f32[256, 1, 7, 7]", p_fuser_layers_0_dwconv_bias: "f32[256]", p_fuser_layers_0_norm_weight: "f32[256]", p_fuser_layers_0_norm_bias: "f32[256]", p_fuser_layers_0_pwconv1_weight: "f32[1024, 256]", p_fuser_layers_0_pwconv1_bias: "f32[1024]", p_fuser_layers_0_pwconv2_weight: "f32[256, 1024]", p_fuser_layers_0_pwconv2_bias: "f32[256]", p_fuser_layers_0_gamma: "f32[256]", p_fuser_layers_1_dwconv_weight: "f32[256, 1, 7, 7]", p_fuser_layers_1_dwconv_bias: "f32[256]", p_fuser_layers_1_norm_weight: "f32[256]", p_fuser_layers_1_norm_bias: "f32[256]", p_fuser_layers_1_pwconv1_weight: "f32[1024, 256]", p_fuser_layers_1_pwconv1_bias: "f32[1024]", p_fuser_layers_1_pwconv2_weight: "f32[256, 1024]", p_fuser_layers_1_pwconv2_bias: "f32[256]", p_fuser_layers_1_gamma: "f32[256]", p_out_proj_weight: "f32[64, 256, 1, 1]", p_out_proj_bias: "f32[64]", b_getattr_l__self_____encoder___0___scale_0__: "f32[4]", b_getattr_l__self_____encoder___0___zero_point_0__: "i64[4]", b__tensor_constant_0: "f32[]", b_getattr_l__self_____encoder___3___scale_0__: "f32[16]", b_getattr_l__self_____encoder___3___zero_point_0__: "i64[16]", b__tensor_constant_1: "f32[]", b_getattr_l__self_____encoder___6___scale_0__: "f32[64]", b_getattr_l__self_____encoder___6___zero_point_0__: "i64[64]", b__tensor_constant_2: "f32[]", b_getattr_l__self_____encoder___9___scale_0__: "f32[256]", b_getattr_l__self_____encoder___9___zero_point_0__: "i64[256]", b__tensor_constant_3: "f32[]", b_getattr_l__self_____encoder___12___scale_0__: "f32[256]", b_getattr_l__self_____encoder___12___zero_point_0__: "i64[256]", b_pix_feat_proj_scale_0: "f32[256]", b_pix_feat_proj_zero_point_0: "i64[256]", b_dwconv_scale_0: "f32[256]", b_dwconv_zero_point_0: "i64[256]", b__tensor_constant_4: "f32[]", b_pwconv1_scale_0: "f32[1024]", b_pwconv1_zero_point_0: "i64[1024]", b_pwconv2_scale_0: "f32[256]", b_pwconv2_zero_point_0: "i64[256]", b_dwconv_scale_1: "f32[256]", b_dwconv_zero_point_1: "i64[256]", b__tensor_constant_5: "f32[]", b_pwconv1_scale_1: "f32[1024]", b_pwconv1_zero_point_1: "i64[1024]", b_pwconv2_scale_1: "f32[256]", b_pwconv2_zero_point_1: "i64[256]", b_out_proj_scale_0: "f32[64]", b_out_proj_zero_point_0: "i64[64]", b__tensor_constant_6: "f32[]", b__tensor_constant_7: "f32[]", b__tensor_constant_8: "f32[]", b__tensor_constant_9: "f32[]", b__tensor_constant0: "f32[32]", pix_feat: "f32[1, 256, 32, 32]", masks: "f32[1, 1, 512, 512]"):
# File: <eval_with_key>.110:8 in forward, code: quantize_per_tensor_default = torch.ops.quantized_decomposed.quantize_per_tensor.default(arg1_1, 0.07839307934045792, 0, -128, 127, torch.int8); arg1_1 = None
quantize_per_tensor: "i8[1, 1, 512, 512]" = torch.ops.quantized_decomposed.quantize_per_tensor.default(masks, 0.07839307934045792, 0, -128, 127, torch.int8); masks = None
# File: /sam2/modeling/memory_encoder.py:58 in forward, code: return self.encoder(x)
dequantize_per_tensor: "f32[1, 1, 512, 512]" = torch.ops.quantized_decomposed.dequantize_per_tensor.default(quantize_per_tensor, 0.07839307934045792, 0, -128, 127, torch.int8); quantize_per_tensor = None
...
convertを呼ぶと、Exported Program形式からtorch_xlaを使用して、StbaleHLO形式に変換します。StableHLOはGoogleの開発したIRであり、High Level Operationsです。次に、StableHLO形式をMLIRに変換し、tfliteに変換し、TFLiteModelのインスタンスを返します。
StableHLOの概要(出展:https://github.com/openxla/stablehlo)
理論的には、Exported Porgram、SttableHLO、MLIRはIR、tfliteはLoweringされたモデルであり、等価変換されます。そのため、理論的には、量子化の精度はpt2eの段階で確定します。
torchのpt2eについて
ai-edge-torchでは、torchのpt2eを使用して量子化を行なっています。
pt2e (PyTorch 2 Export) はtorchの第二世代のモデルエクスポータです。多様なデバイスに対応するため、デバイスの制約に合わせて、量子化手法をスクリプトから柔軟に変更可能にしています。
pt2e(出展:https://pytorch.org/tutorials/prototype/pt2e_quantizer.html)
例えば、あるデバイスでは、Int8テンソルのzero_pointを0に固定しなければいけなかったり、Asymmetricの量子化ができずにSymmetricの量子化を使用しなければならなかったりします。
pt2eでは、適切に制約をQuantizationConfigとしてスクリプトで記述することで、デバイスの制約を満たした形式で量子化を可能にします。
pt2eにおいて、制約は、QuantizationSpecとAnnotationで指定します。
QuantizationSpecはテンソルに適用される制約で、zero_pointの制約や、量子化手法を定義します。
act_quantization_spec = QuantizationSpec(
dtype=torch.int8,
quant_min=-128,
quant_max=127,
qscheme=torch.per_tensor_affine,
is_dynamic=False,
observer_or_fake_quant_ctr=HistogramObserver.with_args(eps=2**-12),
)
QuantizationSpecには特別なバージョンも存在し、AveragePoolingやConcat向けに入力と出力の量子化パラメータが一致しているという制約をかけるSharedQuantizationSpecや、Convのbiasのscaleをinputとweightのscaleの乗算というような制約をかけるDerivedQuantizationSpecがあります。
Annotaionはノード(オペレータ)に適用される制約で、Convなどのノードごとに、入出力テンソルに対してQuantizationSpecを適用します。
input_qspec_map = {}
input_act0 = add_node.args[0]
input_qspec_map[input_act0] = input_act_qspec
input_act1 = add_node.args[1]
input_qspec_map[input_act1] = input_act_qspec
add_node.meta["quantization_annotation"] = QuantizationAnnotation(
input_qspec_map=input_qspec_map,
output_qspec=output_act_qspec,
_annotated=True,
)
Annotationはパターンマッチで適用され、パターンマッチしたノードに量子化が適用されます。AnnotationされなかったノードはFloatのままになります。
add_partitions = get_source_partitions(gm.graph, [operator.add, torch.add])
add_partitions = list(itertools.chain(*add_partitions.values()))
for add_partition in add_partitions:
add_node = add_partition.output_nodes[0]
# add_nodeへのquantization_annotationの設定
ai-edge-torchのAnnotation
ai-edge-torchでは下記のコードでノードごとのAnnotationが定義されています。この例では、ノードのオペレータがtorch.ops.aten.conv2d.defaultと一致した場合に、入出力テンソルや、ウエイト、バイアスに対してQuantizationSpecで制約をかけています。Annotationの結果、LoweringでQとDQが含まれたIRが出力されます。
@register_annotator("conv")
def _annotate_conv(
gm: torch.fx.GraphModule,
quantization_config: Optional[QuantizationConfig],
filter_fn: Optional[Callable[[Node], bool]] = None,
) -> Optional[List[List[Node]]]:
annotated_partitions = []
for n in gm.graph.nodes:
if n.op != "call_function" or n.target not in [
torch.ops.aten.conv1d.default,
torch.ops.aten.conv2d.default,
torch.ops.aten.convolution.default,
]:
continue
conv_node = n
input_qspec_map = {}
input_act = conv_node.args[0]
assert isinstance(input_act, Node)
input_qspec_map[input_act] = get_input_act_qspec(quantization_config)
weight = conv_node.args[1]
assert isinstance(weight, Node)
input_qspec_map[weight] = get_weight_qspec(quantization_config)
# adding weight node to the partition as well
partition = [conv_node, conv_node.args[1]]
bias = conv_node.args[2] if len(conv_node.args) > 2 else None
if isinstance(bias, Node):
input_qspec_map[bias] = get_bias_qspec(quantization_config)
partition.append(bias)
if _is_annotated(partition):
continue
if filter_fn and any(not filter_fn(n) for n in partition):
continue
conv_node.meta["quantization_annotation"] = QuantizationAnnotation(
input_qspec_map=input_qspec_map,
output_qspec=get_output_act_qspec(quantization_config),
_annotated=True,
)
_mark_nodes_as_annotated(partition)
annotated_partitions.append(partition)
return annotated_partitions
FXグラフのノードは下記のメンバを持ちます。targetにノードのオペレータが、argsにノードへの入力が入ります。
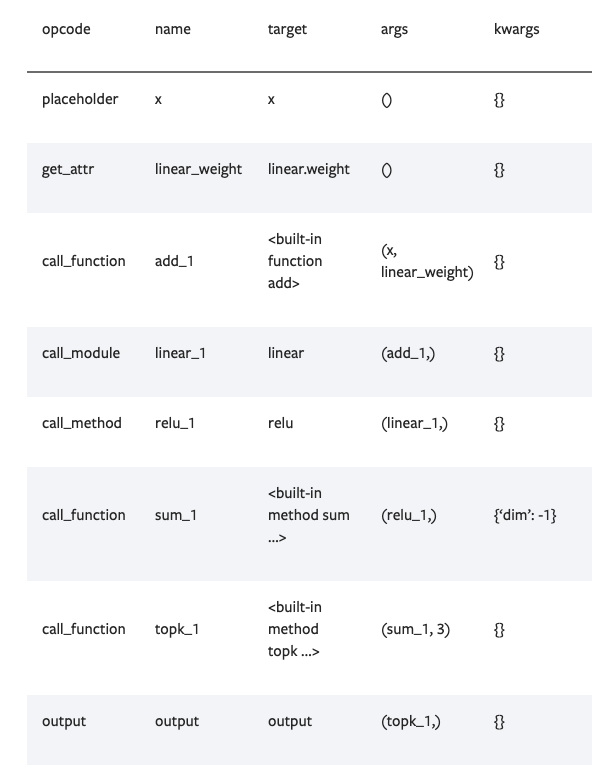
出典:https://pytorch.org/docs/stable/fx.html
Annotationは、ai-edge-torchのprepare_pt2eの引数に与えるPT2EQuantizerの中のannoate関数で実行されます。そのため、prepare_pt2eを呼び出した以降で、Annotationを参照することが可能です。
def annotate(self, model: torch.fx.GraphModule) -> torch.fx.GraphModule:
"""just handling global spec for now"""
if self.global_config and not self.global_config.input_activation: # type: ignore[union-attr]
model = self._annotate_for_dynamic_quantization_config(model)
else:
model = self._annotate_for_static_quantization_config(model)
propagate_annotation(model)
return model
def _annotate_all_static_patterns(
self,
model: torch.fx.GraphModule,
quantization_config: Optional[QuantizationConfig],
filter_fn: Optional[Callable[[Node], bool]] = None,
) -> torch.fx.GraphModule:
if quantization_config is None:
return model
if quantization_config.is_qat:
for op in self.STATIC_QAT_ONLY_OPS:
OP_TO_ANNOTATOR[op](model, quantization_config, filter_fn)
for op in self.STATIC_OPS:
OP_TO_ANNOTATOR[op](model, quantization_config, filter_fn)
return model
ai-edge-torchのLowering
LoweringはIRからデバイスのモデル形式に変換します。ai-edge-torchではconvertが呼ばれた際、下記のコードで、Exported ProgramからStableHLOに変換し、TensorFlowのIRであるMLIRに変換しています。
def exported_program_to_mlir(
exported_program: torch.export.ExportedProgram,
sample_args: tuple[torch.Tensor],
) -> stablehlo.StableHLOModelBundle:
# Setting export_weights to False here so that pytorch/xla avoids copying the
# weights to a numpy array which would lead to memory bloat. This means that
# the state_dict in the returned bundle is going to be empty.
return stablehlo.exported_program_to_stablehlo(
exported_program,
stablehlo.StableHLOExportOptions(
override_tracing_arguments=sample_args, export_weights=False
),
)._bundle
ai-edge-torchの量子化モデルの返り値は、TfLiteModelになります。Exported Program形式は推論できないため、TfLiteModelを返すことで推論をできるようにしています。
exported_programs = list(map(_run_convert_passes, exported_programs))
tflite_model = lowertools.exported_programs_to_tflite(
exported_programs,
signatures,
quant_config=quant_config,
_tfl_converter_flags=_tfl_converter_flags,
_saved_model_dir=_saved_model_dir,
)
return model.TfLiteModel(tflite_model)
ai-edge-torchのグラフ最適化
グラフ最適化は、convertが呼ばれた際、StableHLOに変換する前のFXグラフの段階で行われます。lowertoolsの呼び出し前に、_run_convert_passesが呼ばれ、下記の最適化が実行されます。
passes = [
fx_passes.BuildInterpolateCompositePass(),
fx_passes.CanonicalizePass(),
fx_passes.OptimizeLayoutTransposesPass(),
fx_passes.CanonicalizePass(),
fx_passes.BuildAtenCompositePass(),
fx_passes.CanonicalizePass(),
fx_passes.RemoveNonUserOutputsPass(),
fx_passes.CanonicalizePass(),
]
# Debuginfo is not injected automatically by odml_torch. Only inject
# debuginfo via fx pass when using torch_xla.
if ai_edge_torch.config.use_torch_xla:
passes += [
fx_passes.InjectMlirDebuginfoPass(),
fx_passes.CanonicalizePass(),
]
OptimizerLayoutTransposesPassでは、GREEDYもしくはMINCUTのアルゴリズムで、各ノードがNHWCが必須かどうかを判定し、必要に応じてTransposeを挿入します。MINCUTの場合、一つのテンソルを複数のノードが参照している場合に、より適切な位置にTransposeを挿入します。デフォルトはMINCUTで、動作モードはAIEDGETORCH_LAYOUT_OPTIMIZE_PARTITIONER環境変数で設定可能です。
ai-edge-torchの応用
特定のレイヤーの量子化設定を変更する
ai-edge-torchで定義されているPT2EQuantizerのannotate関数が呼ばれることで、FXグラフのn.meta[“quantization_annotation”]にAnnotationが設定されます。このAnnotationのinput_qspec_mapを書き換えることで、特定のレイヤーの量子化を行わないようにすることが可能です。
下記のように、PT2EQuantizerを継承したPT2EQuantizer2を作成します。annotate関数をオーバロードし、ノードがConv2Dの場合に、floatのQuantizationSpecを作成し、quantization_annotationの入力ノードに設定しています。
class PT2EQuantizer2(pt2e_quantizer.PT2EQuantizer):
def annotate(self, model: torch.fx.GraphModule) -> torch.fx.GraphModule:
super().annotate(model)
for n in model.graph.nodes:
if n.target in [torch.ops.aten.conv2d.default]:
if "quantization_annotation" in n.meta:
print(n.target)
print("Before")
print(n.meta["quantization_annotation"])
from torch.ao.quantization.quantizer import QuantizationSpec
from torch.ao.quantization.observer import PlaceholderObserver
act_observer_or_fake_quant_ctr = PlaceholderObserver
float_spec = QuantizationSpec(dtype=torch.float32,
observer_or_fake_quant_ctr=act_observer_or_fake_quant_ctr.with_args(
eps=2**-12
),)
for key in n.meta["quantization_annotation"].input_qspec_map:
n.meta["quantization_annotation"].input_qspec_map[key] = float_spec
#n.meta["quantization_annotation"].output_qspec = float_spec
print("After")
print(n.meta["quantization_annotation"])
return model
quantizer = PT2EQuantizer2().set_global(
pt2e_quantizer.get_symmetric_quantization_config()
)
Conv2Dの変更前と変更後のQuantizationAnnotationです。
aten.conv2d.default
Before
QuantizationAnnotation(input_qspec_map={arg1_1: QuantizationSpec(dtype=torch.int8, observer_or_fake_quant_ctr=functools.partial(<class 'torch.ao.quantization.observer.HistogramObserver'>, eps=0.000244140625){}, quant_min=-128, quant_max=127, qscheme=torch.per_tensor_affine, ch_axis=None, is_dynamic=False), _param_constant0: QuantizationSpec(dtype=torch.int8, observer_or_fake_quant_ctr=functools.partial(<class 'torch.ao.quantization.observer.PerChannelMinMaxObserver'>, eps=0.000244140625){}, quant_min=-127, quant_max=127, qscheme=torch.per_channel_symmetric, ch_axis=0, is_dynamic=False), _param_constant1: None}, output_qspec=QuantizationSpec(dtype=torch.int8, observer_or_fake_quant_ctr=functools.partial(<class 'torch.ao.quantization.observer.HistogramObserver'>, eps=0.000244140625){}, quant_min=-128, quant_max=127, qscheme=torch.per_tensor_affine, ch_axis=None, is_dynamic=False), allow_implicit_sharing=True, _annotated=True)
After
QuantizationAnnotation(input_qspec_map={arg1_1: QuantizationSpec(dtype=torch.float32, observer_or_fake_quant_ctr=functools.partial(<class 'torch.ao.quantization.observer.PlaceholderObserver'>, eps=0.000244140625){}, quant_min=None, quant_max=None, qscheme=None, ch_axis=None, is_dynamic=False), _param_constant0: QuantizationSpec(dtype=torch.float32, observer_or_fake_quant_ctr=functools.partial(<class 'torch.ao.quantization.observer.PlaceholderObserver'>, eps=0.000244140625){}, quant_min=None, quant_max=None, qscheme=None, ch_axis=None, is_dynamic=False), _param_constant1: QuantizationSpec(dtype=torch.float32, observer_or_fake_quant_ctr=functools.partial(<class 'torch.ao.quantization.observer.PlaceholderObserver'>, eps=0.000244140625){}, quant_min=None, quant_max=None, qscheme=None, ch_axis=None, is_dynamic=False)}, output_qspec=QuantizationSpec(dtype=torch.int8, observer_or_fake_quant_ctr=functools.partial(<class 'torch.ao.quantization.observer.HistogramObserver'>, eps=0.000244140625){}, quant_min=-128, quant_max=127, qscheme=torch.per_tensor_affine, ch_axis=None, is_dynamic=False), allow_implicit_sharing=True, _annotated=True)
通常はConvはInt8で出力されます。
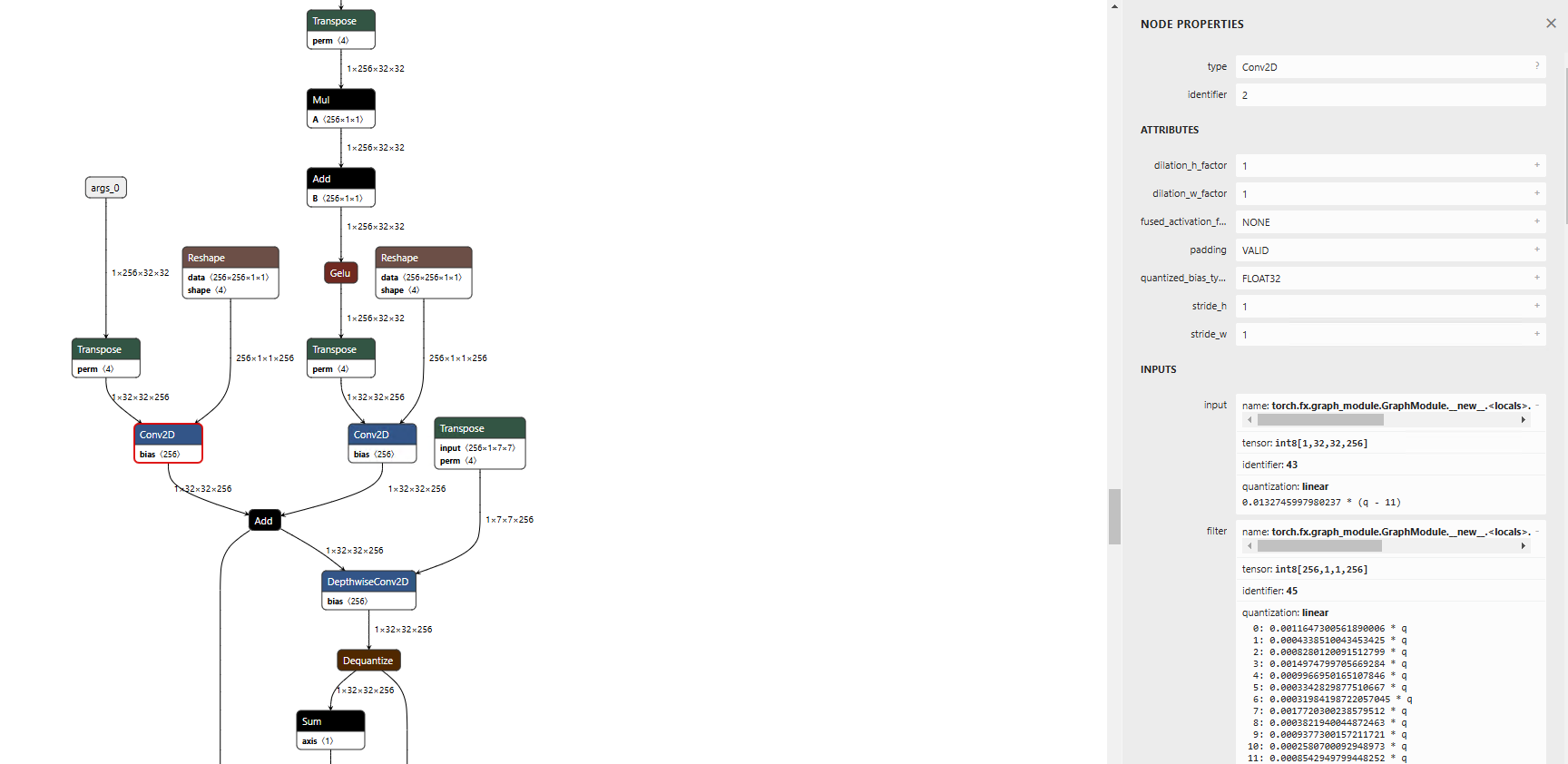
通常のエクスポート
quantization_annotationを書き換えるとConvはFloatで出力されます。

ConvにFloatのAnnotationを指定したエクスポート
この例では、Convの後のレイヤーはInt8で動作させることを想定しているため、output_qspecはInt8のままにしていますが、後段のレイヤーをFloatで動作させたい場合は、output_qspecにもfloat_specを代入してください。
n.meta["quantization_annotation"].output_qspec = float_spec
TransposeConvをInt8で実行する
ai-edge-torchでは、TransposeConvにAnnotationされていないため、Floatで処理されます。Int8で処理したい場合は、torch.ops.aten.conv_transpose2d.inputのinputに対して、Annotationを適用します。
import ai_edge_torch
from ai_edge_torch.quantize import pt2e_quantizer
from ai_edge_torch.quantize import quant_config
from torch.ao.quantization import quantize_pt2e
from ai_edge_torch.quantize.pt2e_quantizer_utils import get_input_act_qspec, get_weight_qspec, get_bias_qspec, get_output_act_qspec
from torch.ao.quantization.quantizer import QuantizationAnnotation
quantization_config = pt2e_quantizer.get_symmetric_quantization_config(is_dynamic=False, is_per_channel=False)
class PT2EQuantizer2(pt2e_quantizer.PT2EQuantizer):
def annotate(self, model: torch.fx.GraphModule) -> torch.fx.GraphModule:
super().annotate(model)
for n in model.graph.nodes:
if n.target in [torch.ops.aten.conv_transpose2d.input]:
input_qspec_map = {}
input_qspec_map[n.args[0]] = get_input_act_qspec(quantization_config)
# weightにも制約をかけるとうまくint8に変換できなくなるため、inputにだけ制約をかける
#input_qspec_map[n.args[1]] = get_weight_qspec(quantization_config)
#input_qspec_map[n.args[2]] = get_bias_qspec(quantization_config)
n.meta["quantization_annotation"] = QuantizationAnnotation(
input_qspec_map=input_qspec_map,
output_qspec=get_output_act_qspec(quantization_config),
_annotated=True,
)
return model
quantizer = PT2EQuantizer2().set_global(
quantization_config
)
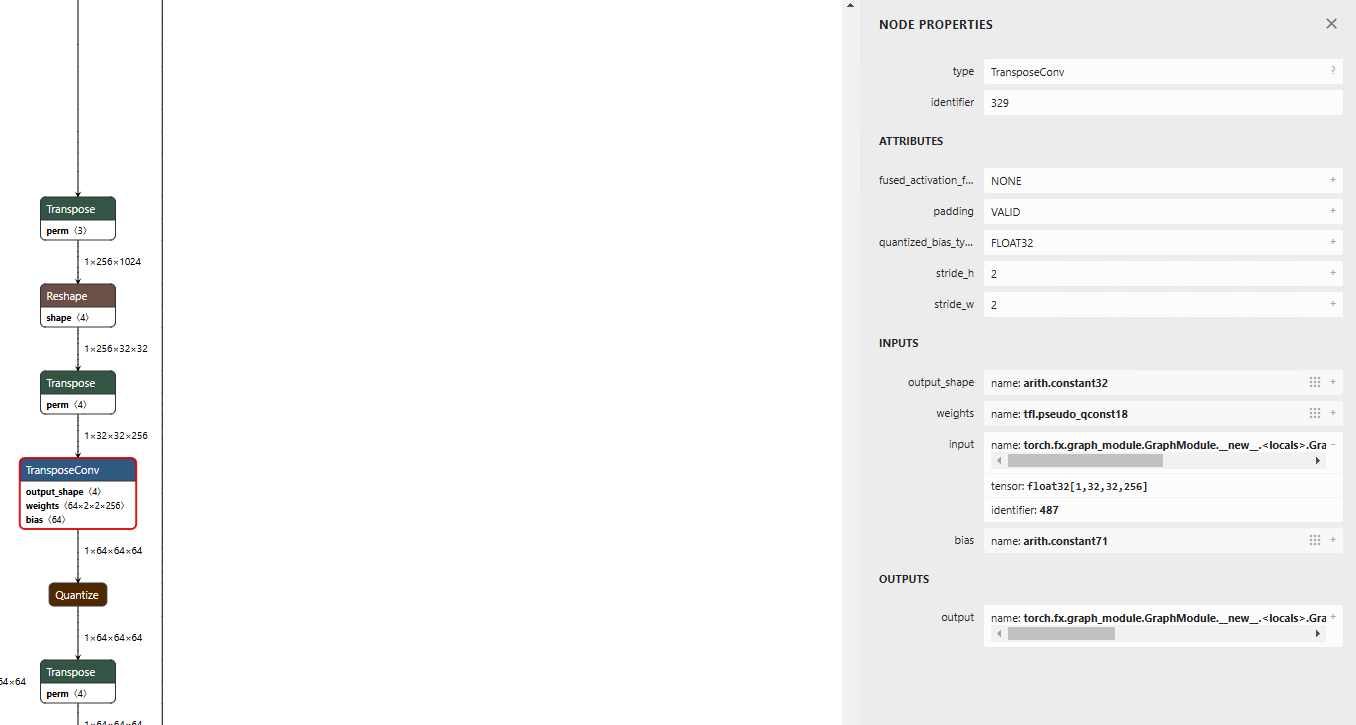
通常のエクスポート

Int8のアノテーションを行ったエクスポート
複数のレイヤーの量子化係数を共通化する
複数のレイヤーで同じ量子化係数を使用するには、SharedQuantizationSpecを使用します。共有元となるレイヤーからSharedQuantizationSpecを作成し、SharedQuantizationSpecを共有先となるレイヤーのoutput_qspecに与えることで、共通のObserverを使用して量子化を行うことが可能です。
class PT2EQuantizer2(pt2e_quantizer.PT2EQuantizer):
def __init__(self):
super().__init__()
def annotate(self, model: torch.fx.GraphModule) -> torch.fx.GraphModule:
super().annotate(model)
n_cnt = 0
observer = None
for n in model.graph.nodes:
if n.target in [torch.ops.aten.conv2d.default]:
if "quantization_annotation" in n.meta:
if n_cnt == 0:
observer = SharedQuantizationSpec((n))
if n_cnt == 1:
n.meta["quantization_annotation"].output_qspec = observer
n_cnt = n_cnt + 1
return model
モデルの出力をInt8にする
モデルのoutputに接続されるレイヤーがAnnotationされていない場合、モデルの出力がFloatになります。モデルの出力をInt8にしたい場合、outputに接続されている入力レイヤーを探索し、Annotationを付与します。
quantization_config = pt2e_quantizer.get_symmetric_quantization_config(is_dynamic=False, is_per_channel=True)
class PT2EQuantizer2(pt2e_quantizer.PT2EQuantizer):
def annotate(self, model: torch.fx.GraphModule) -> torch.fx.GraphModule:
super().annotate(model)
target_node = None
for n in model.graph.nodes:
if str(n.target) == "output":
target_node = n.args[0][0]
for n in model.graph.nodes:
if n == target_node:
input_qspec_map = {}
input_qspec_map[n.args[0]] = get_input_act_qspec(quantization_config)
n.meta["quantization_annotation"] = QuantizationAnnotation(
input_qspec_map=input_qspec_map,
output_qspec=get_output_act_qspec(quantization_config),
_annotated=True,
)
return model
FXグラフのノードのargsは、通常、 (input1, input2)の形式ですが、オペレータがoutputやaten.concat.defaultの場合のみ特殊で、([input1, input2], param)の形式で格納されます。そのため、n.args[0]ではなく、n.args[0][0]でoutputに対する入力ノードを参照しています。
入力テンソルにInt64やBoolを与える
モデルの入力テンソルがInt64やBoolの場合、量子化でdtypeのエラーが発生することがあります。
torch._dynamo.exc.TorchRuntimeError: Failed running call_function quantized_decomposed.quantize_per_tensor.default(*(FakeTensor(..., size=(1, 128), dtype=torch.bool), 0.003919653594493866, -128, -128, 127, torch.int8), **{}):
Expecting input to have dtype torch.float32, but got dtype: torch.bool
これは、入力テンソルがconcatなど、量子化されるタイプに接続された場合に、入力テンソルを量子化しようとするためです。この問題を回避するには、Int64やBoolなどの入力テンソルの接続先のノードの量子化を無効にする必要があります。
どのノードが原因かを調査するには、Exported Programを確認したり、annotateでノード情報を確認したりします。
model = quantize_pt2e.convert_pt2e(model, fold_quantize=False)
print(model)
class PT2EQuantizer2(pt2e_quantizer.PT2EQuantizer):
def __init__(self, quantization_config):
super().__init__()
self.quantization_config = quantization_config
def annotate(self, model: torch.fx.GraphModule) -> torch.fx.GraphModule:
super().annotate(model)
for n in model.graph.nodes:
print(n.target, n.name, n.args, "quantization_annotation" in n.meta)
問題のノードが特定できたら、そのノードに対して、量子化を無効にします。
class PT2EQuantizer2(pt2e_quantizer.PT2EQuantizer):
def __init__(self, quantization_config):
super().__init__()
self.quantization_config = quantization_config
def annotate(self, model: torch.fx.GraphModule) -> torch.fx.GraphModule:
super().annotate(model)
for n in model.graph.nodes:
if n.target in [torch.ops.aten.cat.default]:
if "quantization_annotation" in n.meta:
if str(n.args[0][1]) == "arg5_1":
act_observer_or_fake_quant_ctr = PlaceholderObserver
float_spec = QuantizationSpec(dtype=torch.float32,
observer_or_fake_quant_ctr=act_observer_or_fake_quant_ctr.with_args(
eps=2**-12
),)
for key in n.meta["quantization_annotation"].input_qspec_map:
n.meta["quantization_annotation"].input_qspec_map[key] = float_spec
まとめ
ai-edge-torchは、torchの動的グラフから、torch FXの静的グラフ、Exported Program、StableHLO、MLIR、tfliteというパスを通って量子化されることを紹介しました。壮大なフローですが、IRは等価変換であるという原則で考えると、量子化の精度はtorch FXの静的グラフに対するAnnotationと、QuantizationSpecに依存することがわかります。内部構造を理解することで、より深い最適化の余地があるものと考えています。
アイリア株式会社はAIを実用化する会社として、クロスプラットフォームでGPUを使用した高速な推論を行うことができるailia SDKを開発しています。アイリア株式会社ではコンサルティングからモデル作成、SDKの提供、AIを利用したアプリ・システム開発、サポートまで、 AIに関するトータルソリューションを提供していますのでお気軽にお問い合わせください。
AIで、しごとするなら『ailia.ai(アイリア ドット エーアイ)』は、AIの開発を行う企業、株式会社アクセルおよびアイリア株式会社が展開するAI専門メディアです。ビジネスやライフスタイルを取り巻く最新のAI関連製品やサービスを深く読み解くとともに、ailiaブランドが展開する最新のサービスや、AIの活用・開発・導入を加速させるための情報を幅広く網羅。
近い未来、AIが私たちにもたらすであろう“本質的な自由“について、さまざまな角度から情報を発信します。